GPT-4-based ChatGPT ranks first in conversational chat AI benchmark rankings, Claude-v1 ranks second, and Google's PaLM 2 also ranks in the top 10

The Large Model Systems Org (LMSYS Org), an open research organization established by UC Berkeley students and faculty in collaboration with UC San
Chatbot Arena Leaderboard Updates (Week 4) | LMSYS Org
https://lmsys.org/blog/2023-05-25-leaderboard/

In Chatbot Arena, users are invited to FastChat , an open platform for evaluating LLM-based conversational AI, have conversations with two anonymous models, and vote on which one is more accurate. increase. Based on the results of this vote, the win/loss and rating based on the Elo rating widely used in chess etc. will be performed, and the standings will be published.
Below is the ranking based on anonymous voting data of 27,000 votes from April 24th to May 22nd, 2023. ChatGPT, which is based on OpenAI's GPT-4, ranked first, while OpenAI competitor Anthropic's Claude-v1 and its lightweight model came in second and third.
| rank | model | Elo Rating | Commentary |
| 1 | GPT-4 | 1225 | ChatGPT based on GPT-4 |
| 2 | Claude-v1 | 1195 | Anthropic Chat AI |
| 3 | Claude-instant-v1 | 1153 | Faster and cheaper with Claude's lighter model |
| Four | GPT-3.5-turbo | 1143 | ChatGPT based on GPT-3.5 |
| Five | Vicuna-13B | 1054 | Chat AI fine-tuned from LLaMA, 13 billion parameters |
| 6 | PaLM2 | 1042 | A chat AI based on 'PaLM 2' like Google's chat AI 'Bard'. |
| 7 | Vicuna-7B | 1007 | Chat AI fine-tuned from LLaMA, 7 billion parameters |
| 8 | Koala-13B | 980 | Chat Ai based on GPT-3.5 Turbo |
| 9 | mpt-7B-chat | 952 | Chat AI based on MosaicML's open source LLM 'MPT-7B' |
| Ten | FastChat-T5-3B | 941 | Chat AI developed by LMSYS org |
| 11 | Alpaca-13B | 937 | Chat AI based on LLM 'Alpaca 7B', fine-tuned from Meta's LLaMA |
| 12 | RMKV-4-Raven-14B | 928 | RNN-employed LLM-based chat AI with comparable performance to Transformer-employed LLM |
| 13 | Oasst-Pythia-12B | 921 | Open assistant by LAION |
| 14 | ChatGLM-6B | 921 | An Open Bilingual Dialogue Language Model by Tsinghua University |
| 15 | StableLM-Tuned-Alpha-7B | 882 | Stablity AI's language model-based chat AI |
| 16 | Dolly-V2-12B | 886 | Open-source LLM-based chat AI tuned by Databricks MIT |
| 17 | LLaMA-13B | 854 | Chat AI based on Meta's LLaMA-13B |
Below is a table showing the winning percentage in color. Higher win rates are shown in blue, lower win rates are shown in red.
