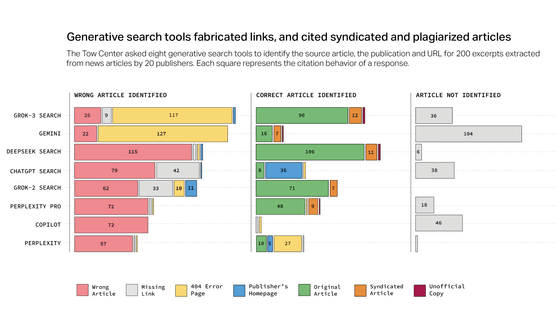
Data needed to develop AI is rapidly drying up, with a quarter of high-quality data becoming unusable in just one year

AI development uses a large amount of data, such as text, images, and videos, collected from the Internet. However, as AI companies were banned from websites due to crawling bans and changes to the terms of service, it was found that about 5% of the total data available for training high-performance AI and about 25% of high-quality data became unusable in one year.
Data Provenance Initiative
Data for AI Training Is Disappearing Fast, Study Shows - The New York Times
https://www.nytimes.com/2024/07/19/technology/ai-data-restrictions.html
The Data Provenance Initiative, an organization that audits datasets for AI models, looked at 14,000 web domains in three widely used AI training datasets, C4, RefinedWeb, and Dolma, to examine changes in the data collected and consent status for their use.
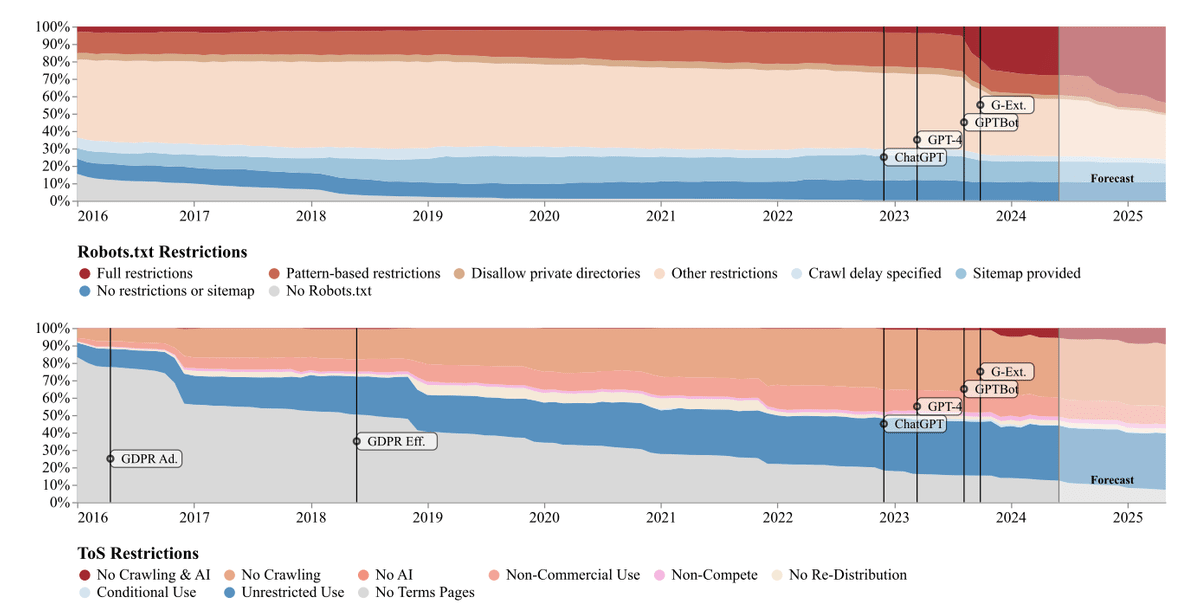
As a result, we found that data restrictions imposed by each site increased sharply in just one year from 2023 to 2024.
The graph below shows the results of the survey. The top graph shows the status of access restrictions by 'Robots.txt', which describes the URLs that the crawler is allowed to access, and the bottom graph shows the status of access restrictions by the terms of service 'Terms of service (ToS)'. In particular, restrictions by Robots.txt have increased sharply since the introduction of OpenAI's crawler 'GPTBot'.
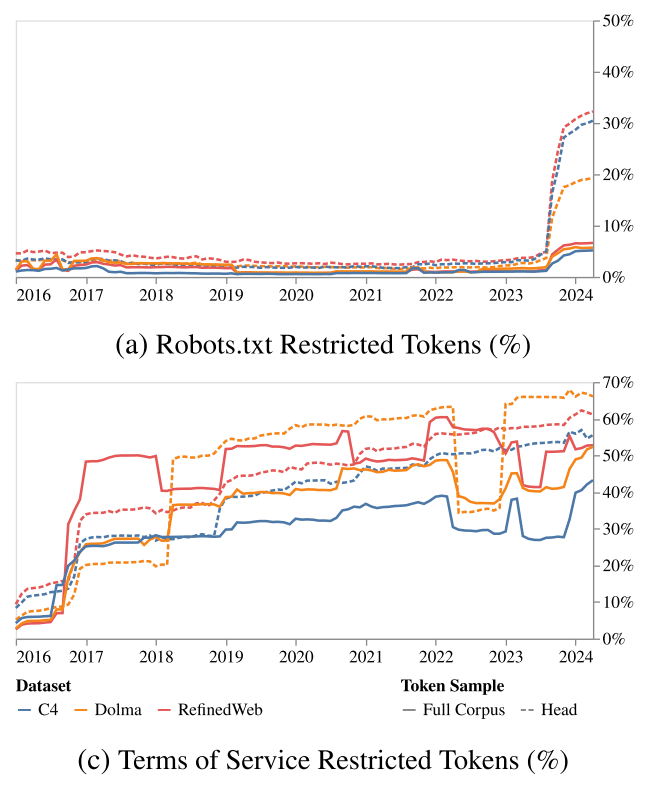
The increase in restrictions has also led to a sharp increase in data that cannot be used for AI training. Specifically, the token limit for the entire
'Consent to use of data on the web is declining rapidly, and this will have implications not only for AI companies but also for researchers, academics, and non-profits,' said Shane Longpre, lead author of the study.
Generative AI has data as its fundamental building block, and AI like OpenAI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude have all been trained on massive datasets.
For many years, AI developers have been able to easily collect data, but the popularity of generative AI has brought conflicts to the surface between AI developers and data owners, who have begun to prohibit the use of their data for training or to charge for the use of their data.
Attempts underway to block the web crawler 'GPTBot' used by OpenAI to collect content on the Internet - GIGAZINE

Those in the AI industry and related parties are growing increasingly wary of these changes, with some pointing out that this will only widen the data gap between the large technology companies that already have a lot of data and the smaller companies and researchers who are less advanced.
'It's only natural that data creators would push back, as the text, images and videos they share online are being used to develop commercial systems that often directly threaten their livelihoods,' said Yacine Jernite, a machine learning researcher at Hugging Face, an AI platform provider. 'But if all data used to train AI must be obtained under a license agreement, it could mean that ordinary researchers and citizens are excluded from the governance of technology.'
Stella Biedermann, executive director of the nonprofit AI research institute EleutherAI, said, 'Big tech companies already have a lot of data, and they can't retroactively revoke permissions by changing the license for that data. So it's going to be mostly smaller startups and researchers who are coming in later.'
Related Posts: