OpenAI releases open source 'SimpleQA', a benchmark for measuring the factuality of language models

OpenAI has announced SimpleQA , a benchmark for measuring the factuality of language models. SimpleQA consists of over 4,000 verified questions covering a wide range of topics from science and technology to entertainment.
Introducing SimpleQA | OpenAI
GitHub - openai/simple-evals
https://github.com/openai/simple-evals/
A language model generates probabilistic answers to input tokens, composing natural sentences that look like they were written by humans. However, AI does not understand the logic and accuracy of sentences like humans do, and can generate incorrect outputs or answers called 'hallucinations.' Therefore, some language models in recent years have been designed to perform logical verification.
SimpleQA was created with the goals of being highly accurate, diverse, compatible with cutting-edge models, and fast and simple to execute. It checks the predicted answers from AI models to questions included in the dataset, and uses ChatGPT to score the predicted answers as correct, incorrect, or not answered.
The questions included in the dataset were selected by one AI trainer based on the criteria that 'a single, uncontroversial answer is possible,' 'the answer to the question does not change over time,' and 'it can induce hallucinations in GPT-4o and GPT-3.5.' A second AI trainer answered each question. Only questions for which the answers of the two AI trainers matched were included in the dataset.
Furthermore, when the third AI trainer answered 1,000 randomly selected questions from the dataset, the answers matched the answers given by the first and second trainers 94.4% of the time. Of the 5.6% discrepancies, 2.8% were due to false positives by the grader or mistakes by the third trainer, and the remaining 2.8% were due to ambiguous questions or conflicting answers. Therefore, OpenAI reports that the error rate specific to the SimpleQA dataset is about 3%.
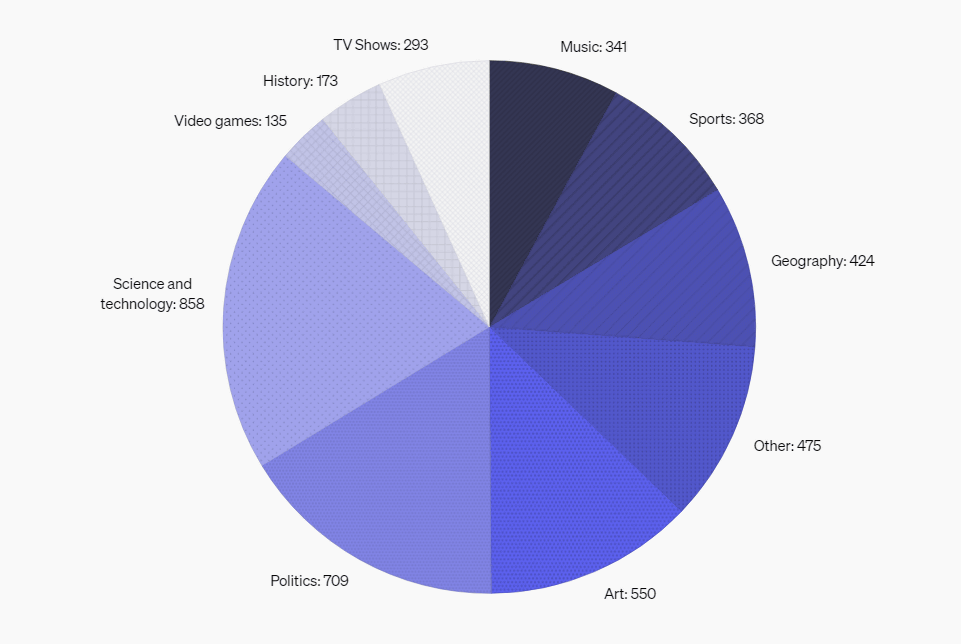
Below is a pie chart summarizing the distribution of questions by category.
