OpenAI launches BrowseComp, a highly challenging benchmark to measure AI web search capabilities

AI agents that can collect information on the Internet and generate answers are appearing one after another. OpenAI has recently announced a benchmark called ' BrowseComp ' that can measure the web search capabilities of AI agents.
BrowseComp: a benchmark for browsing agents | OpenAI
Tests to measure web search ability are also included in the benchmark ' SimpleQA ' announced by OpenAI in October 2024, but browsing functions such as GPT-4o already have capabilities beyond the range that can be measured by SimpleQA. Therefore, OpenAI developed BrowseComp as a benchmark tool that can measure the ability to find 'complex and hard-to-find information' on the Internet. BrowseComp is an abbreviation for 'Browsing Competition'.
BrowseComp contains 1266 questions that are difficult but easy to grade. Each question is designed by a human trainer to meet the following criteria:
Condition 1: Confirm that the problem cannot be solved by 'GPT-4o', 'OpenAI o1', or 'early versions of Deep research'.
Condition #2: Human trainers conduct five searches on search engines and verify that the answers do not appear on the first page of search results.
Condition 3: Create a problem that a human cannot solve within 10 minutes. Have another trainer try it, and if more than 40% of the trainers get the answer right, fix the problem.
The questions and answer examples are as follows. It is difficult to derive the correct answer from the question, but on the other hand, you can verify whether the answer is correct or not by searching the web a few times.
Question: Papers presented at EMNLP conferences between 2018 and 2023. The first author received his undergraduate degree from Dartmouth College and the fourth author received his bachelor's degree from the University of Pennsylvania.
Answer: Frequency Effects on Syntactic Rule Learning in Transformers, EMNLP 2021
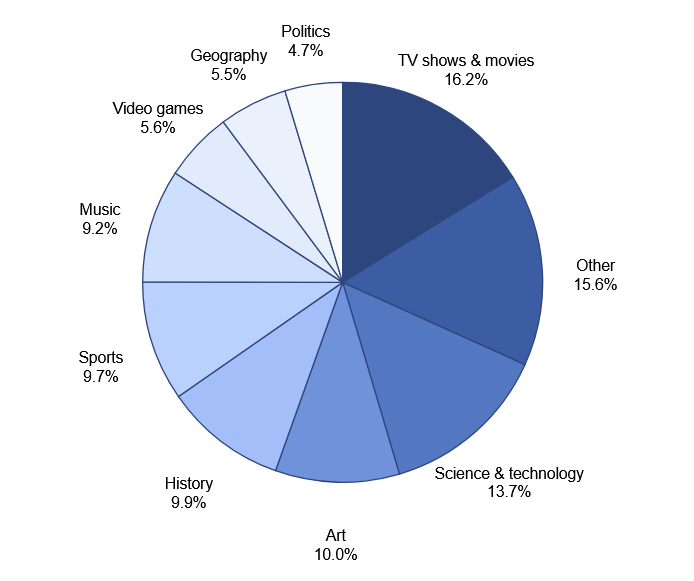
The breakdown of the problem categories included in BrowseComp is as follows: 16.2% 'TV shows and movies', 13.7% 'science and technology', 10.0% 'art', 9.9% 'history', 9.7% 'sports', 9.2% 'music', 5.6% 'games', 5.5% 'geography', 4.7% 'politics', and 15.6% 'other'.
