




300以上の言語で訓練されたGoogleの翻訳AI「Universal Speech Model(USM)」の最新情報が公開、将来的に1000以上の言語を翻訳可能にする計画

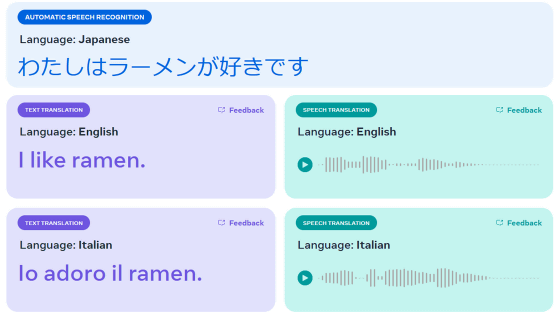
機械学習によって翻訳ソフトウェアの性能は飛躍的に進歩していますが、地球上に存在する言語の中には話者が少なく、学習に必要なデータが不十分なものもあります。新たにGoogleが、YouTubeの字幕生成に利用される大規模言語モデル「Universal Speech Model(USM)」を300以上の言語でトレーニングし、比較的マイナーな言語を含む翻訳タスクで非常に優れた性能を発揮したことを報告しました。
Universal Speech Model
https://sites.research.google/usm/
Universal Speech Model (USM): State-of-the-art speech AI for 100+ languages – Google AI Blog
https://ai.googleblog.com/2023/03/universal-speech-model-usm-state-of-art.html
Google’s one step closer to building its 1,000-language AI model - The Verge
https://www.theverge.com/2023/3/6/23627788/google-1000-language-ai-universal-speech-model
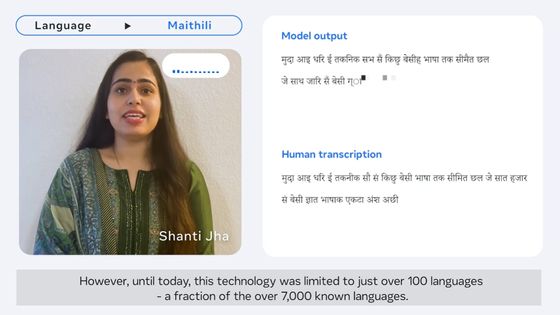
Googleは2022年11月に、1000もの言語に対応するAIモデルを構築するという野心的な取り組み「1000 Languages Initiative」を発表しました。この取り組みにおける課題となっているのが、機械学習のトレーニングに利用可能なデータセットが少ない話者が少ない言語をどうサポートするのかという点です。
従来の教師あり学習では、時間とコストをかけてデータセットに人力でラベルを付与するか、既存の文字起こしデータを収集する必要がありました。しかし、話者の比較的少ない言語では高品質のデータを収集することが難しく、拡張性に欠けるという問題があります。
そこでGoogleは、YouTubeでクローズドキャプション(ユーザーが表示/非表示を切り替えられる字幕)の生成に利用されているUSMを、自己教師あり学習という手法を用いてトレーニングしたと報告しました。自己教師あり学習とは、人間によるラベルが付与されていないデータから疑似的なラベルを自動生成する手法であり、文字起こしされていない音声のみのデータをトレーニングに利用することが可能です。
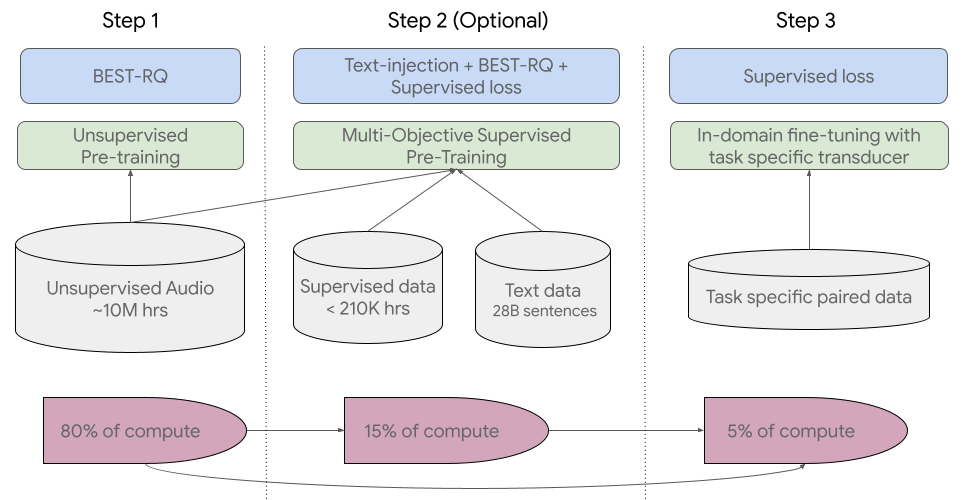
USMではトレーニングの80%を占める第1ステップで「BEST-RQ」という自己教師あり学習を実行し、15%を占める第2ステップでテキストデータを追加した事前トレーニングを通じてモデルの品質を向上させ、5%を占める第3ステップでは下流タスク(ターゲットタスク)を行ってモデルを微調整したとのこと。Googleは、「ラベルのない大規模な多言語データセットを利用してモデルのエンコーダーを事前学習し、より少ないラベル付きデータセットで微調整を行うことで、これらのマイナーな言語を認識できることを実証しました。さらに、このモデルの学習プロセスは、新しい言語やデータへの適応にも有効です」と述べています。
USMは300以上の言語にまたがる1200万時間の音声データと280億文のテキストでトレーニングされ、20億のパラメーターを持つ最先端の音声認識AIだとGoogleは述べています。USMは英語や北京語といった広く話されている言語に加え、マダガスカル語・ルオ語・ソガ語・アッサム語・サンタル語・バリ語・ショナ語・ニャンコレ語など、トレーニングデータの収集が難しい言語でも自動音声認識が可能だそうです。