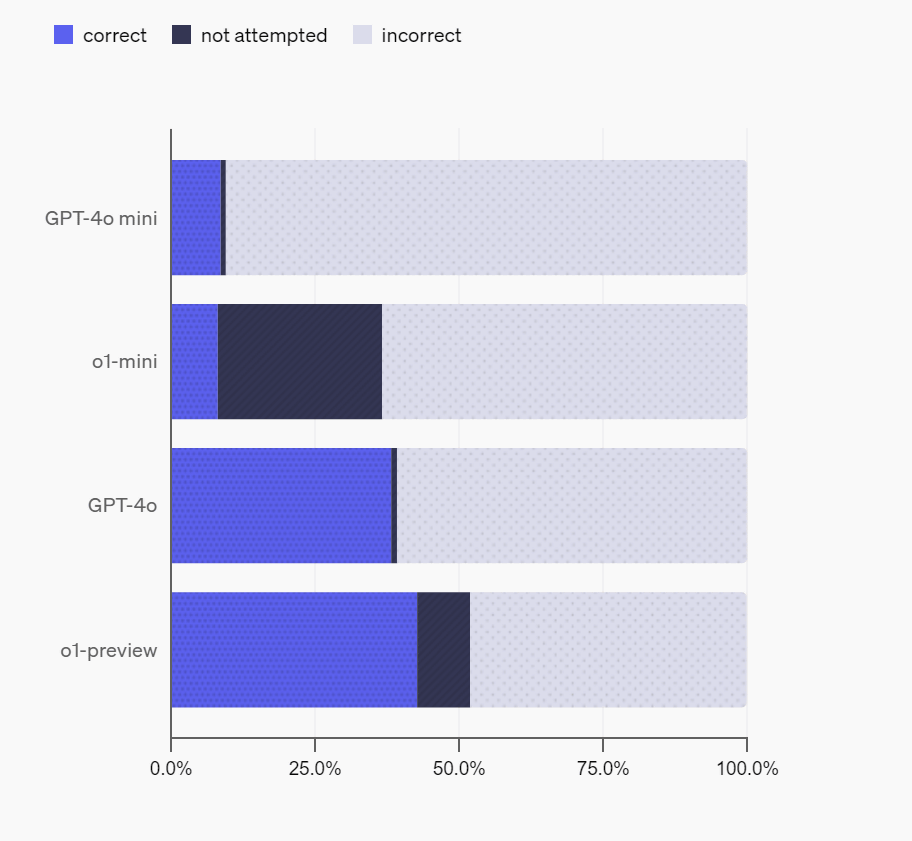
The results of OpenAI's measurement of the factuality of 'GPT-4o mini', 'o1-mini', 'GPT-4o', and 'o1-preview' using SimpleQA are below. OpenAI analyzes that the factuality of GPT-4o mini and o1-mini is low because 'the model is small and there is little knowledge about the world'. In addition, there were more cases where o1-mini and o1-preview were left unanswered (not attempted) than GPT-4o mini and GPT-4o, but this is because 'o1-mini and o1-preview can recognize that they do not know the answer to the question by using their inference ability'.
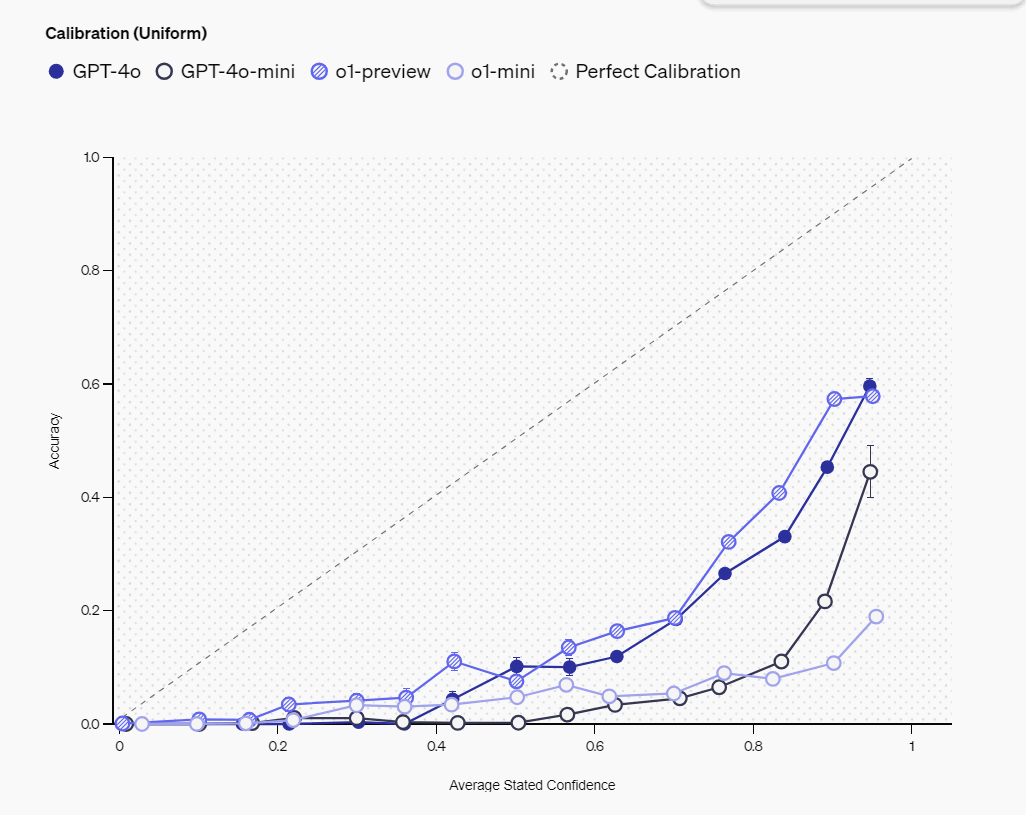
OpenAI measures 'calibration,' which indicates how accurately a language model recognizes its own knowledge, in two ways.