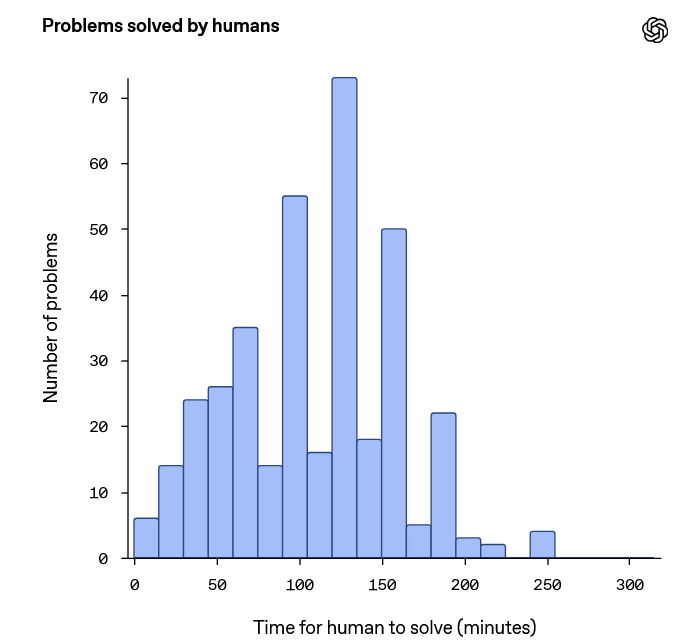
As a result of having humans solve 1,255 of the problems included in BrowseComp, 367 problems (29.2% of the total) could be solved within two hours, and 317 problems (86.4% of the problems that could be solved) were answered correctly. Below is a graph summarizing the time it took to answer. Some problems could be solved in a few minutes, while others took several hours.
The results of solving the BrowseComp problem with OpenAI's AI model are as follows. The inference model OpenAI o1 only got 9.9% correct, but Deep research, an AI agent for web search, recorded a relatively high correct answer rate of 51.5%.
| Model | Correct answer rate |
|---|---|
| GPT-4o | 0.6% |
| GPT-4o web search function | 1.9% |
| GPT-4.5 | 0.9% |
| OpenAI o1 | 9.9% |
| Deep research | 51.5% |
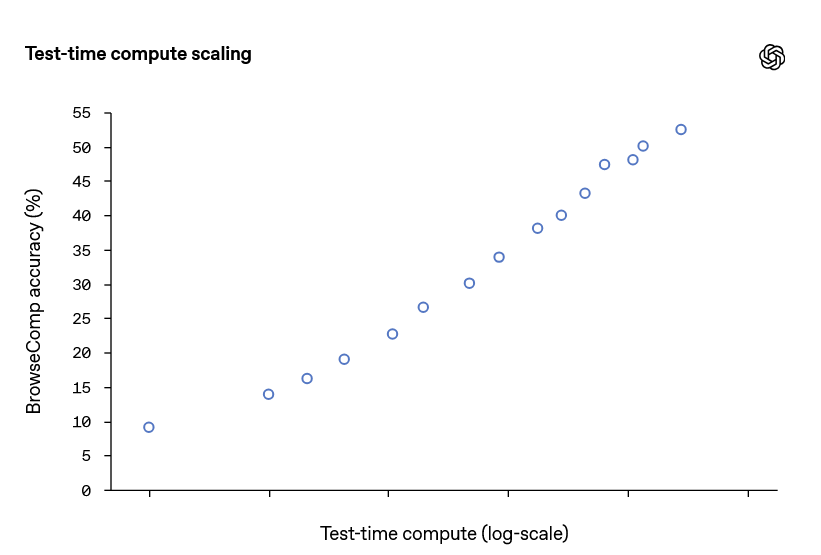
Below is a graph showing the change in BrowseComp score when the computer resources used for inference are increased for the same AI agent. The more costly the inference, the higher the score.