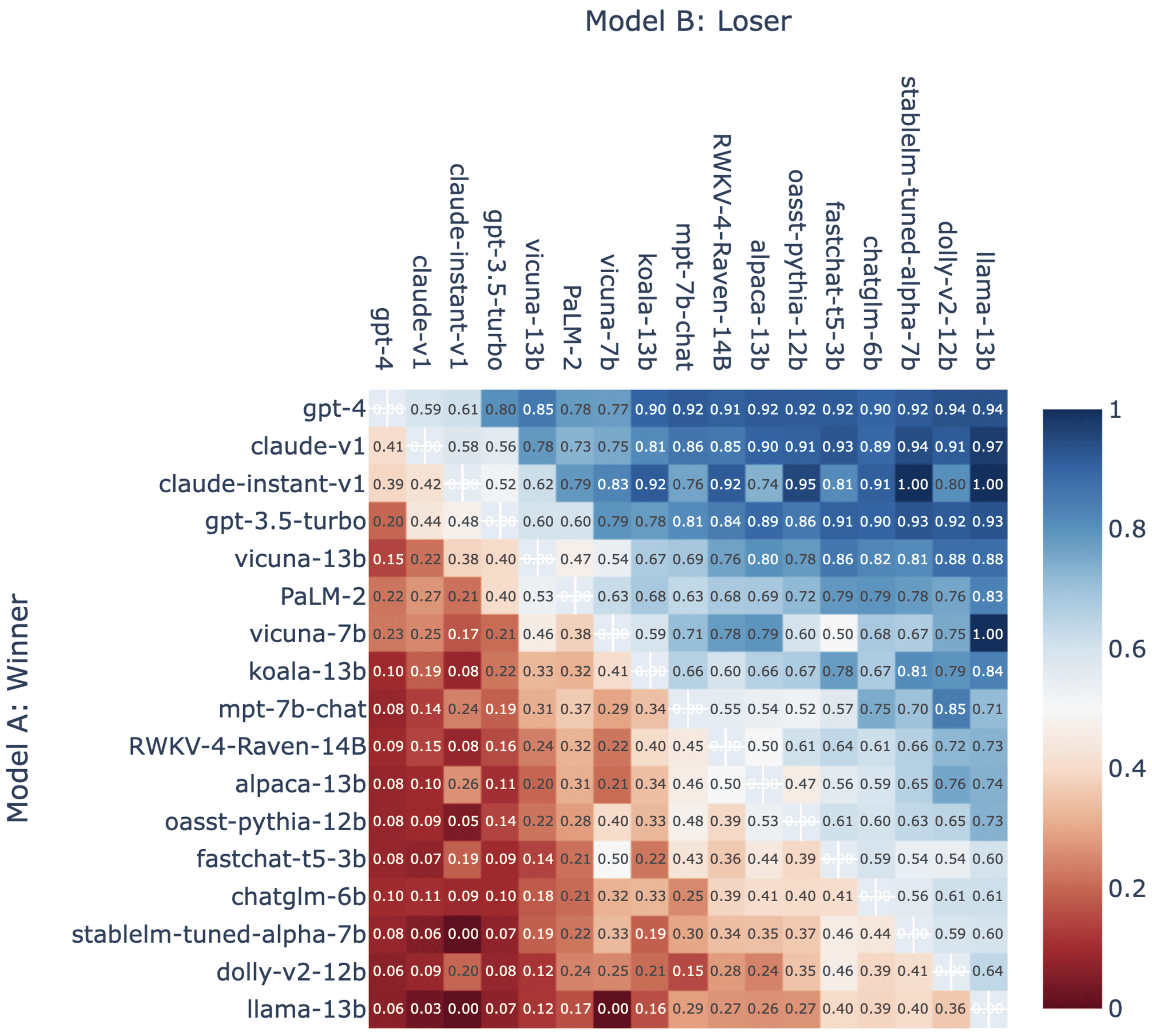
In this result, LMSYS Org focuses on 'Google PaLM 2'. PaLM 2 is ranked 6th in the standings and has a good win rate. However, LMSYS Org said, ``PaLM 2 seems to be more regulated than other models.When users ask unclear or difficult questions, PaLM 2 is more likely to refrain from answering than other models. will be.”