The first is to have the model report its confidence in an answer as a percentage, and then examine the correlation between the reported confidence and its actual accuracy: an ideal model would have an actual accuracy rate of 75% for answers that it reports as 75% confident.
Below is a graph of the models' self-reported confidence (horizontal axis) versus their actual accuracy (vertical axis). The dotted diagonal line represents the ideal situation, where confidence matches actual accuracy. The actual data is below the diagonal line, which indicates that the models tend to overestimate their own accuracy.
The second method is to ask the same question 100 times and analyze the relationship between the frequency of a particular answer and its accuracy: returning the same answer more frequently suggests that the model is more confident in that answer.
The graph below shows the relationship between consistency (vertical axis) and accuracy (horizontal axis) of answers to the same question. This graph shows that answers that appear more frequently tend to be more accurate, and in particular, o1-preview (diagonal line circle) is plotted close to the diagonal, which shows that it has the best balance between consistency and accuracy. This means that the more frequently the model outputs an answer with confidence, the more likely it is to actually be the correct answer.
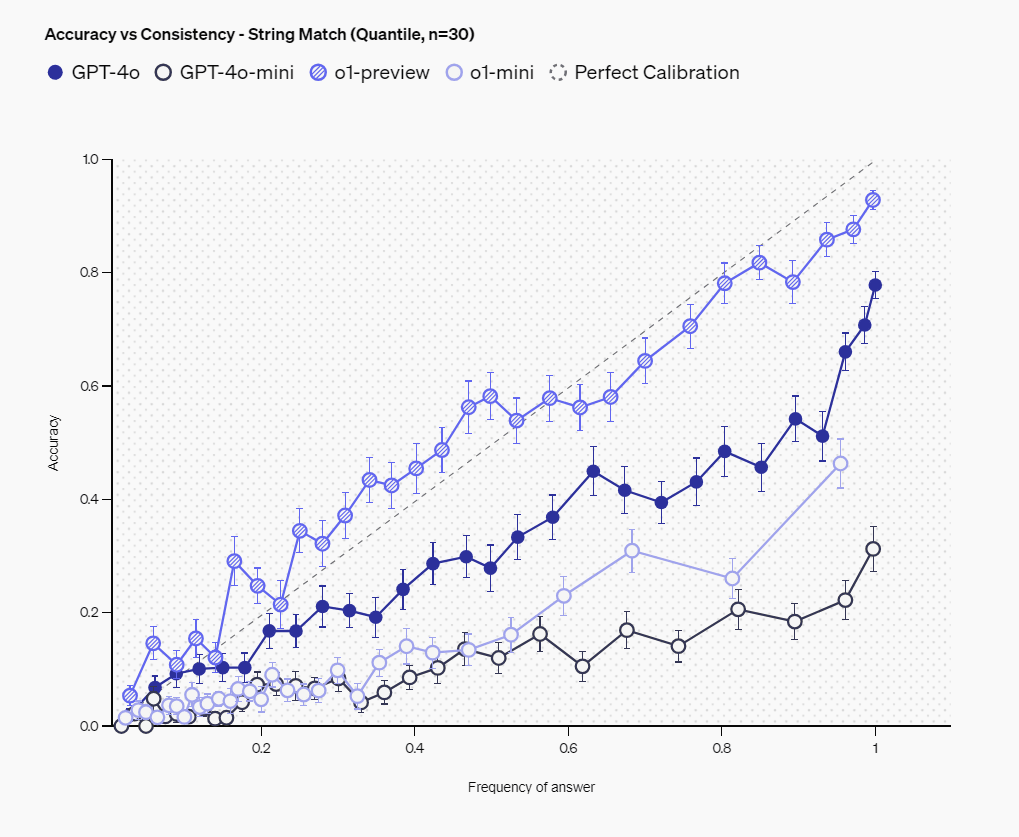
The measurements show that larger models such as o1-preview and GPT-4o show better calibration than smaller models. However, for all models, the reported confidence tends to exceed the actual accuracy, indicating that there is a lot of room for improvement in this area. We also found that o1-preview in particular performed well in terms of the correlation between answer consistency and accuracy, reaching a level where answer frequency and accuracy are almost equivalent.
OpenAI evaluates SimpleQA as a simple but challenging benchmark, but it has the limitation of measuring only short fact-checking questions with a single verifiable answer, and the correlation with the factuality of long answers remains an unexplored research topic at present. In addition, OpenAI aims to promote research on more reliable AI by open-sourcing SimpleQA, and is calling on researchers to evaluate the factuality of language models and provide feedback.
SimpleQA has been released as open source and the repository is available on GitHub .
Related Posts: