OpenAI is forced to change its strategy as AI evolution hits a plateau, and the problem of high-quality data shortages becomes rapidly apparent

Since its release in 2022, OpenAI's ChatGPT has amazed AI users with its rapid evolution, but it has been reported that progress is slowing due to scaling issues, including a lack of high-quality data needed to train the model.
OpenAI Shifts Strategy as Rate of 'GPT' AI Improvements Slows — The Information
What if AI doesn't just keep getting better forever? - Ars Technica
https://arstechnica.com/ai/2024/11/what-if-ai-doesnt-just-keep-getting-better-forever/
AI can improve its accuracy by training it with high-quality data, but training requires a large amount of data, and high-quality data in particular is expected to run out as early as 2026. In addition, as websites accelerate their efforts to ban crawling by AI companies, the problem of data shortages is becoming more and more serious, with a quarter of high-quality data becoming unusable in just one year.
Data needed to develop AI is rapidly depleting, with a quarter of high-quality data becoming unusable in just one year - GIGAZINE

According to an internal OpenAI researcher who provided information to technology industry magazine The Information, OpenAI's next-generation model, codenamed ' Orion ,' is not expected to deliver the same significant performance improvements seen when upgrading from GPT-3 to GPT-4.
As a result, Orion 'is not necessarily better than its predecessor at any particular task,' the anonymous internal researcher said.
This view may have been pervasive among OpenAI's upper echelons for some time: OpenAI co-founder Ilya Satskever, who left the company in early 2024, said in an interview that the company had reached a plateau in the progress it made by scaling up 'pre-training,' a foundational training technique that uses large amounts of data.
'The 2010s was the era of scaling. Now we're back in the era of wonder and discovery, and everyone is looking for the next thing, so scaling the right things is more important than ever,' Satskivar told Reuters.

There are various bottlenecks preventing the progress of AI, including the hardware and power constraints required to run the models, but one that is particularly problematic is the lack of new, high-quality text data.
From their results, the researchers concluded that 'language models will exhaust most of the stock of public human-created text between 2026 and 2032.'
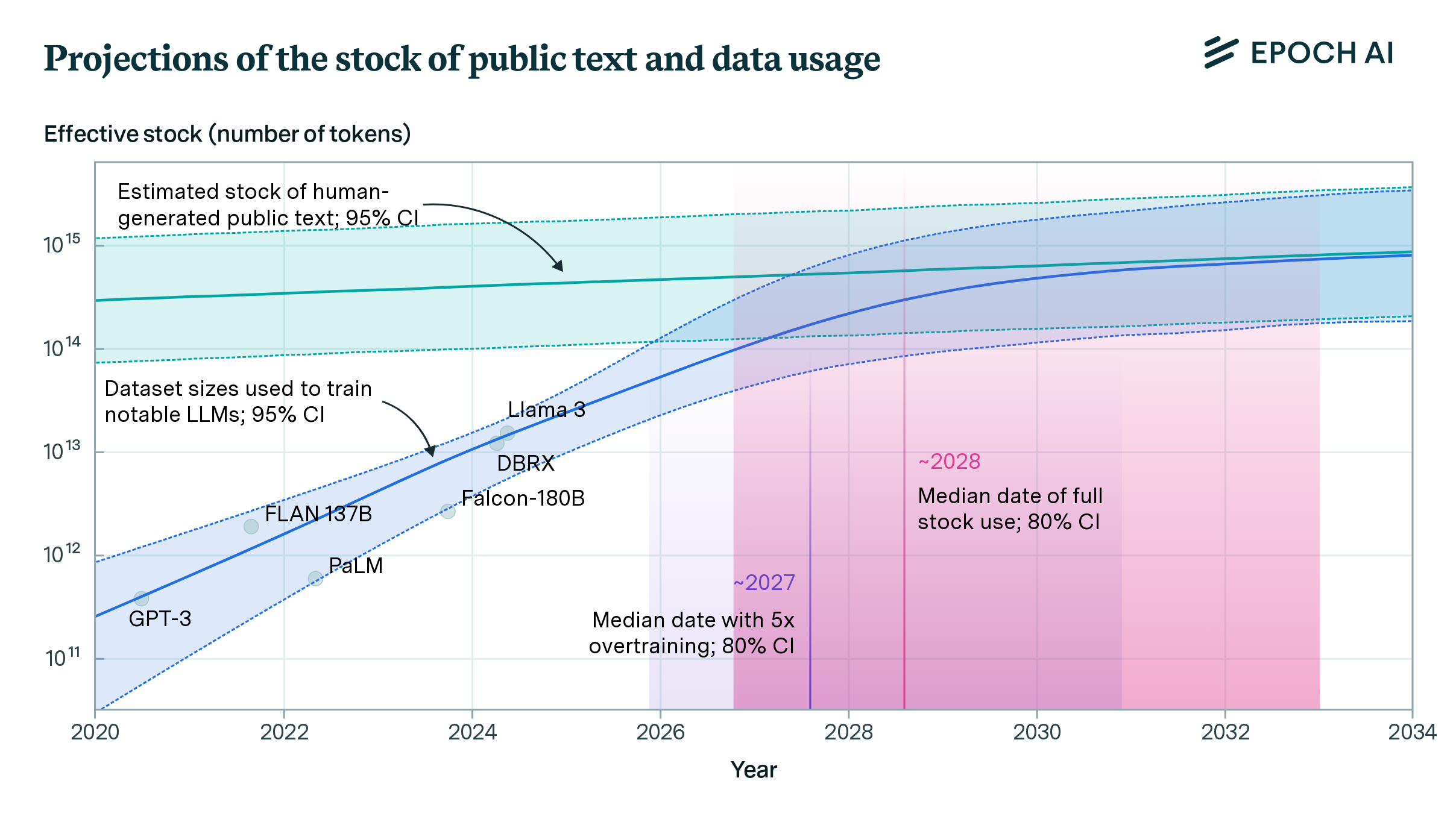
To address the looming data shortage, OpenAI and other AI companies are turning to techniques that use 'synthetic data' created by other models for training.
However, some argue that repeated cycles of recursive training on this kind of data could lead to “model collapse,” in which the LLM loses its ability to understand context.
And while some are pinning their hopes on improving AI models by improving their inference capabilities rather than training them on new data, research shows that even state-of-the-art inference models are easily fooled by deliberately misleading questions.
Ars Technica, an IT news site that covered The Information's report, said, 'If the current LLM training methodology reaches a dead end, the next breakthrough may come from specialization. Microsoft has already achieved some success with models that are specialized for specific tasks or problems, so-called small language models (SLMs). This means that unlike the generalist LLMs of the past, AI in the near future may be more specialized and focused on more targeted areas.'
Related Posts:







