OpenScholar, an AI model specialized in researching scientific papers, surpasses GPT-4o in benchmarks, expected to greatly improve the efficiency of scientific research

In recent years, the use of AI in scientific research has become increasingly important, with the release of the AI model '
Ai2 OpenScholar
https://openscholar.allen.ai/
Ai2 OpenScholar: Scientific literature synthesis with retrieval-augmented language models | Ai2
https://allenai.org/blog/openscholar
OpenScholar: The open-source AI that's outperforming GPT-4o in scientific research | VentureBeat
https://venturebeat.com/ai/openscholar-the-open-source-ai-thats-outperforming-gpt-4o-in-scientific-research/
In scientific research, it is important to understand the content and issues of previous research, but with the huge amount of scientific papers and literature published every day, it takes a lot of effort just to keep up with the latest research in your field. To reduce this burden on scientists, OpenScholar is an AI model that finds relevant papers in response to user queries and generates answers based on their content.
OpenScholar is trained on a dataset of over 45 million papers and approximately 240 million corresponding sentence pairs from Semantic Scholar , an academic literature search service developed by the Allen Institute for AI, and uses iterative self-feedback to improve the model's output.
You can get a good idea of how the demo web version of OpenScholar is actually used in the video below.
Ai2 OpenScholar Demo - YouTube
First, search for previous research.

In the web version of OpenScholar's submission form, enter 'Has anyone tried to scale up the retrieval corpora of retrieval-augmented LMs to trillion tokens?' and click the submit button.

After waiting for a few seconds, papers related to the content I entered and a summary of that content were generated. The papers were appropriately cited in the text, and a list of references was provided at the end.

Hover over the link of a cited

The next step is to search for a dataset.

I typed, 'Can you suggest good benchmarks to evaluate long-context language models, ideally involving longer 100k tokens?'
Sure enough, it showed me a benchmark that met my criteria within just a few seconds.
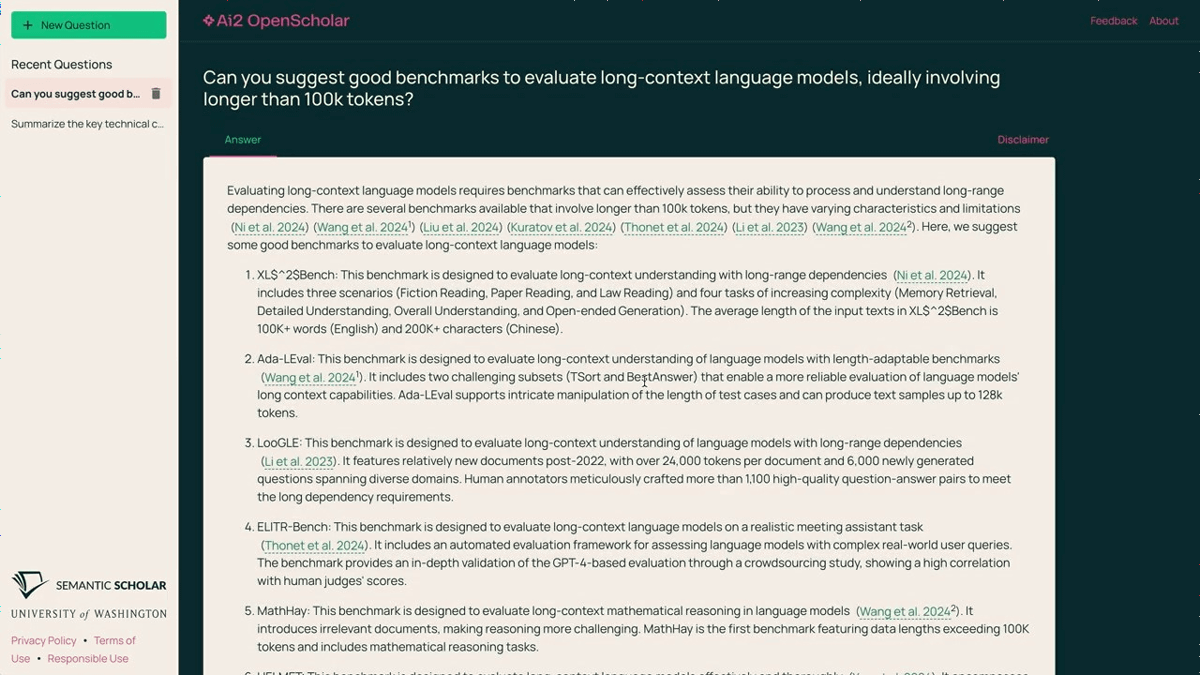
What would normally take a significant amount of time can be completed in a fraction of the time using OpenScholar.

