




GPT-4やClaudeなどの大規模言語モデルが抱える「ストロベリー問題」とは?

大規模言語モデル(LLM)をベースにしたAIは高い能力を発揮できる一方で、ウソにダマされやすいといった特徴があったり、算数の文章題への推論能力が小学生未満という研究結果があったりと、脆弱(ぜいじゃく)さについてもしばしば指摘されます。AIの能力の限界を示す「ストロベリー問題」という脆弱性について、機械学習エンジニアのチンメイ・ジョグ氏が解説しています。
The 'strawberrry' problem: How to overcome AI's limitations | VentureBeat
https://venturebeat.com/ai/the-strawberrry-problem-how-to-overcome-ais-limitations/
ChatGPTやStable DiffusionなどのジェネレーティブAIは、高度な文章やコードを書けたり、イラストやリアルな画像を出力できたりと、誰でも簡単に高度な能力を発揮させることができます。しかし、たとえば画像生成AIの場合は「1本のバナナ問題」という脆弱性を抱えています。IT系ニュースサイト・Digital Scienceのダニエル・フックCEOが「A single banana(1本のバナナ)」というプロンプトで画像を生成した結果、出力されたのは「2本で1房のバナナ」だったそうです。フックCEOによると、AIには「写真の中のバナナは2本である」というようなバイアスがあり、実際にプロンプトが指定するものを理解しているわけではないAIは、データセットで学習したバイアスに引っ張られてしまうと考えられるとのこと。
ジェネレーティブAIが抱える問題を浮き彫りにする「1本のバナナ問題」とは? - GIGAZINE

