




ネット上に驚くほど多くの機械翻訳コンテンツがあふれることで言語モデルのトレーニングに影響が出る可能性

AIは膨大な量のデータを学習することによって成り立っています。データの多くはネットで収集されていますが、マイナー言語だと機械的に翻訳された情報が大量に出回っている状態で、言語モデルのトレーニングに懸念があることを研究者が指摘しています。
[2401.05749] A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism
https://arxiv.org/abs/2401.05749
A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism
https://arxiv.org/html/2401.05749v1

AWS AIラボのブライアン・トンプソン氏らは、機械翻訳がウェブに与えた影響を調査しました。
無料の機械翻訳がネット上で使用できるようになったのは1997年後半からで、ほぼ同時期に、トレーニングデータのスクレイピングが始まっています。
ウェブ上のコンテンツは複数の言語に翻訳されることがありますが、機械翻訳で並列的に複数言語に翻訳されると品質が下がることがわかっています。
以下は、縦軸が翻訳の評価スコア、横軸が翻訳された言語の数を表しています。翻訳される言語が増えるほど品質が低下していることがわかるとともに、機械翻訳の普及率が高くなっていることを示唆しています。
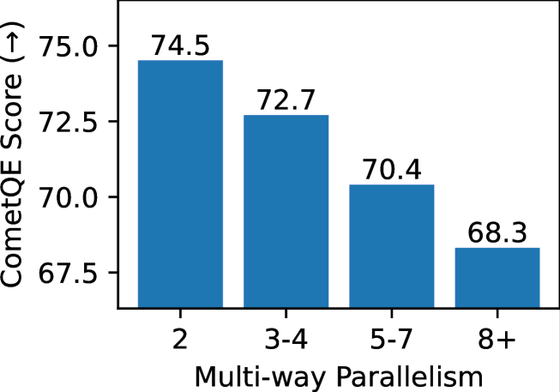
英語のようなメジャーな言語はネット上に人間が生み出したコンテンツ(リソース)が大量に存在するため、スクレイピングしても、品質の低いデータが紛れ込む割合は低くなります。
しかし、ネット上にコンテンツが少ない低リソース言語の場合、機械翻訳で生み出されたものが当該言語コンテンツの大半を占めてしまうことになります。
また、言語モデルをトレーニングするにあたってデータセットの内容には偏りがないことが求められますが、機械翻訳で生成されたコンテンツの内容は、選択バイアスがかかっていることもわかっています。これは、広告収入目当てに生成された、低品質な英語コンテンツを機械翻訳によって複数言語にまとめて翻訳したためであることが示唆されています。

低品質なコンテンツが増えると、そのコンテンツを学習して行われる機械翻訳において翻訳精度や文章の流暢性が低下し、より多くの「幻覚」を伴う流暢性の低いモデルの生成につながるとのことで、トンプソン氏らは、ウェブから収集した単言語データと二言語データで多言語の大規模言語モデルのトレーニングを行うことについて、深刻な懸念が引き起こされていると述べました。
・関連記事
300以上の言語で訓練されたGoogleの翻訳AI「Universal Speech Model(USM)」の最新情報が公開、将来的に1000以上の言語を翻訳可能にする計画 - GIGAZINE
ついにYouTubeがAIによる「自動翻訳吹き替え」機能を搭載へ - GIGAZINE
Googleがニューラル機械翻訳の弱点を克服すべくAdversarial Examplesを取り入れたモデルを開発 - GIGAZINE
機械翻訳は海外貿易にどのような影響を与えているのか? - GIGAZINE
機械翻訳はWikipediaの翻訳ツールとしていまだに問題があり、Wikipedia自体の信頼性を低下させている - GIGAZINE
・関連コンテンツ






in メモ, Posted by logc_nt
You can read the machine translated English article The surprising amount of machine transla….