




NVIDIAがオープンモデル「Nemotron-4 340B」を発表、LLMトレーニング用合成データの生成に革命を起こすか

高度なAIのトレーニングには高品質な学習データが欠かせませんが、そのようなデータは急速に枯渇しつつあることが問題となっています。NVIDIA2024年6月14日に、大規模言語モデル(LLM)のトレーニングに使用する合成データの生成を念頭に開発され、商用アプリケーションにも使えるオープンソースのAIモデル「Nemotron-4 340B」を発表しました。
NVIDIA Releases Open Synthetic Data Generation Pipeline for Training Large Language Models | NVIDIA Blog
https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
Nvidia's 'Nemotron-4 340B' model redefines synthetic data generation, rivals GPT-4 | VentureBeat
https://venturebeat.com/ai/nvidias-nemotron-4-340b-model-redefines-synthetic-data-generation-rivals-gpt-4/
Nemotron-4 340Bは、合成データ生成パイプラインとして使用できるBaseモデル、Instructモデル、Rewardモデルの3つで構成されており、オープンソースの学習フレームワークであるNVIDIA NeMoでの動作や、高速推論向けツールのNVIDIA TensorRT-LLMライブラリでの使用に最適化されています。
また、Nemotron-4 340Bはオープンモデルでありながら9兆のトークンと4000のコンテキストウィンドウを誇り、50を超える自然言語と40以上のプログラミング言語に対応していることから、パフォーマンスでMetaのLlama3-70BやAnthropicのClaude 3 Sonnetをしのぎ、GPT-4に匹敵するだろうと、IT系ニュースサイトのVentureBeatは評価しました。
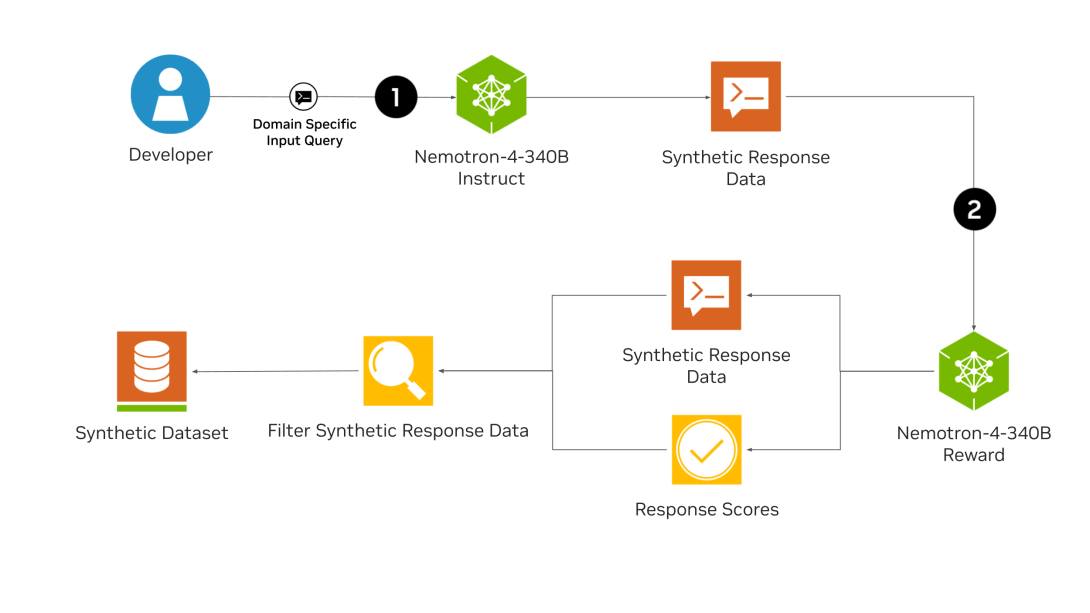