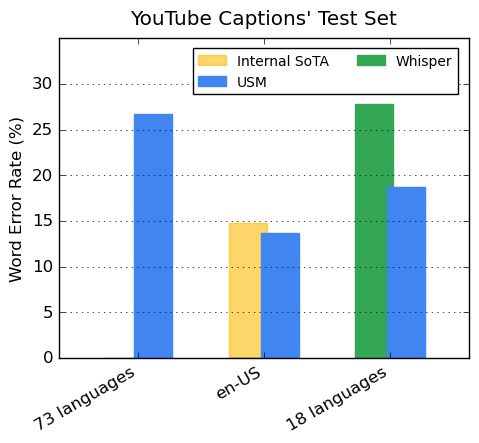
YouTube字幕の多言語音声データを用いた検証では、USMは73言語の平均でWord Error Rate(単語エラー率)30%未満を達成しており、Googleは「これまでに達成したことのないマイルストーンです」と述べています。また、アメリカ英語の翻訳でも最先端モデルを上回る性能を発揮したほか、OpenAIの高性能文字起こしAI「Whisper」が単語エラー率40%未満の18言語を対象にした比較では、USMの方が平均して32.7%低い単語エラー率を記録しました。
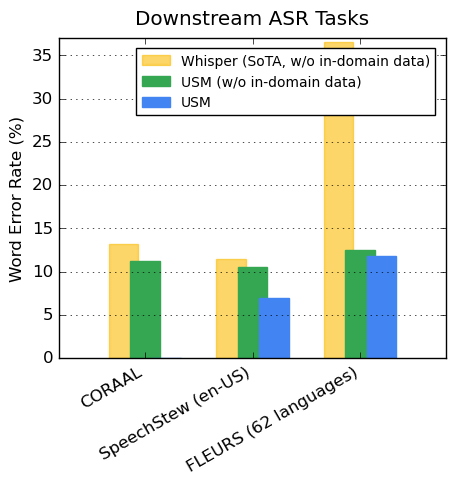
アフリカ系アメリカ人の英語データセットであるCORAAL、英語データセットのSpeechStew、102言語を含むデータセットのFLEURSを使用し、USMとWhisperで単語エラー率を比較したグラフが以下。ドメイン内データを含まないWhisperの単語エラー率が黄色、ドメイン内データを含まないUSMの単語エラー率が緑色、ドメイン内データを含むUSMの単語エラー率が青色の棒で示されており、ドメイン内データの有無にかかわらずUSMがより低い単語エラー率を記録しています。
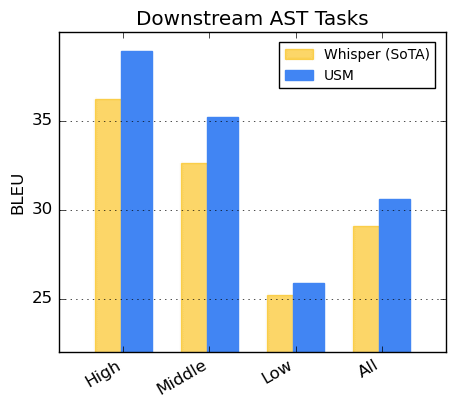
以下は、リソースの可用性に基づいて言語をHigh・Middle・Lowに分類し、機械翻訳の精度を示すBLEUスコアを各言語グループごとに示したグラフです。BLEUスコアはより高い方が翻訳精度が優れていることを示しており、いずれのグループでもUSMはWhisperを上回っていることがわかります。
Googleは、「USMの開発は世界中の情報を整理し、普遍的にアクセスできるようにするというGoogleのミッションの実現に向けた重要な取り組みです。USMのベースモデルアーキテクチャとトレーニングパイプラインは、次の1000言語対応の音声モデルへの拡張を可能にする基盤になると信じています」と述べており、研究者からAPIへのアクセス要求を受け付けています。
・関連記事
Google翻訳が24の新しい言語をサポート - GIGAZINE
Googleが「知らない言語」も翻訳処理ができてしまう言語モデル「LaBSE」を発表 - GIGAZINE
AIを駆使した音声翻訳システムをMetaが公開、テキストデータの収集が困難なマイナー言語にも対応 - GIGAZINE
AIの力で英文を一発校正できる無料ウェブサービス「DeepL Write」が登場したのでDeepL翻訳と組み合わせて爆速英文作成してみた - GIGAZINE
AIベースの言語翻訳サイト「DeepL」が10億ドル以上の評価額で1億ドル以上の調達に成功 - GIGAZINE
Metaが200の言語で機能するAI翻訳モデルをオープンソース化、 メタバースで世界中の人々が交流できることを目指す - GIGAZINE
Google翻訳をはじめとした翻訳ツールは用語誤解の原因になりうる - GIGAZINE
Google翻訳が突然「終末期」や「イエスの再来」などを予言してくると話題に - GIGAZINE
OpenAIが高性能文字起こしAI「Whisper」を発表、日本語にも対応し早口言葉や歌詞も高精度に文字起こし可能 - GIGAZINE
無料でOpenAIの「Whisper」を使って録音ファイルから音声認識で文字おこしする方法まとめ - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, ネットサービス, Posted by log1h_ik
You can read the machine translated English article The latest information on Google's t….