China's Alibaba releases chat AI 'Qwen-72B' and local voice input compatible 'Qwen-Audio' as open source

Alibaba, a major Chinese IT company, has released a Transformer-based large-scale language model 'Qwen-72B' that boasts 72 billion parameters, and 'Qwen-Audio', a multimodal version of Qwen that also supports Japanese voice input. announced that it has been open sourced.
Qwen/README_EN.md at main · QwenLM/Qwen · GitHub
Qwen/Qwen-72B-Chat · Hugging Face
https://huggingface.co/Qwen/Qwen-72B-Chat
GitHub - QwenLM/Qwen-Audio: The official repo of Qwen-Audio (通义千问-Audio) chat & pretrained large audio language model proposed by Alibaba Cloud.
https://github.com/QwenLM/Qwen-Audio
Binyuan Hui, who researches neurolinguistic programming (NPL) at Alibaba DAMO Academy, Alibaba Group's cutting-edge research institute, posted on SNS, ``Our sincere open source works, Qwen-72B and Qwen-1.8. I'm proud to introduce B!'
We are proud to present our sincere open-source works: Qwen-72B and Qwen-1.8B! Including Base, Chat and Quantized versions!
— Binyuan Hui (@huybery) November 30, 2023
???? Qwen-72B has been trained on high-quality data consisting of 3T tokens, boasting a parameter larger scale and more training data to achieve a… pic.twitter.com/VUAMbh83At
Qwen-72B is a large-scale language model trained with over 3 trillion tokens, and has been tested in a series of benchmarks for natural language understanding, numerical processing, coding, etc., including MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, and BBH. This task outperformed Meta's LLaMA2-70B, a model of the same size. Additionally, it outperformed OpenAI's GPT-3.5 in 7 out of 10 tasks.
Users who have tried it out have reported that they can easily process Japanese.
Inference speed of Qwen-72B was compared with Stablem-base-70B
— AI????Satoshi⏩ (@AiXsatoshi) November 30, 2023
Qwen has a vocab size of 152,000
Stablelm is Llama2 series, 32,000
Qwen was quick in reasoning even in Japanese ??? pic.twitter.com/ft97X3UHmS
However, there are opinions that it is a little difficult to run it locally because it requires a large amount of memory.
Qwen-72B-Chat requires at least 144GB GPU memory to run on bf16/fp16 (e.g. 2xA100-80G or 5xV100-32G) and at least 48GB GPU memory to run on int4 (e.g. 1xA100-80G or 2xV100-32G).
— Yousan (@ayousanz) November 30, 2023
It's impossible... https://t.co/8hrpCG47Sv
In addition to Qwen-72B, Qwen also includes 'Qwen-1.8B,' 'Qwen-7B,' and 'Qwen-14B' with different parameter sizes. Additionally, a demo is available that allows you to run Qwen-72B in a browser, although user registration in Chinese is required.
通义千问-72B-对话-Demo · 创空间
https://modelscope.cn/studios/qwen/Qwen-72B-Chat-Demo/summary
Mr. Hui also announced that the model 'Qwen-Audio' that supports voice input has also been open sourced.
???? Thanks to all the enthusiasm, let's add some fuel to the fire! We've further open-sourced ???? Qwen-Audio, including Base and Chat, as well as the demo!
https://t.co/J8ACjUO4xE
???? Base:
???? Chat: https://t.co/p0RzfAvYxG
???? Demo: https://t.co/F1b30iHy5c https://t.co/B2sf4xsc7I — Binyuan Hui (@huybery) November 30, 2023
Qwen-Audio is a combination of Qwen-7B and OpenAI's audio encoder Whisper-large-v2, and is said to outperform existing state-of-the-art (State of the Art: SoTA) models in all tasks.
Making audio a first-class citizen in LLMs: Qwen Audio ????
— Vaibhav (VB) Srivastav (@reach_vb) November 30, 2023
Using a Multi-Task Training Framework, Qwen Audio - Combines OpenAI's Whisper large v2 (Audio encoder) with Qwen 7B LM to train on over 30 audio tasks jointly.
Tasks ranging from Speech Recognition to Music Captioning… pic.twitter.com/7gzKAV6rfv
You can try the Qwen-Audio demo on Hugging Face without registering.
