




OpenAIが言語モデルの事実性を測定するベンチマーク「SimpleQA」をオープンソースでリリース

OpenAIが言語モデルの事実性(factuality)を測定するためのベンチマーク「SimpleQA」を発表しました。SimpleQAは科学技術からエンターテインメントまでの幅広いトピックを含んだ検証済みの4000種類以上の質問から構成されています。
Introducing SimpleQA | OpenAI
https://openai.com/index/introducing-simpleqa/
GitHub - openai/simple-evals
https://github.com/openai/simple-evals/
言語モデルは入力されたトークンに対して確率的に回答を生成し、人間が書いたような自然な文章を構成します。しかし、AIは人間のように文章中のの論理性や正確性を理解しているわけではなく、「幻覚」と呼ばれる誤った出力や回答を生成することがあります。そこで、近年の言語モデルには論理検証を行うように設計されたものも登場しています。
SimpleQAは、「高い正確性」「多様性」「最先端のモデルに対応」「高速かつシンプルな実行」を目的として作成されており、データセットに含まれる質問に対するAIモデルからの予測回答を確認し、ChatGPTを用いて予測回答を正解・不正解・未回答のいずれかに採点します。
データセットに含まれる質問は1人のAIトレーナーが「議論の余地なく単一の回答が可能であること」「質問の回答が時間の経過とともに変化しないこと」「GPT-4oやGPT-3.5の幻覚を誘発しうること」を条件に選定し、2人目のAIトレーナーが各質問に回答。2人のAIトレーナーの回答が一致した質問のみがデータセットに含められたとのこと。
