




画像生成AI「Stable Diffusion」などの開発に大きな貢献を果たした超巨大データセット「LAION-5B」とは?

AIを構築する上ではアルゴリズムだけでなく訓練用のデータセットも重要であり、データセットの質によってAIの精度も大きく左右されます。高精度な画像生成AIとして話題のStable Diffusionでは、「LAION-5B」という50億以上もの画像とテキストのペアを含むデータセットを用いています。
LAION-5B: A NEW ERA OF OPEN LARGE-SCALE MULTI-MODAL DATASETS | LAION
https://laion.ai/blog/laion-5b/
大規模な機械学習モデルやデータセット、関連コードなどの一般公開を掲げる「Large-scale Artificial Intelligence Open Network(LAION)」というドイツの非営利団体は、2022年3月に超巨大なデータセットである「LAION-5B」をリリースしました。LAION-5Bの作成にあたり、機械学習コミュニティのHugging Face、AI開発企業のdoodlebot、Stable Diffusionを開発したStability.aiがコンピューティングリソースの提供を行っています。
LAION-5Bは画像分類モデルのCLIPでフィルタリングされた58億5000万もの画像とテキストの組み合わせで構成され、このうち23億組が画像と英語テキストのペアで、22億組が画像と100を超える非英語テキストのペア、残り10億組が画像と特定の言語に限定されない名前などのテキストのペアです。なお、日本語のデータセットも1億3000万組ほど含まれているとのこと。LAIONの研究チームはリリース時に公開した文章で、数十億の画像とテキストのペアでトレーニングされた大規模画像テキストモデルは高いパフォーマンスを示すものの、この規模のトレーニング用データセットは一般利用できなかったと指摘。この問題に対処するため、LAIONは大規模な画像とテキストのペアのデータセットを作成・公開することにしたそうです。
LAIONは、「データセット作成の背景にある動機は、大規模なマルチモーダルモデルのトレーニングと、公開されているインターネットからクロールされたキュレーションされていない大規模なデータセットの処理に関する研究と実験を民主化することです」「このデータセットは、これまで独自の大規模データセットにアクセスできる人に限定されていた言語ビジョンモデルの多言語大規模トレーニングと研究の可能性を、幅広いコミュニティに拡大します」と述べています。
画像とテキストのペアを作成するにあたり、LAIONはインターネット上のデータを提供するコモン・クロールのファイルを解析し、テキストと画像のペアを選択して、CLIPを用いて類似性の高い画像とテキストのペアを抽出しました。さらに短すぎるテキスト、解像度が大きすぎる画像、重複データ、違法コンテンツなどを可能な限り削除して、最終的に58億5000万の画像とテキストのペアからなるサンプルが残ったとのこと。
LAIONはデータセットとして使用する際の快適性を向上するために、ダウンロード用のライブラリや探索およびサブセット作成用のウェブインターフェース、検索ツールなどを用意したほか、透かしの入った画像やNSFWデータを除外するタグも設置しました。LAIONは、「透かし入りの画像は、DALL-EやGLIDEなどの画像生成モデルをトレーニングする時に大きな問題になります。この問題に取り組むために、透かし検出モデルをトレーニングし、それを使用してLAION-5Bのすべての画像の信頼度スコアを計算しました」と述べています。