For example, when asked to emulate a Linux terminal or programming language
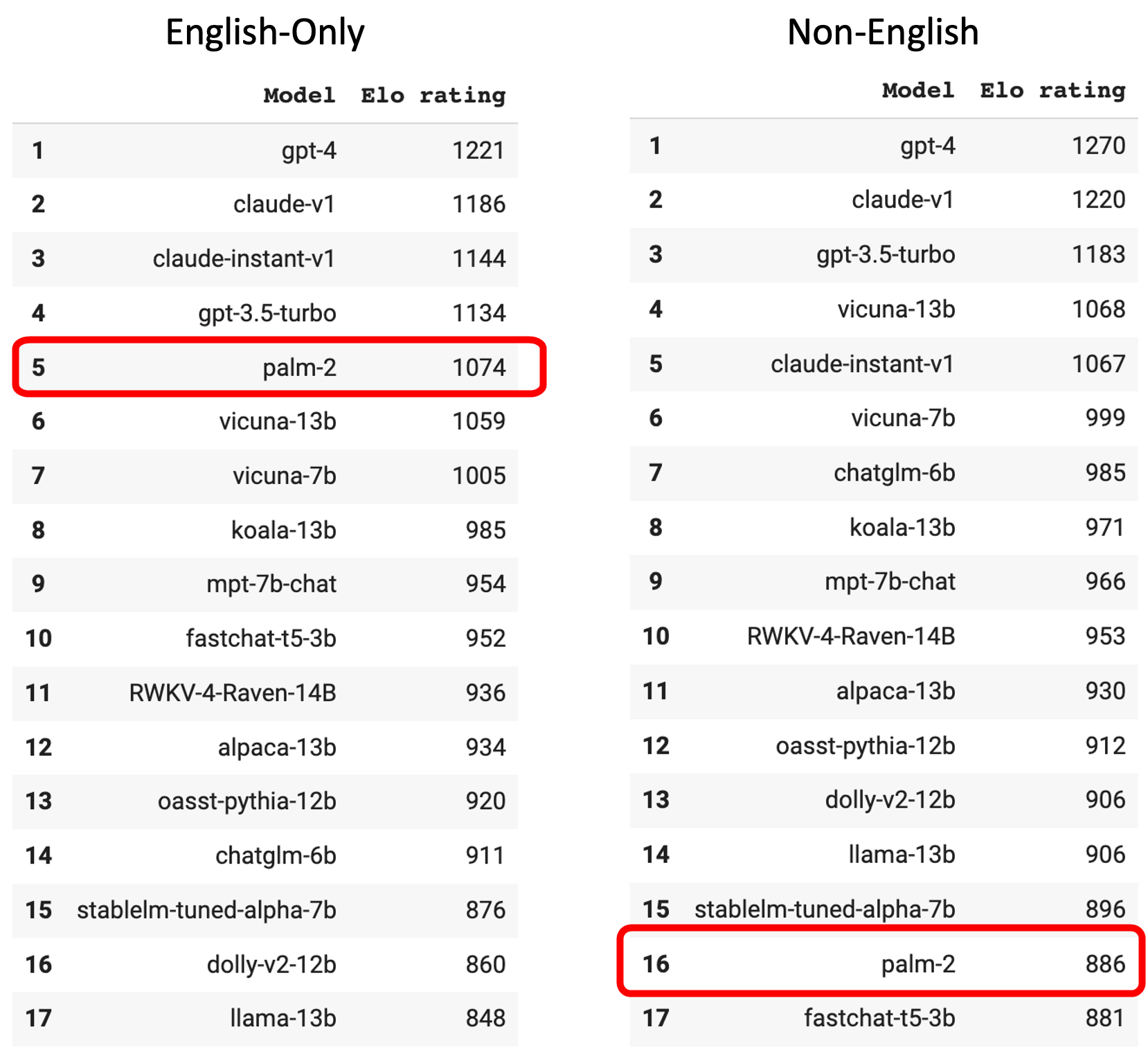
Also, it seems that PaLM 2 tended not to answer questions other than English, such as Chinese, Spanish, and Hebrew. PaLM 2 ranked 5th when only questions asked in English were taken into account, but fell to 16th when asked questions in non-English.
LMSYS Org also noted the high ranking of chatbots based on smaller LLMs such as Vicuna-7B and mpt-7b-chat. It seems that the small model showed a performance advantage when compared to a large model with more than twice the number of parameters. And fine-tuning datasets seem to be more important in some cases,' he said, pointing out that preparing a high-quality dataset through pre-training and fine-tuning is an important approach to reducing model size. doing.
Related Posts:






in Software, Posted by log1i_yk