以下は、Nemotron-4 340Bを使用した合成データ生成パイプラインです。まず、Nemotron-4 340B Instructモデルが多様かつ実戦的な合成データを生成します。そして、それを評価モデルであるNemotron-4 340B Rewardが「有用性」「正確性」「一貫性」「複雑性」「冗長性」の5属性で評価し、反復的な改善や正確性の検証を行います。
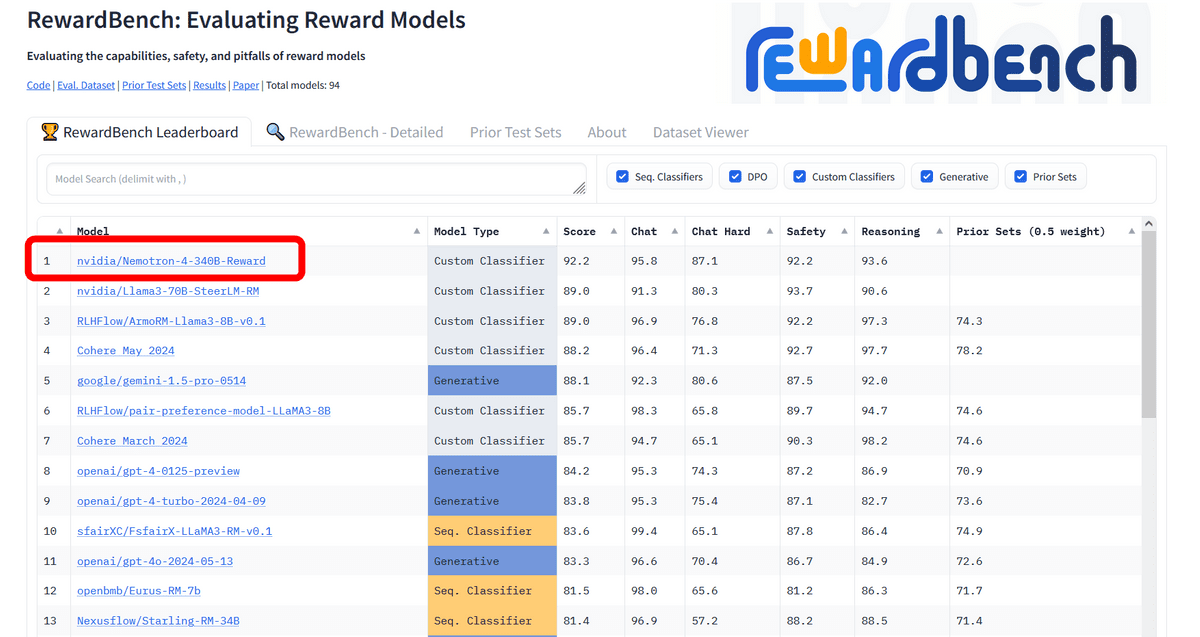
Nemotron-4 340B Rewardは、報酬モデルのランキングで1位を獲得しています。
Nemotron-4 340BはすでにHugging Faceで公開されているほか、NVIDIAの公式サイト(ai.nvidia.com)でも間もなくアクセスできるようになるとのこと。
LMSYS OrgのChatbot ArenaでNemotron-4 340Bを触ったユーザーからのフィードバックは圧倒的に好評価で、特に性能の高さと専門知識の量を称賛する声が多く寄せられています。
VentureBeatは、「NVIDIAは、LLMをトレーニングする合成データの生成に革命をもたらす『Nemotron-4 340B』のリリースにより、押しも押されもしないAIイノベーションのリーダーとしての地位を改めて確固たるものにしました」と述べました。
・関連記事
2026年までにAIのトレーニングに使うデータが枯渇する「データ不足問題」とは? - GIGAZINE
ネット上に驚くほど多くの機械翻訳コンテンツがあふれることで言語モデルのトレーニングに影響が出る可能性 - GIGAZINE
Metaの大規模言語モデル「LLaMA」のトレーニングにも使用されたAIの学習用データセット「Books3」が削除される - GIGAZINE
Microsoftが独自の大規模言語モデル「MAI-1」を開発中との報道、Google・OpenAI・AnthropicのAIモデルと競合可能なレベルとも - GIGAZINE
無料で商用利用もOKな完全オープンソースの大規模言語モデルを開発するプロジェクト「RedPajama」がトレーニングデータセットを公開 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article NVIDIA Announces Open Model 'Nemotron-4 ….