さらに3人目のAIトレーナーがデータセットに含まれる質問のうちからランダムに選出した1000問に回答したところ、1人目と2人目による回答と94.4%の確率で一致したそうです。5.6%の不一致のうち、2.8%は採点者の誤検出あるいは3人目のミスによるもので、残りの2.8%は質問内容が曖昧だったり矛盾する回答が存在したりするケースでした。そのため、SimpleQAのデータセット固有のエラー率は約3%だとOpenAIは報告しています。
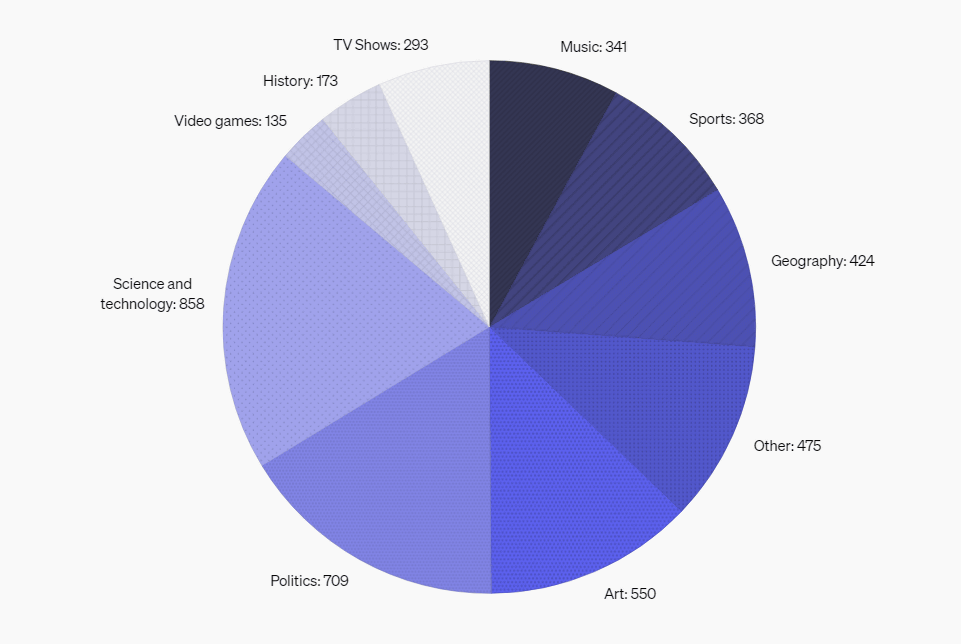
質問のカテゴリ別分布をまとめた円グラフが以下。
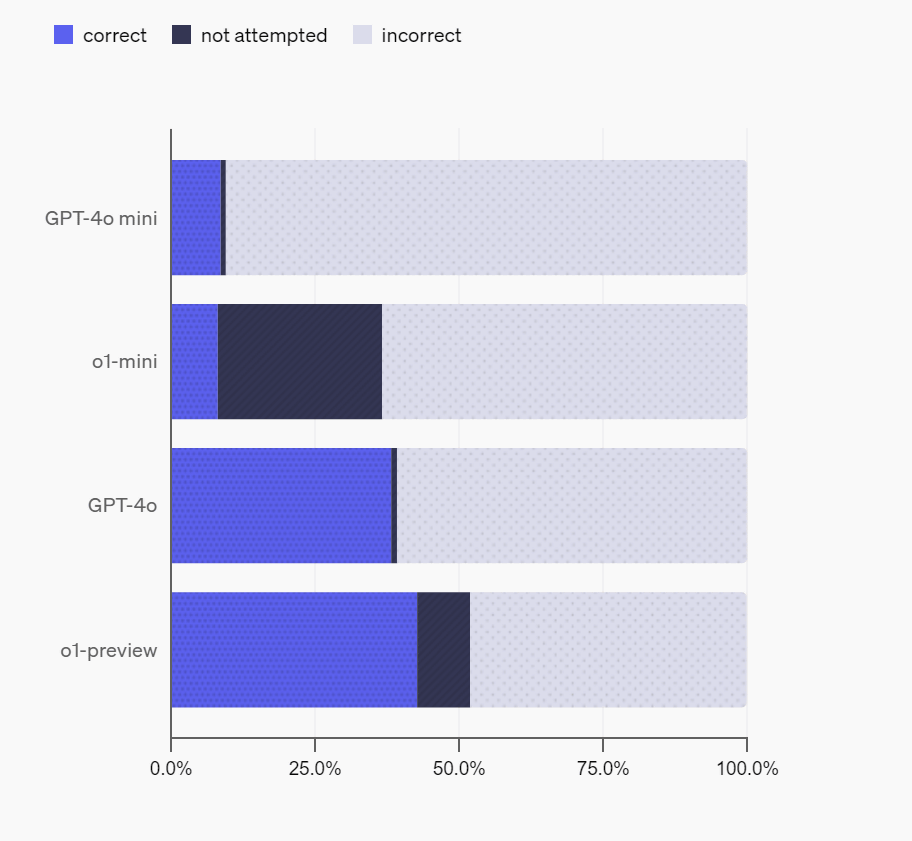
実際にOpenAIがSimpleQAを用いて「GPT-4o mini」「o1-mini」「GPT-4o」「o1-preview」の事実性を測定した結果が以下。GPT-4o miniとo1-miniの事実性が低くなっているのは「モデルが小さいために世界に関する知識が少なかったから」とOpenAIは分析しています。また、o1-miniとo1-previewはGPT-4o miniやGPT-4oよりも未回答(not attempted)にしたケースが多く見られましたが、これは「o1-miniとo1-previewは推論能力を使用することで、質問の答えがわからないことを認識できるため」だとのこと。
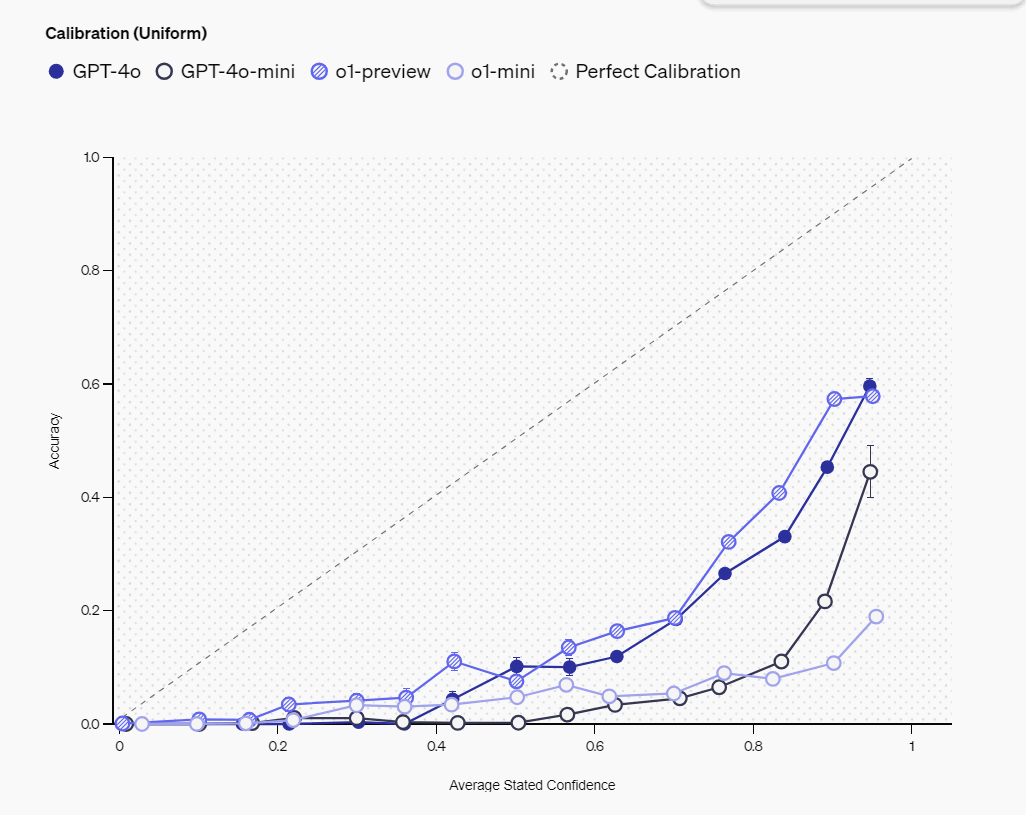
OpenAIは言語モデルが「自身の知識をどれだけ正確に認識しているか」を示す「キャリブレーション」を2つの方法で測定しています。