You can also ask about a specific paper.

Enter 'Summarize the key technical contributions and empirical findings of the following paper:

It gave me a concise summary of the necessary parts of a long paper.

Next, I'll ask a question about robotics algorithms.

Enter 'I want to learn about lazy search algorithms for robotics. Suggest 3-4 papers.'

Four papers on lazy search algorithms were introduced.

We can also ask a more general question: 'Is two layer
The research team used the new benchmark for scientific questions, OpenScholarQABench, to compare the performance of OpenScholar with large-scale language models such as Meta's Llama-3-8B and GPT-4o. As a result, it was found that OpenScholar outperformed GPT-4o and other models with a much larger number of parameters in response accuracy and citation accuracy. In particular, for open-ended questions, GPT-4o and other models cited inaccurate or non-existent papers in 80-95% of cases, while OpenScholar cited real papers at a high rate.
With only 8 billion parameters and an architecture focused on researching scientific literature, OpenScholar is a much more cost-effective option for research institutions in developing countries and researchers with limited budgets. Furthermore, when we applied the OpenScholar dataset and generation pipeline based on GPT-4o, we confirmed that the quality was further improved.
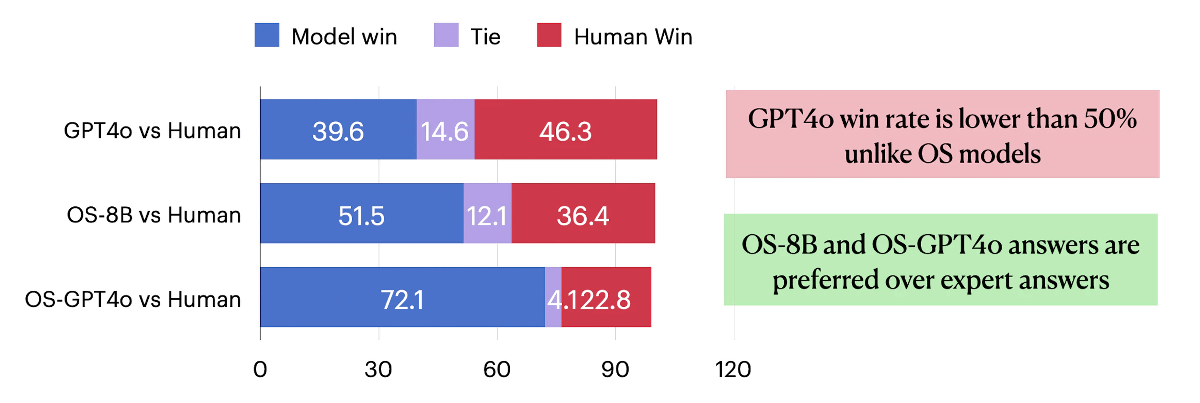
The graph below shows the results of asking experts in computer science, physics, biomedicine, etc. whether they preferred answers output by GPT-4o or OpenScholar or answers written by humans. The percentage of experts who preferred GPT-4o's answers was 39.6%, while the percentage of experts who preferred OpenScholar's answers was 51.5%, surpassing human answers. In addition, OpenScholar's answers based on GPT-4o were preferred by more than 70% of experts.
One limitation of OpenScholar is that the dataset is limited to open access papers, so in fields where paid papers are the majority, it is highly likely that the papers necessary for answering the question will not be cited. In addition, there are cases where the system makes inaccurate citations, which seems to be a hallucination that exists in most language models, or fails to cite representative papers for the question.
Nevertheless, OpenScholar is an important step forward in AI-based scientific research, and it is expected that even more efficient AI systems will be built on it. All OpenScholar code, training data, benchmark results, etc. are publicly available on GitHub and Hugging Face. At the time of writing, the web version is for demonstration purposes only and only supports computer science questions and papers.
GitHub - AkariAsai/OpenScholar: This repository includes the official implementation of OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs.
https://github.com/AkariAsai/OpenScholar
OpenScholar_V1 - a OpenScholar Collection
https://huggingface.co/collections/OpenScholar/openscholar-v1-67376a89f6a80f448da411a6
Related Posts:






in AI, Video, Software, Web Service, Science, Posted by log1h_ik