




「人間の子供が聞く量の単語」のみで大規模言語モデルを新たにトレーニングするチャレンジ「BabyLM Challenge」が開催中、誰でも挑戦可能
チャットAIに用いられる大規模言語モデルの性能は、パラメーター数やトレーニングデータの量が増えるほど上昇するというのが通説ですが、この通説に反して「少ないデータ量で高性能な言語モデルを作成する」というチャレンジ「BabyLM Challenge」が開催されています。
babylm.github.io
https://babylm.github.io/
大規模言語モデルの作成においては、一番最初に事前学習と呼ばれる工程があります。事前学習では文章を入力して続く単語を当てるというトレーニングが行われ、大規模言語モデルはこのトレーニングを通して文章を作成できるようになります。
トレーニングに用いる単語の量は年々増加しており、2018年のBERTは30億語のデータでトレーニングされましたが、2019年のRoBERTaは300億語、2020年のGPT-3は2000億語、そして2022年のChinchillaは1.4兆語のデータでトレーニングされました。こうして大規模言語モデルの性能も向上してきたのですが、下図左端に表示されているように、人間は生まれてから13年間で1億語しか聞いていないのに言葉を自由に操る能力を身につけることができます。
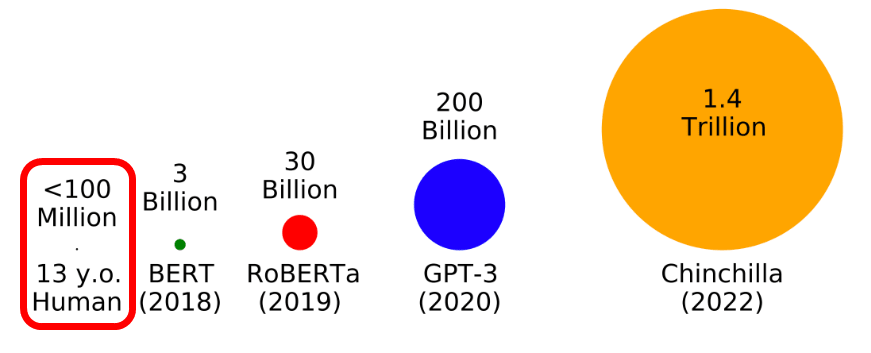
そこで自然言語処理の研究をする若い学者のグループが2023年1月に立ち上げたのが「BabyLM Challenge」というわけ。BabyLM Challengeは13歳の子供が聞いてきた単語の量である1億語にデータ量を制限して言語モデルをトレーニングするというチャレンジです。
主催グループによると、BabyLM Challengeはデータ効率を向上させる新たな手法の実験場として利用でき、ここで登場した新たな手法がデータ量の少ない言語のモデリング手法を改善したり、自然言語処理で一般的に使われるようになる可能性を秘めているとのこと。
また、BabyLM Challengeではデータ量が1億語に制限されているだけでなく、トレーニング用のデータがスピーチなど話し言葉の書き起こしとなっています。人間が受け取るのと同じ種類・量のデータを利用して言語モデルをトレーニングする方法を研究することで人間が言語を効率的に習得できる理由を理解するのにも役立つと述べられています。
BabyLM Challengeには誰でも参加することが可能で、トレーニング用のデータセットはGitHubにアップロードされています。なお、モデルおよび結果の提出期限は2023年7月15日で論文提出の期限は2023年8月1日とのことです。
・関連記事
独自のデータセットでGPTのような大規模言語モデルを簡単にファインチューニングできるライブラリ「Lit-Parrot」をGoogle Cloud Platformで使ってみた - GIGAZINE
ChatGPTなどに使われる大規模言語モデルを従来のシステムよりも15倍高速・低コストで学習できる「DeepSpeed-Chat」をMicrosoftが公開 - GIGAZINE
人間による評価をシミュレートすることで高速&安価にチャットAIの学習を進められるツール「AlpacaFarm」がスタンフォード大学のチームによって作成される - GIGAZINE
「GPT-3」などの最新言語モデルが自然に他者の心を推察する能力である「心の理論」を獲得していたという研究論文 - GIGAZINE
Metaの大規模言語モデル「LLaMA」がChatGPTを再現できる可能性があるとさまざまなチャットAI用言語モデルのベンチマーク測定で判明 - GIGAZINE
無料で商用利用もOKな完全オープンソースの大規模言語モデルを開発するプロジェクト「RedPajama」がトレーニングデータセットを公開 - GIGAZINE
オープンソースの大規模言語モデル開発プロジェクト「RedPajama」が最初のモデル「RedPajama-INCITE」をリリース、無料で商用利用も可能 - GIGAZINE
無料で商用利用も可能なオープンソースの大規模言語モデル「Dolly 2.0」をDatabricksが発表 - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article Anyone can challenge 'BabyLM Challenge',….