OpenCoder, a completely open and reproducible large-scale language model, is released

A team of researchers from Shanghai-based AI company
OpenCoder: Top-Tier Open Code Large Language Models
https://opencoder-llm.github.io/

When talking about large-scale language models, there are various opinions on how open they are. If the model architecture is public and anyone can train a large-scale language model with their own data, it is called 'open source.' If the trained model is public and anyone can run it on their local PC, it is called 'open weight.' If the data used for training is public and anyone can reproduce the training, it is called 'open data.' OpenCoder is a 'fully open model' that is completely public.
OpenCoder has released a 1.5 billion parameter model and an 8 billion parameter model, and the 8 billion parameter model achieved the highest score ever for a base model of its size in the 'fully open model' category.
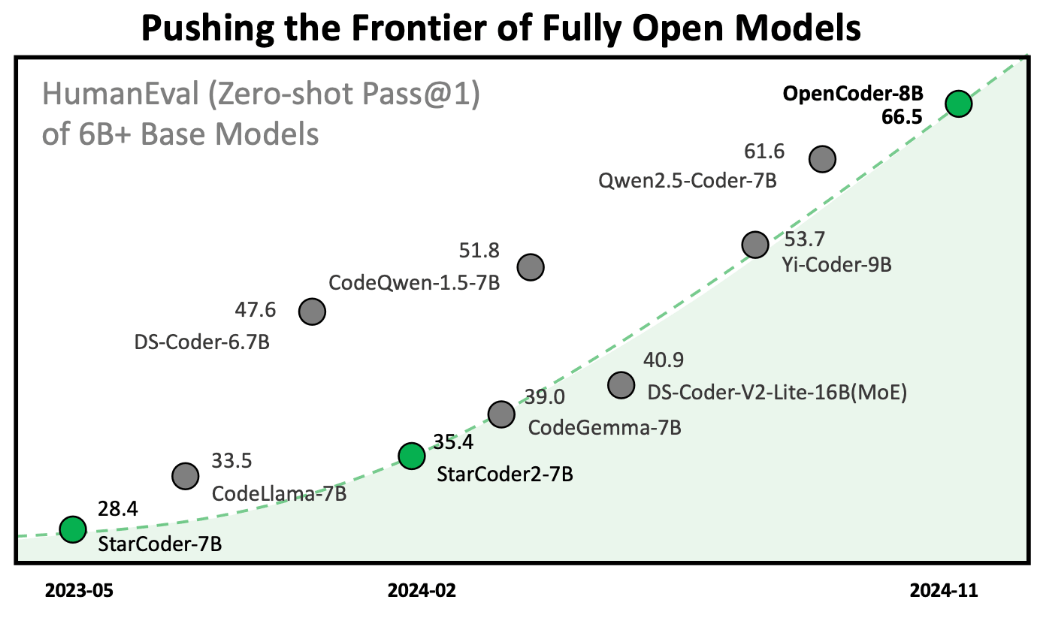
OpenCoder was pre-trained on a total of 2.5 trillion tokens, using 90% code data and 10% code-related web data for a total of 75 billion tokens, and then fine-tuned using 4.5 million high-quality examples.

At the time of writing, the paper detailing how the model was created , the trained model itself , and 4.5 million high-quality examples used for supervised fine-tuning have been made public. Work is underway to release other data as well.
According to comments from people who have actually tried OpenCoder , the quality of OpenCoder is not that high, falling far short of GPT-4, and it has been completely defeated by the Qwen2.5 72B model developed by Alibaba and the Llama 3.1 70B model developed by Meta. In addition, the incidence of hallucinations is also high .
Unlike other models, OpenCoder has made an effort to make all the information needed to develop the models publicly available. 'Regardless of the performance of the model, having all the steps open is to everyone's benefit,' he said.
Related Posts:








in Free Member, AI, Software, Posted by log1d_ts