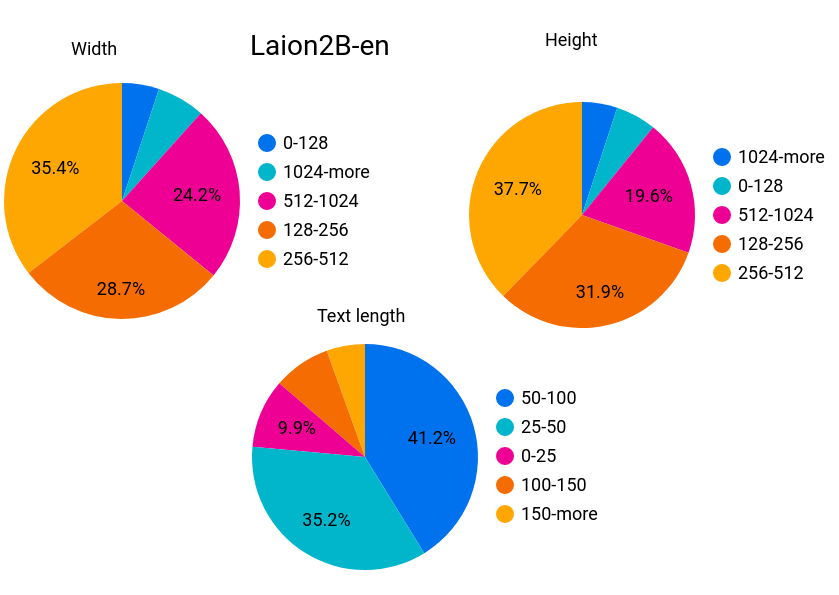
LAION-5Bに含まれるデータのうち、英語のデータセットについて「Width(画像の横幅)」「Height(画像の縦幅)」「Text length(テキストの文字数)」の割合を示したものが以下。画像の横幅と縦幅は128~1024ピクセルが80%以上を占めており、テキストの文字数は100文字以下が80%以上であることがわかります。また、安全でないデータの割合は2.9%、透かしの入った画像の割合は6.1%とのこと。
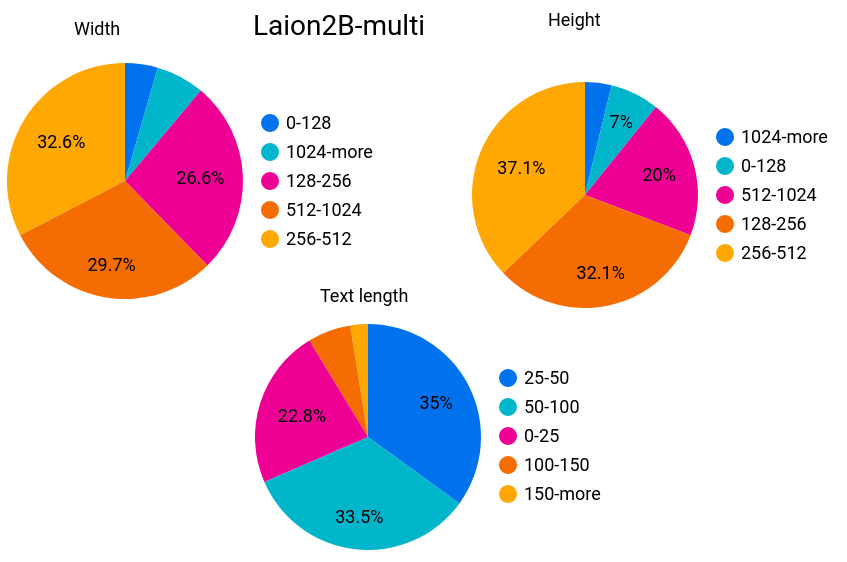
非英語のデータセットについて、同様に「画像の横幅」「画像の縦幅」「テキストの文字数」を表した以下のグラフを見ると、多少の差はあれど全体的な傾向は似ていることがわかります。こちらのデータセットでは、安全でないデータの割合は3.3%、透かしの入った画像の割合は5.6%でした。
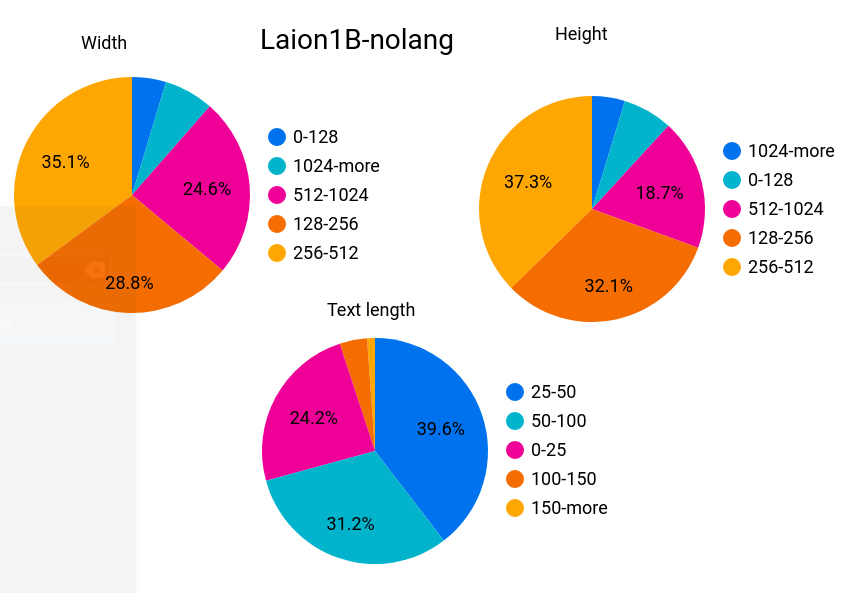
言語で分類できないデータセットのグラフは以下。安全でないデータの割合は3%、透かしの入った画像の割合は4%となっています。なお、データセットは「クリエイティブコモンズ BY 4.0」ライセンスで無料公開されていますが、画像は著作権で保護されているとLAIONは述べています。
LAIONはLAION-5Bの注意点として、キュレーションされていないデータセットという性質上、不快なコンテンツを含んでいる可能性があると警告しています。安全タグに基づいてある程度は不快なコンテンツを除外できるものの、その後も潜在的に有害なコンテンツに遭遇する可能性があるとのことで、「このリリースで奨励したい大規模モデルの一般的な特性や安全性に関する基礎研究はまだ進行中であるため、すぐに使用できる商業製品の作成に使用することは推奨しません」と述べています。
リリースの後、LAION-5BはStable Diffusionの開発にも利用されるなどAI業界に大きく貢献しましたが、データセットにどこかから流出した医療用画像が含まれているといった問題も指摘されています。また、自身の作品がデータセットに使われているかどうかを検索できる「Have I Been Trained?」というツールも登場しています。
画像生成AIに自分の作品が勝手に使われたかどうかを検索できる「Have I Been Trained?」 - GIGAZINE
・関連記事
23億枚もの画像で構成された画像生成AI「Stable Diffusion」のデータセットのうち1200万枚がどこから入手した画像かを調査した結果が公開される - GIGAZINE
画像生成AIに自分の作品が勝手に使われたかどうかを検索できる「Have I Been Trained?」 - GIGAZINE
画像生成AIユーザーがAI学習用データセットから「自分の医療記録の写真」を発見してしまう - GIGAZINE
「Stable Diffusion」のような画像生成AIに自分の顔写真が使われている可能性は決して低くないとの警告 - GIGAZINE
画像生成AI「Stable Diffusion」のバージョン2.0が登場、出力画像の解像度が拡大&デジタル透かしを入れられる機能も - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by log1h_ik
You can read the machine translated English article What is the super huge data set 'LAION-5….