




AIを開発するために必要なデータが急速に枯渇、たった1年で高品質データの4分の1が使用不可に

AIの開発にはインターネットからかき集めたテキスト、画像、動画などのデータが大量に用いられています。しかし、クローリングの禁止やサービス利用規約の変更によりAI企業がウェブサイトから閉め出されたことで、高性能なAIのトレーニングに使えるデータの総量が1年で約5%、高品質なデータの約25%が使えなくなったことがわかりました。
Data Provenance Initiative
https://www.dataprovenance.org/consent-in-crisis-paper
Data for A.I. Training Is Disappearing Fast, Study Shows - The New York Times
https://www.nytimes.com/2024/07/19/technology/ai-data-restrictions.html
AIモデルのデータセットの監査を行っている団体・Data Provenance Initiativeは、広く使用されている3つのAIトレーニング用データセット「C4」「RefinedWeb」「Dolma」に含まれている1万4000件のウェブドメインを調査し、クローリングで得られるデータとその使用に関する同意状況の変化を調べました。
その結果、2023年から2024年にかけてのたった1年で各サイトによるデータ制限が急増していることがわかりました。
以下は調査結果のグラフで、上がクローラーにアクセスを許可するURLを記述する「Robots.txt」、下がサービス利用規約「Terms of service(ToS)」によるアクセス制限の状況を示しています。特に、Robots.txtでの制限はOpenAIのクローラーである「GPTBot」の導入を境に急増しています。
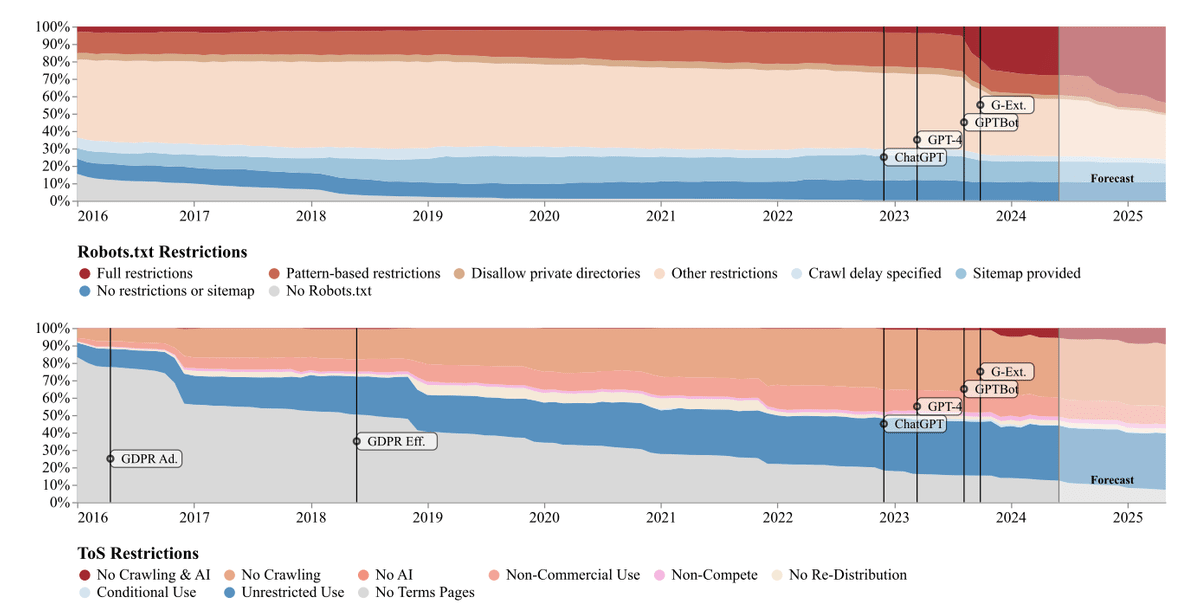
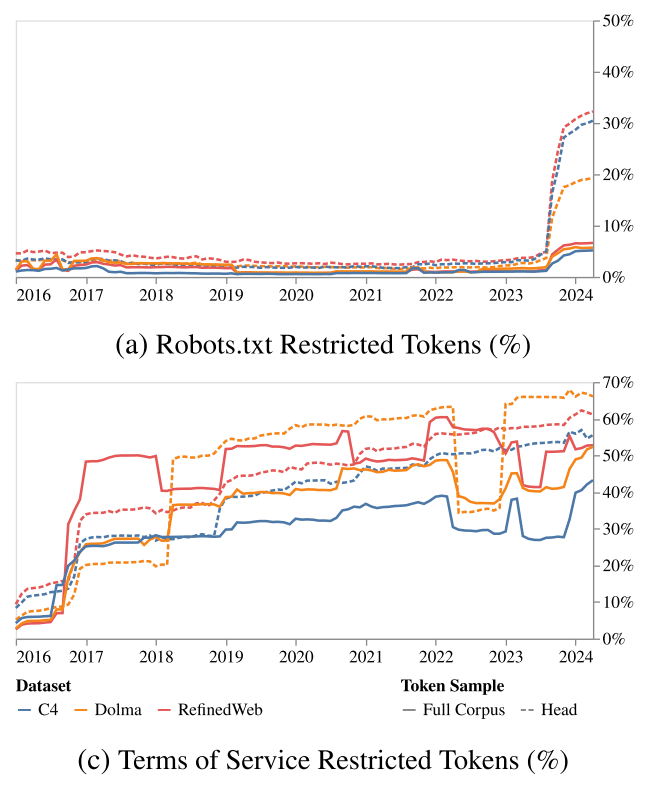
制限の増加によりAIのトレーニングに使えないデータも急増しました。具体的には、コーパス全体におけるトークンの制限は2023年中旬の約1%から2024年4月には5~7%に、最も重要なデータ「HEAD」の制限は3%未満から20~33%に増加し、C4とRefinedWebにおけるコーパス全体の相対的な制限の増加量は500%、HEADでは1000%以上に達しているとのこと。特にC4では、サービス利用規約によりトークンの45%が制限されました。
研究論文の筆頭著者であるシェイン・ロングプレ氏は「ウェブ上でのデータ利用に対する同意率が急速に低下しており、これはAI企業だけでなく研究者や学者、非営利団体にも影響を及ぼすでしょう」と話しました。
生成AIはデータを基本的な構成要素としており、OpenAIのChatGPT、GoogleのGemini、AnthropicのClaudeなどのAIはすべて大量のデータセットを使ってトレーニングされたものです。
長年にわたり、AI開発者は容易にデータを集めることができましたが、生成AIが流行したことでAI開発者とデータの所有者との対立が表面化するようになりました。その結果、データの所有者らはデータをトレーニングに使うことを禁止したり、有料化してデータの使用に対価を求めたりするようになりました。
OpenAIがインターネット上のコンテンツ収集に用いるウェブクローラー「GPTBot」をブロックする試みが進行中 - GIGAZINE