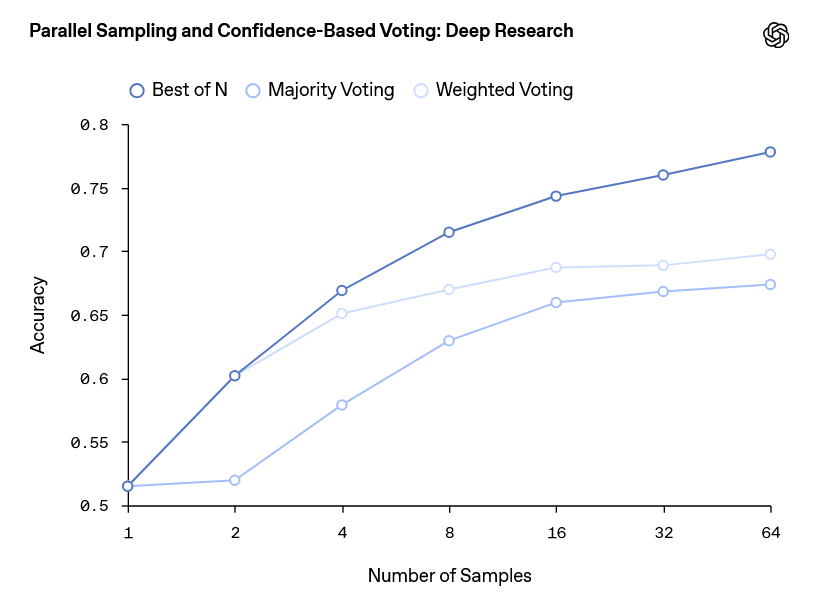
The graph below shows the scores when the answer generation in Deep Research was performed multiple times and the representative answer was selected under the conditions of 'the answer with the highest confidence score (Best of N)', 'the answer selected by majority vote weighted by confidence score (Majority Voting)', and 'the most frequently output answer (Majority Voting)'. The horizontal axis shows the 'number of times answers were generated'. For each answer selection method, the accuracy rate improved as the number of times generation increased, and the best answer selection method was 'Best of N'.
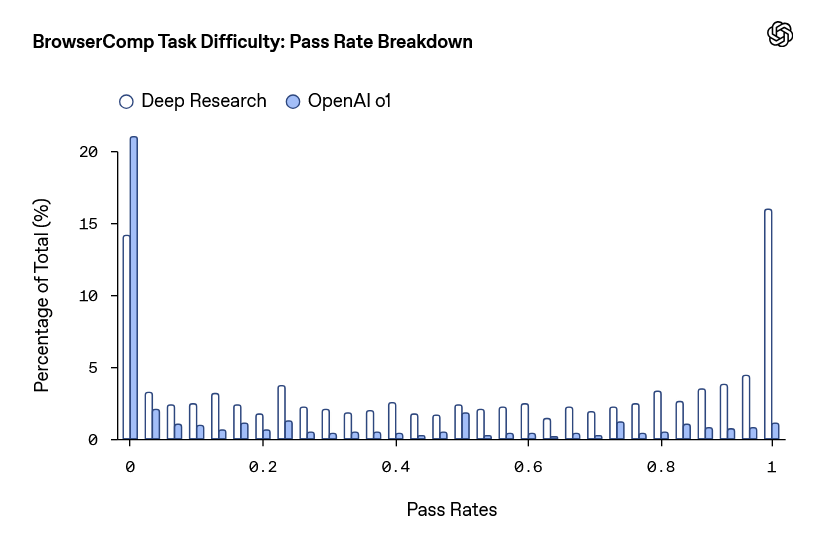
In addition, to analyze the difficulty of the BrowseComp problems, we solved each problem 64 times in Deep Research and investigated the accuracy rate. As a result, 16% of the problems had a 100% correct answer rate, and 14% had a 0% correct answer rate. In addition, for problems with a 0% correct answer rate, we gave the task of 'searching for evidence on the web to support the correct answer after being presented with the correct answer,' and as a result, we succeeded in finding evidence in most problems. From these results, OpenAI concludes that 'BrowseComp can measure not only search ability, but also the ability to flexibly reconstruct searches and the ability to extract fragmentary clues from multiple sources and assemble answers.'
In addition, BrowseComp is a test that deals with questions that have only one correct answer, and it is unclear to what extent the score of BrowseComp correlates with the 'ability to solve free-response questions'.
BrowseComp is included in OpenAI's benchmark tool set 'simple-evals'.
GitHub - openai/simple-evals
https://github.com/openai/simple-evals
You can also find a paper about BrowseComp at the following link:
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
(PDF file) https://cdn.openai.com/pdf/5e10f4ab-d6f7-442e-9508-59515c65e35d/browsecomp.pdf

Related Posts:







