The surprising amount of machine translated content on the internet may affect language model training

AI is built on learning from vast amounts of data. Much of the data is collected online, but researchers have pointed out that there are concerns about the training of language models, as there is a large amount of mechanically translated information available in minor languages.
[2401.05749] A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism
A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism
https://arxiv.org/html/2401.05749v1

Brian Thompson and colleagues at AWS AI Lab investigated the impact machine translation has had on the web.
Free machine translation became available online in late 1997, and training data scraping began around the same time.
Content on the web is sometimes translated into multiple languages, but it has been found that the quality decreases when machine translation is translated into multiple languages in parallel.
Below, the vertical axis represents the translation evaluation score, and the horizontal axis represents the number of translated languages. It shows that the quality decreases as the number of languages translated increases, and it also suggests that the penetration rate of machine translation is increasing.
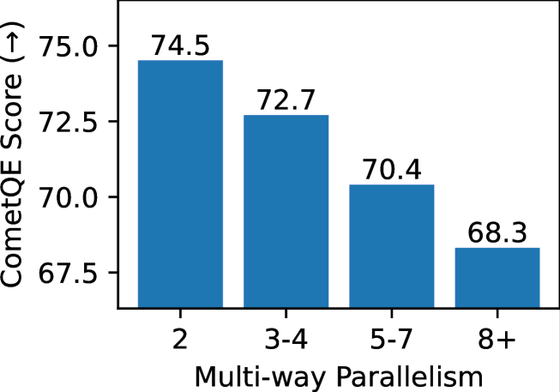
For major languages like English, there is a large amount of content (resources) created by humans on the internet, so even if you scrape it, the rate of low-quality data getting mixed in is low.
However, in the case of low-resource languages with little content on the internet, the majority of the language content will be created through machine translation.
Furthermore, while training a language model requires that the content of the dataset be unbiased, it is known that the content generated by machine translation is subject to selection bias. It has been suggested that this is because low-quality English content generated for advertising revenue was translated into multiple languages using machine translation.

As the amount of low-quality content increases, translation accuracy and sentence fluency decrease in machine translation performed by learning that content, leading to the generation of models with low fluency that have more 'hallucinations'. , Thompson and colleagues said that training large-scale, multilingual language models with monolingual and bilingual data collected from the web raises serious concerns.
Related Posts:






in Note, Posted by logc_nt