




無料で商用利用も可能なオープンソースの大規模言語モデル「Dolly 2.0」をDatabricksが発表

2023年3月に大規模言語モデル(LLM)「Dolly」を公開したDatabricksが、わずか2週間で、初のオープンソースの命令追従型LLMだという「Dolly 2.0」を発表しました。
Free Dolly: Introducing the World's First Open and Commercially Viable Instruction-Tuned LLM - The Databricks Blog
https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm

Databricks releases Dolly 2.0, the first open, instruction-following LLM for commercial use | VentureBeat
https://venturebeat.com/ai/databricks-releases-dolly-2-0-the-first-open-instruction-following-llm-for-commercial-use/
Dolly 1.0のリリース時に最も多かった質問は「商用利用できますか?」という内容でした。Dolly 1.0はスタンフォード大学のLLM「Alpaca」開発チームがOpenAI APIを用いて作成したデータセットで30ドル(約4000円)かけてトレーニングされており、データセットには「OpenAIと競合するモデルの作成は許可しない」という規約を含むChatGPTによる出力が含まれていたことから、残念ながら商用利用はできませんでした。
Alpacaのほか、バークレーAIリサーチの「Koala」や、GPU非搭載のノートPCでも動かせる軽量チャットAI「GPT4ALL」、ChatGPTに匹敵する性能だという「Vicuna」などがこの規約の制限を受け、商用利用を禁じられています。
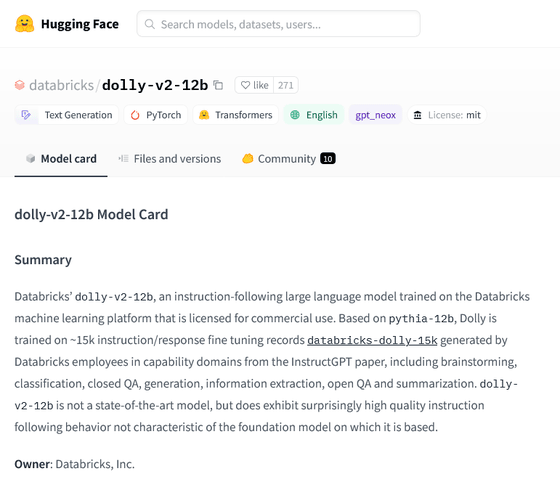
そこでDatabricksが「商用利用できるような新たなデータセットを」と生み出したのがDolly 2.0です。Dolly 2.0はEleutherAI pythiaモデル ファミリーをベースとした120億パラメーターのLLMで、Databricksの従業員の間でクラウドソーシングされたデータセットに従って、人間が生成した新しい高品質な命令のみで微調整されています。
Dolly 2.0の調整においては、OpenAIがInstructGPTモデルを1万3000個の命令&回答データセットでトレーニングした点に着目し、その数を目指して全く新たな命令&回答データセットを用意しました。DatabricksにはLLMに高い興味を持つ従業員が5000人以上いたため、このタスクに向けてコンテストを行った結果、1週間で1万5000件のサンプル収集に成功したとのこと。
Dolly 2.0はHugging Faceでダウンロード可能。
databricks/dolly-v2-12b · Hugging Face
https://huggingface.co/databricks/dolly-v2-12b
また、Dolly 2.0の微調整に用いられた、人間が生成した高品質なプロンプトのペア1万5000個が含まれるデータセット「databricks-dolly-15k」はCreative Common 3.0ライセンスのもとで、誰でも利用・変更・拡張が可能です。
dolly/data at master · databrickslabs/dolly · GitHub
https://github.com/databrickslabs/dolly/tree/master/data
・関連記事
Twitterへ投稿するツイート内容を大規模言語モデルのGPTに事前監査してもらえるChrome拡張「Tweetaudit-GPT」レビュー - GIGAZINE
「GPT-4」発表、司法試験上位10%&日本語でもめちゃくちゃ高性能&画像処理もプログラミングも可能で「初代iPhoneと同等の衝撃」とも評される - GIGAZINE
GPT-4やChatGPTを開発するOpenAIが「AIの安全性に対するアプローチ」を発表 - GIGAZINE
・関連コンテンツ





in ソフトウェア, Posted by logc_nt
You can read the machine translated English article Databricks announces 'Dolly 2.0'….