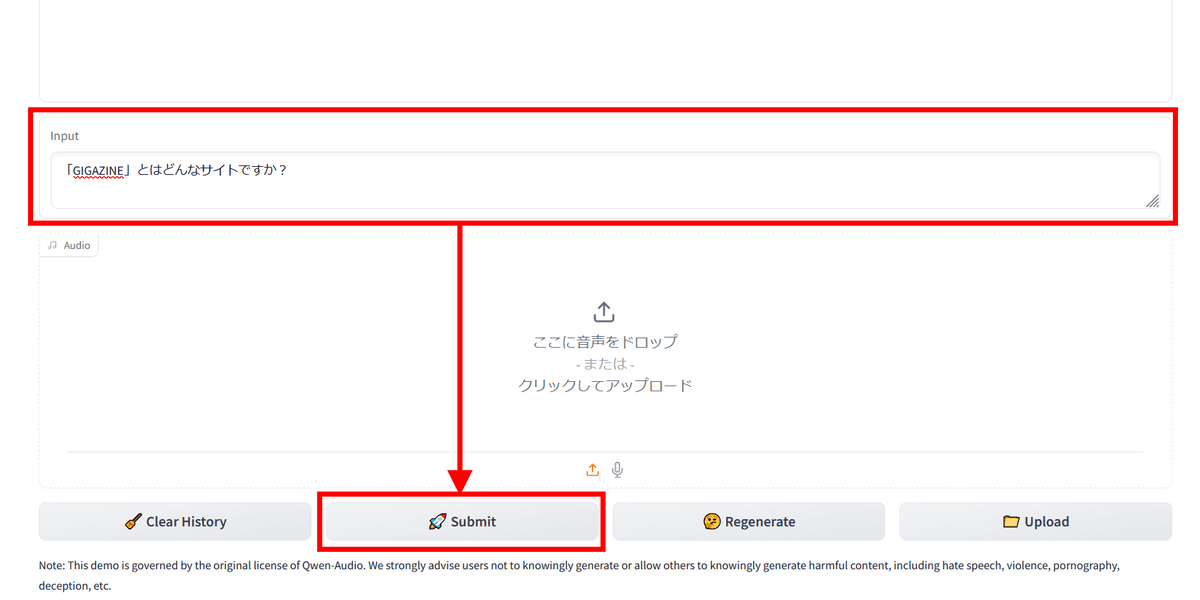
First, I entered Japanese text and asked a question.
Then, the following answer was output.
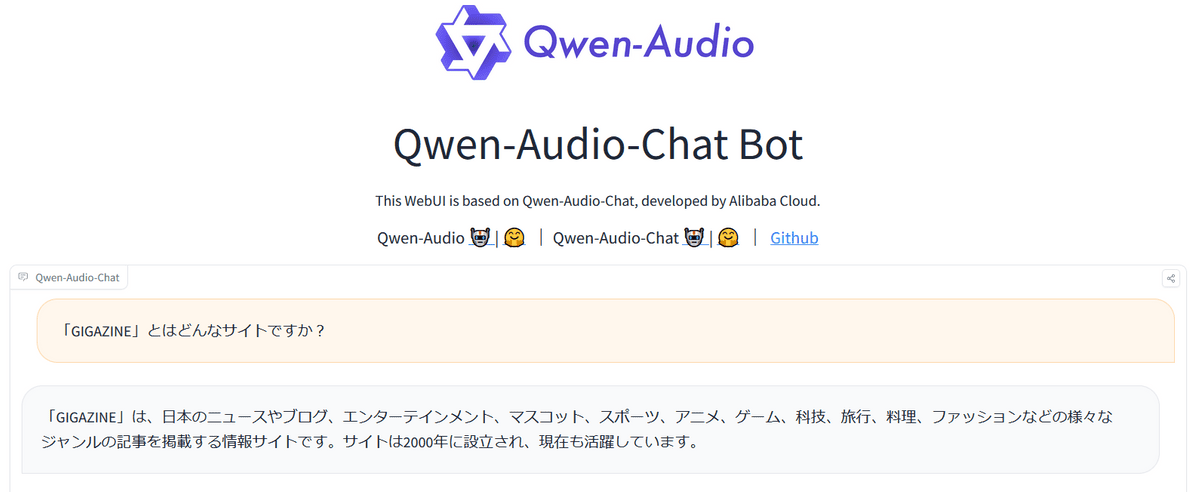
It seems that it also supports audio, so I tried uploading the audio file. What I used was the beginning of the video I created in a previous article .