同様の問題として、文章を扱うLLMが抱える問題としてジョグ氏が上げているのが「ストロベリー問題」です。以下の画像でジョグ氏は、ChatGPTに対し「what is the number of r s in strawberry(ストロベリーという英単語に、『r』は何個含まれるか)」と質問しました。「strawberry」という単語を見れば誰でもわかる通り、3文字目と8、9文字目の合計3つの「r」があります。しかし、以下の画像でChatGPTは「The word ”strawberry” contains 2 “r”s(ストロベリーという英単語は2つの『r』で構成されています)」と回答しています。
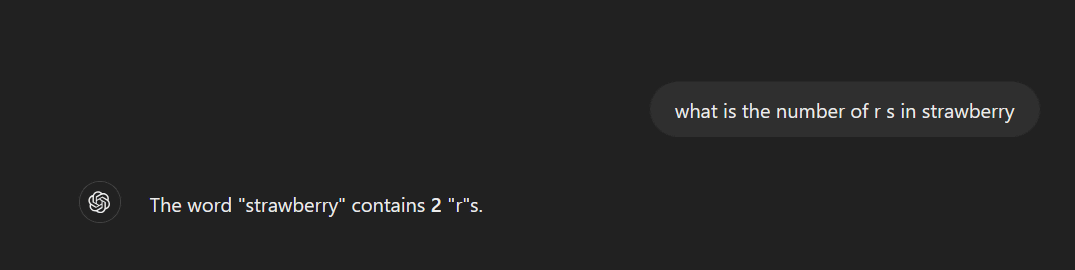
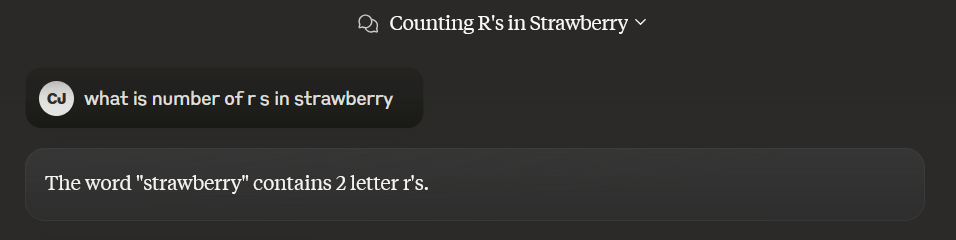
また、以下はAnthropicが開発したLLMを用いた対話型AIであるClaude(クロード)に、同じ「what is the number of r s in strawberry」と質問したものですが、こちらも同様に「ストロベリーに含まれるrは2つ」という回答が返ってきました。
他の例では、「mammal(哺乳類)」の「m」や「hippopotamus(カバ)」の「p」を数える際にも、LLMベースのAIがミスをすることがあります。ジョグ氏によると、ストロベリー問題はLLMの特徴に由来するそうです。
高性能LLMのほぼすべては、Googleの研究者等が発表した深層学習モデルであるTransformer上に構築されています。Transformerは入力されたテキストを直接取り込むわけではなく、テキストを数値表現として「トークン化」するプロセスを使用します。トークンには完全な単語もあれば、単語の一部もあります。たとえば、「strawberry」という単語のトークンがあればそのまま読み込まれますが、単語によっては「straw」「berry」という2つのトークンを組み合わせる形で入力を取り込んでいる場合もあるというわけ。入力内容をトークンに分解することで、モデルは文中の次にどのトークンがくるのかをより正確に予測できます。
そのため、トークンを扱うLLMベースのAIは文脈をふまえて文章の内容を予測することは得意ですが、単語をアルファベット単位で分解することは難しいといえます。ジョグ氏は「個々の文字をトークン化せずに直接確認できるモデル アーキテクチャでは、この問題は発生しない可能性があります。しかし、現在のTransformerアーキテクチャでは、実現不可能です」と述べています。
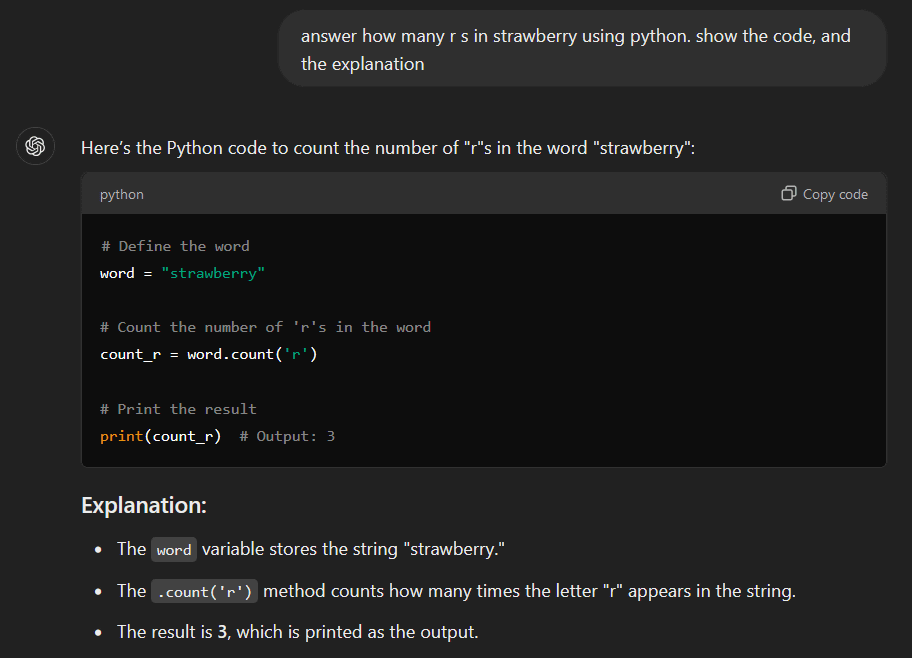
LLMが抱える問題点をふまえた上で、ジョグ氏はストロベリー問題の回避策についても解説しています。その方法とは、普通の文章で対話するのではなく、プログラミング言語のコードを使うように指示して問いかけることです。以下は、ジョグ氏がChatGPTに対し「answer how many r s in strawberry using python. show the code, and the explanation(Pythonを使って、イチゴの『r』の数を答えなさい。コードと説明も示して)」と訪ねた様子。ChatGPTはPythonのcount関数を使ったうえで、正しい「r」の数である「Output=3」と回答することができました。
ジョグ氏は「単純な文字カウントの実験により、LLMの根本的な限界が明らかになりました。この実験では、LLMはトークンのパターンマッチング予測アルゴリズムであり、理解や推論が可能な『知能』ではないことが示されています。ただし、どのようなプロンプトがうまく機能するかを事前に知っておくと、ある程度は問題を軽減できます。私たちの生活にAIが統合されるにつれて、責任を持って使用し、現実的な期待を持つためには、AIの限界を認識することが重要です」とまとめています。
・関連記事
ジェネレーティブAIが抱える問題を浮き彫りにする「1本のバナナ問題」とは? - GIGAZINE
AppleのAI研究者らが「今のAI言語モデルは算数の文章題への推論能力が小学生未満」と研究結果を発表 - GIGAZINE
なぜ大規模言語モデル(LLM)はだまされやすいのか? - GIGAZINE
なぜAIは「手」を描くことを苦手としているのかをアートと工学の専門家が解説 - GIGAZINE
OpenAIがアメリカ当局者に対し「Strawberry」と呼ばれる画期的な成果をデモ、コード名「Orion」という主力LLMのトレーニングデータを作成することでGPT-4越えの性能を目指す - GIGAZINE
・関連コンテンツ




in ソフトウェア, Posted by log1e_dh
You can read the machine translated English article What is the 'strawberry problem' that la….