NVIDIA Announces Open Model 'Nemotron-4 340B', Will It Revolutionize the Generation of Synthetic Data for LLM Training?

High-quality learning data is essential for training advanced AI, but such data is rapidly becoming scarce, which is
NVIDIA Releases Open Synthetic Data Generation Pipeline for Training Large Language Models | NVIDIA Blog
https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
Nvidia's 'Nemotron-4 340B' model redefines synthetic data generation, rivals GPT-4 | VentureBeat
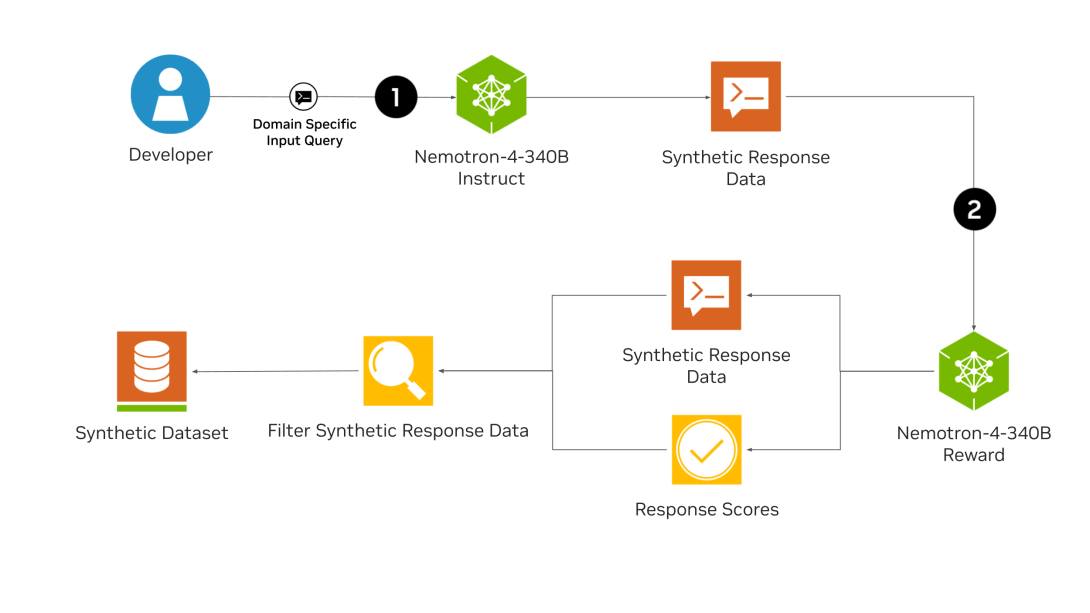
Nemotron-4 340B consists of three models: Base, Instruct, and Reward, which can be used as a synthetic data generation pipeline. It is optimized for use with
In addition, Nemotron-4 340B is an open model that boasts 9 trillion tokens and 4,000 context windows , and supports more than 50 natural languages and more than 40 programming languages. It outperforms Meta's Llama3-70B and Anthropic's Claude 3 Sonnet in performance, and is comparable to GPT-4, according to IT news site VentureBeat.
Below is a synthetic data generation pipeline using Nemotron-4 340B. First, the Nemotron-4 340B Instruct model generates diverse and realistic synthetic data. Then, the evaluation model Nemotron-4 340B Reward evaluates it based on five attributes: usefulness, accuracy, consistency, complexity, and redundancy, and performs iterative improvements and accuracy verification.
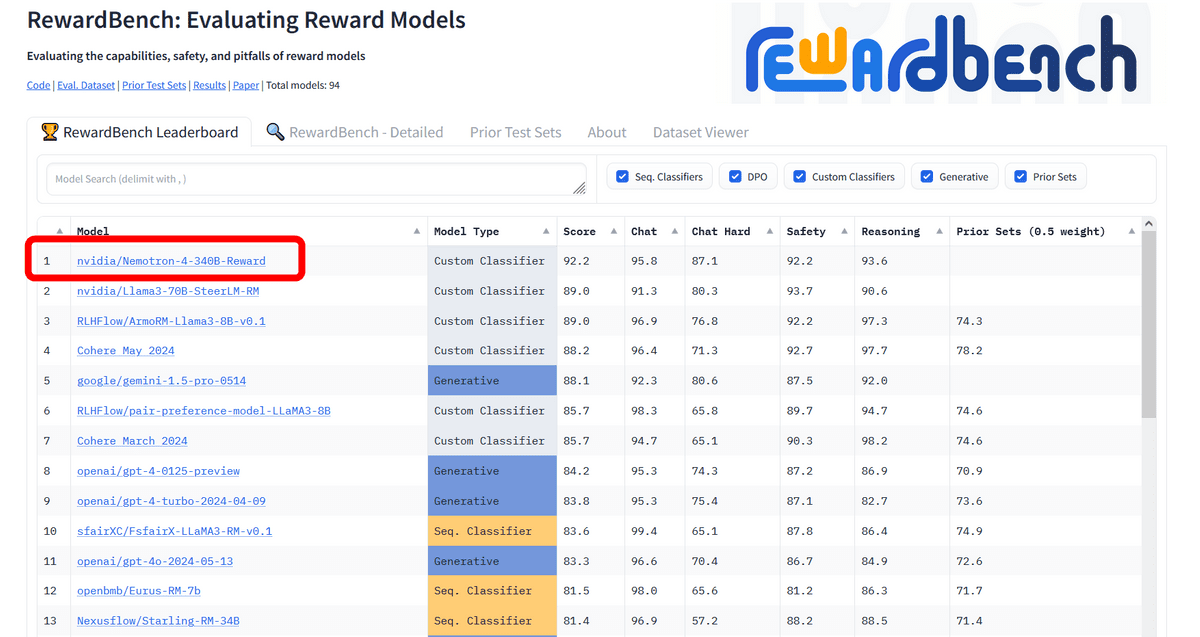
Nemotron-4 340B Reward is
The Nemotron-4 340B is already available on Hugging Face, and will soon be available on NVIDIA's official website (ai.nvidia.com).
Feedback from users who have had the chance to try out the Nemotron-4 340B on LMSYS Org's Chatbot Arena has been overwhelmingly positive, with many praising the device's performance and the amount of expertise it provides.
VentureBeat said, 'NVIDIA has once again solidified its position as the undisputed leader in AI innovation with the release of Nemotron-4 340B, which revolutionizes the generation of synthetic data to train LLMs.'
Related Posts:







in Software, Posted by log1l_ks