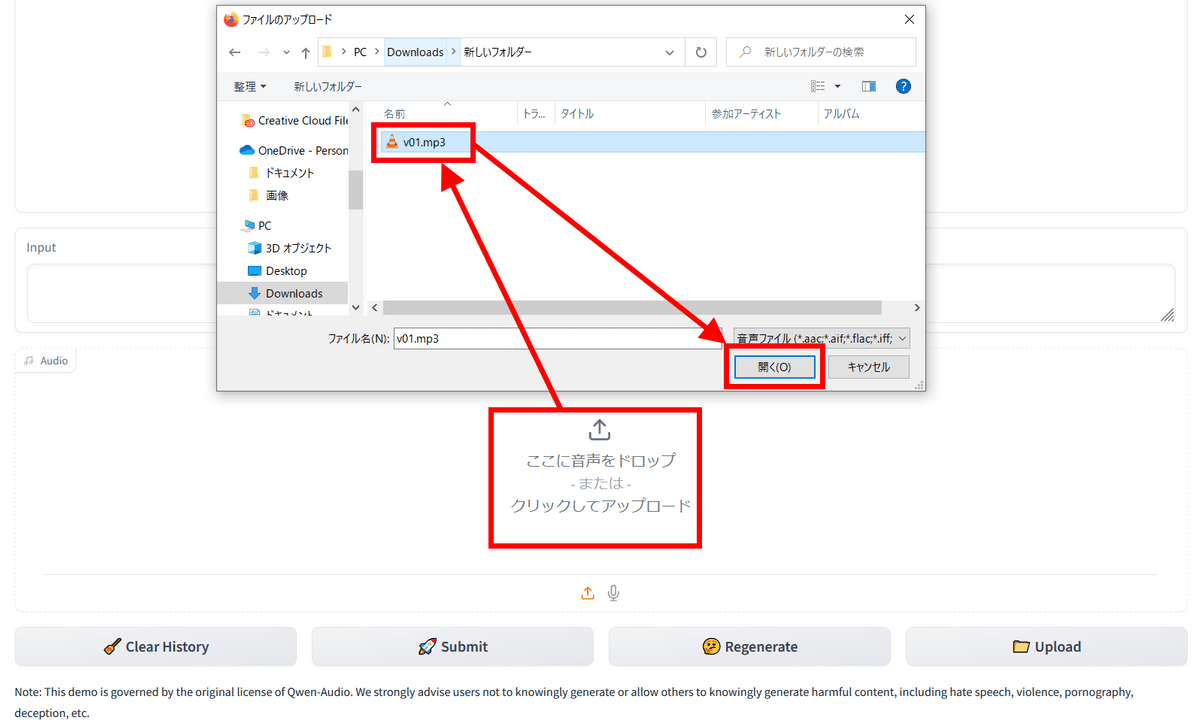
Click Submit to submit.
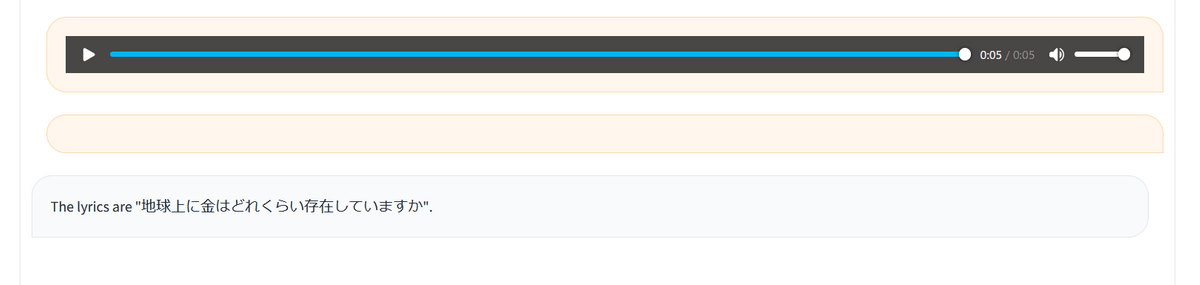
The content of the audio file is ``How much gold is there on earth?'' For some reason, it was recognized as lyrics, so I couldn't have a conversation with it, but it seems to be highly accurate.
I was also able to hear Elon Musk's
Qwen-Audio-Chat reportedly supports speech understanding in Chinese, English, Japanese, Korean, German, Spanish, and Italian.
Related Posts: