Salesforce releases open source dataset 'MINT-1T' containing 1 trillion text tokens, 3.4 billion images, PDFs, ArXiv papers, and more

GitHub - mlfoundations/MINT-1T: MINT-1T: A one trillion token multimodal interleaved dataset.
https://github.com/mlfoundations/MINT-1T
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
https://blog.salesforceairesearch.com/mint-1t/
Breaking news! ➡️➡️➡️ We just released the MINT-1T 🍃dataset! One trillion tokens. Multimodal. Interleaved. Open-source. Perfect for training multimodal models and advancing their pre-training. Try it today!
— Salesforce AI Research (@SFResearch) July 24, 2024
Blog: https://t.co/e36YvEBrcP
Dataset: https://t.co/FHKhkAURdN pic.twitter.com/guqup91SBW
The development of AI requires datasets containing huge amounts of text and images, and the release of high-quality datasets as open source would be a major benefit to the advancement of the AI field.
Salesforce AI Research has recently released a multimodal dataset called 'MINT-1T' as open source. MINT-1T contains 1 trillion text tokens and 3.4 billion images, as well as data that has not been used in previous datasets, such as PDFs and papers from the preprint server ArXiv.
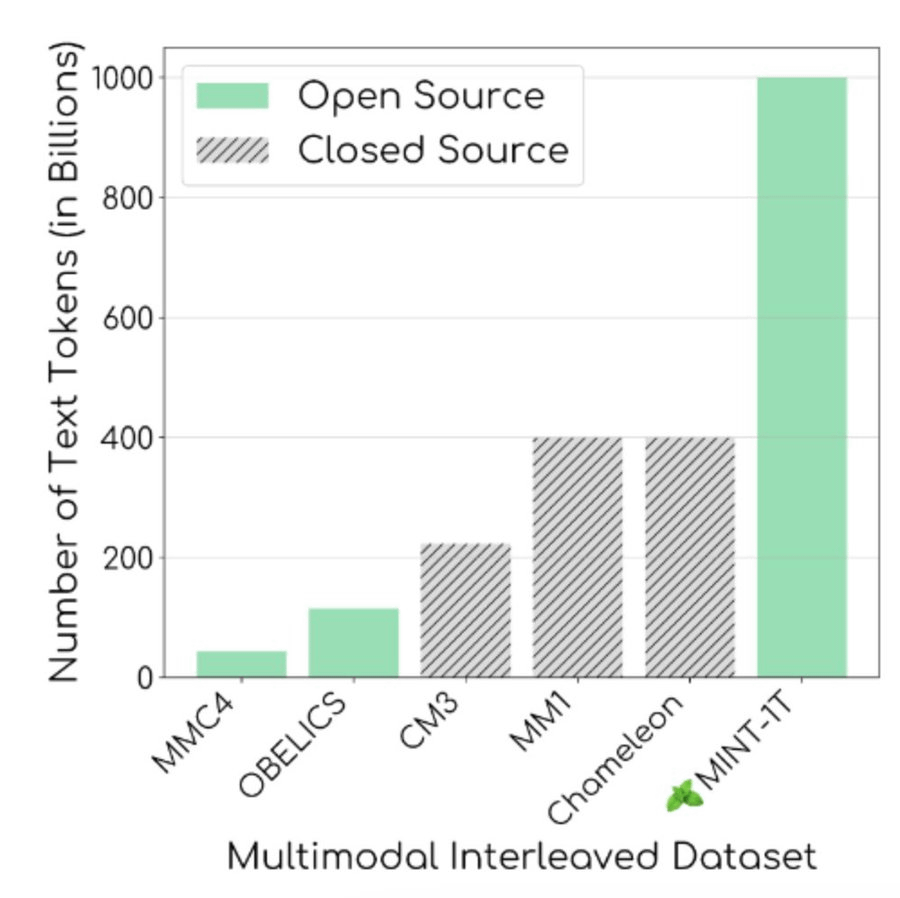
As the figure below shows, previous open source datasets such as OBELICS and MMC4 have a maximum of 115 billion tokens, while MINT-1T has a significantly larger token count.
Below is a sample of documents included in MINT-1T. You can see that the text is written alongside the images, and various graphs and heat maps are also included. Salesforce AI Research said, 'The main principles of MINT-1T curation are scale and diversity.' 'To improve the diversity of MINT-1T, we go beyond HTML documents to include PDFs from the web and ArXiv papers. We found that these additional sources improve domain coverage, especially for scientific documents.'

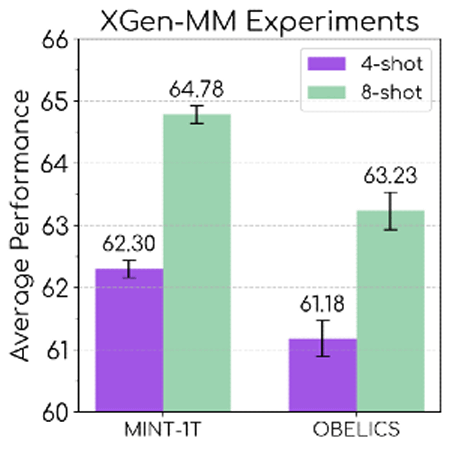
The graph below compares the performance of XGen-MM , an AI model developed by Salesforce AI Research, when trained on MINT-1T (left) and OBELICS (right). It can be seen that training on MINT-1T results in better overall performance.
Related Posts:








in AI, Software, Web Service, Posted by log1h_ik