1つ目は、モデルに回答の信頼度を百分率で申告させ、その申告された信頼度と実際の正確性との相関を調べる方法です。理想的なモデルであれば、例えば75%の信頼度を示した回答群の実際の正解率も75%になるはずです。
以下はモデルの自己申告による信頼度(横軸)と実際の正確性(縦軸)の関係を示したグラフです。対角線にある点線は理想的な状態を表わし、信頼度と実際の正確性が一致することを示しています。実際のデータは対角線よりも下ですが、これは各モデルが自身の正確性を過大評価している傾向にあることを示しています。
2つ目は、同じ質問を100回繰り返し、特定の回答が出現する頻度とその正確性との関係を分析する方法です。より頻繁に同じ回答を返すということは、モデルがその回答に自信を持っていることを示唆します。
以下のグラフは、同じ質問に対する回答の一貫性(縦軸)と正確性(横軸)の関係を示したもの。このグラフでは、より頻繁に出現する回答ほど正確性が高い傾向が示されており、特にo1-preview(斜線入り○)は対角線に近い位置にプロットされていることから、回答の一貫性と正確性のバランスが最も良いことが分かります。これは、モデルが自信を持って頻繁に出力する回答ほど、実際に正解である可能性が高いことを意味しています。
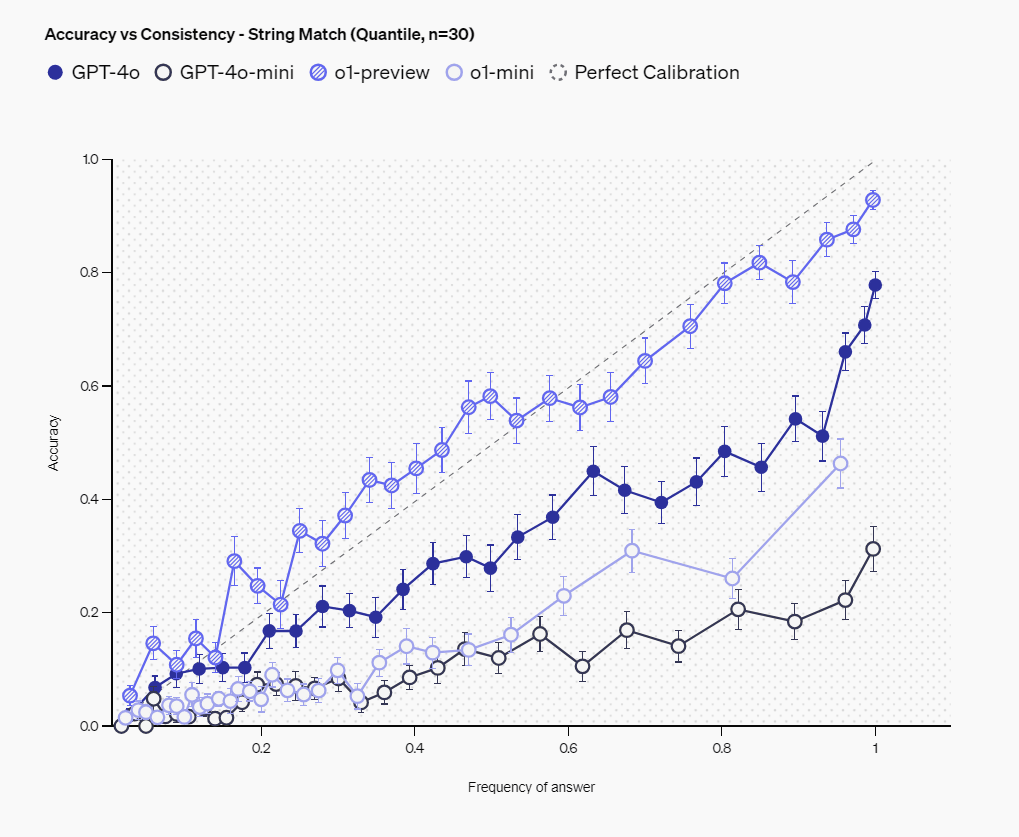
測定の結果、o1-previewやGPT-4oなどの大規模モデルの方が、より小規模なモデルと比べて優れたキャリブレーションを示すことが分かりました。ただし、すべてのモデルにおいて、申告された信頼度は実際の正確性を上回る傾向が見られ、この点での改善の余地が大きいことが示されています。また、回答の一貫性と正確性の相関においては、特にo1-previewが高いパフォーマンスを示し、回答の出現頻度と正確性がほぼ同等になるレベルに達していることが確認されています。
OpenAIは「SimpleQAはシンプルながらも挑戦的なベンチマーク」と評価していますが、短い事実確認型の質問で単一の検証可能な回答がある場合のみを測定するという制限があり、長文の回答における事実性との相関は現時点で未解明な研究課題として残されていると述べています。そのうえでOpenAIは、SimpleQAをオープンソース化することで、より信頼性の高いAIの研究を促進することを目指しており、研究者たちに言語モデルの事実性を評価し、フィードバックを提供することを呼びかけています。
なお、SimpleQAはオープンソースでリリースされており、リポジトリがGitHubで公開されています。
・関連記事
AppleのAI研究者らが「今のAI言語モデルは算数の文章題への推論能力が小学生未満」と研究結果を発表 - GIGAZINE
なぜ大規模言語モデル(LLM)はだまされやすいのか? - GIGAZINE
OpenAIが推論に焦点を当てた新AIモデル「Strawberry」を2週間以内にリリースか - GIGAZINE
GPT-4やClaudeなどの大規模言語モデルが抱える「ストロベリー問題」とは? - GIGAZINE
Microsoftの「Copilot+ PC」は主張されているほどAI処理性能が高くないというベンチマーク結果が報告される - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article OpenAI releases open source 'SimpleQA', ….