




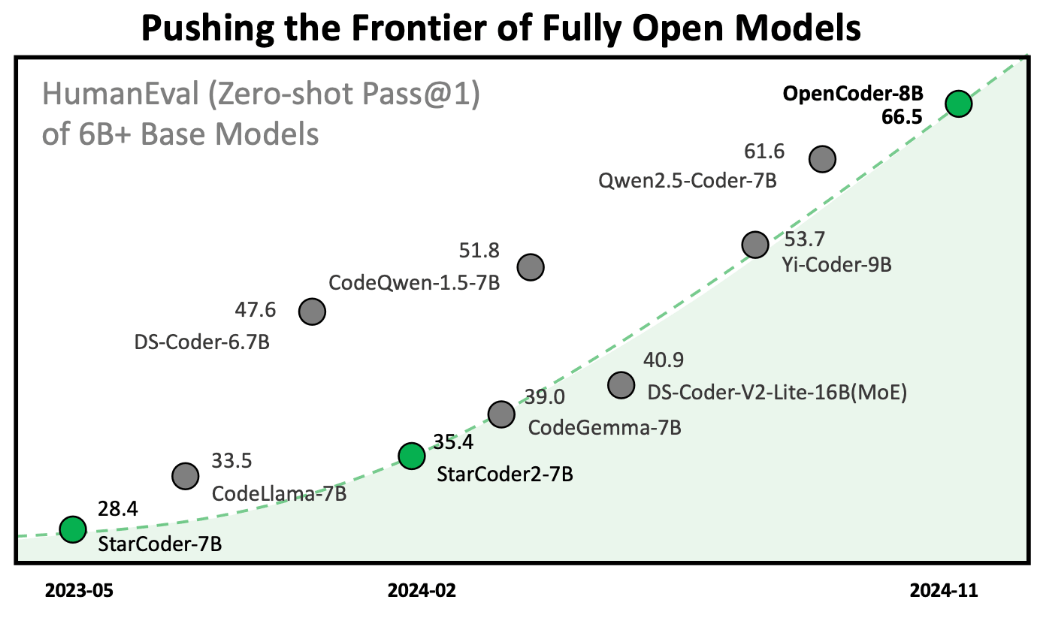
完全にオープンで再現可能な大規模言語モデル「OpenCoder」がリリースされる

上海のAI企業「INF Technology」やオープンソースのAI研究コミュニティ「M-A-P」などに在籍する研究者のチームにより、最終モデルだけでなくトレーニングデータやデータ処理パイプラインなど、モデルを再現するのに必要な情報全てがオープンな大規模言語モデル「OpenCoder」が公開されました。
OpenCoder: Top-Tier Open Code Large Language Models
https://opencoder-llm.github.io/

大規模言語モデルについて「オープンなモデル」と言う場合、どの程度オープンなのかについてはさまざまです。モデルのアーキテクチャが公開されていて誰でも独自のデータで大規模言語モデルをトレーニングできる場合を「オープンソース」、トレーニング済みのモデルが公開されていて誰でも自分のローカルPCで実行できる場合を「オープンウェイト」、トレーニングに使用したデータが公開されていて誰でもトレーニングを再現できる場合を「オープンデータ」と言いますが、OpenCoderは全てを公開している「完全にオープンなモデル」です。

・関連記事
「オープンソース」を称するAIモデルは実際どのくらいオープンなのか? - GIGAZINE
NVIDIAがオープンモデル「Nemotron-4 340B」を発表、LLMトレーニング用合成データの生成に革命を起こすか - GIGAZINE
OpenAIが言語モデルの事実性を測定するベンチマーク「SimpleQA」をオープンソースでリリース - GIGAZINE
MITからスピンオフした「Liquid AI」が非トランスフォーマーAIモデル「LFM 1B・3B・40B MoE」をリリース - GIGAZINE
オープンソースAIを定義する「OSAID」のバージョン1.0が公開、MetaのLlamaはオープンソースAIに合致せず - GIGAZINE
・関連コンテンツ







in 無料メンバー, AI, ソフトウェア, Posted by log1d_ts
You can read the machine translated English article OpenCoder, a completely open and reprodu….