AI業界や関係者はこうした変化に警戒感を強めています。また、中には「既に多くのデータを所有している大手テクノロジー企業と後進の小規模な企業や研究者との間のデータ格差が拡大するだけではないか」と指摘する人も居ます。
AIプラットフォームを提供しているHugging Faceの機械学習研究者であるYacine Jernite氏は「データ作成者がオンラインで共有したテキスト、画像、動画が商業システムの開発に使用され、しばしば彼らの生活を直接脅かす事態にもなっているので、データ作成者から反発が起きるのは当然です。しかし、AIの学習に使うデータをすべてライセンス契約で入手する必要があるとなると、市井の研究者や市民がテクノロジーのガバナンスから排除されることにもなりかねません」と話しました。
また、非営利のAI研究機関・EleutherAIのエグゼクティブディレクターであるステラ・ビーダーマン氏は「大手テクノロジー企業は既に大量のデータを持っており、データのライセンスを変更してもさかのぼって許可を取り消すことはできません。ですから、影響を受けるのは主に後からやってきた小規模なスタートアップや研究者になるでしょう」と話しました。
・関連記事
2026年までにAIのトレーニングに使うデータが枯渇する「データ不足問題」とは? - GIGAZINE
MetaがAI強化のため「訴えられてもいいから著作権で保護された作品をかき集めよう」と議論していたとの報道 - GIGAZINE
Slackがユーザーの明示的な許可なくメッセージなどをAIトレーニングに利用していることが判明 - GIGAZINE
AIの需要増加によりデータセンターの消費電力が爆増してAI開発のボトルネックになっている - GIGAZINE
Appleがニュース記事で生成AIをトレーニングするためさまざまなメディアと5000万ドル以上の複数年契約について話し合ったことが発覚 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article Data needed to develop AI is rapidly dry….