




ChatGPTに画像生成機能を搭載してチャット形式で画像生成可能な「Visual ChatGPT」をMicrosoftが開発

OpenAIが提供する対話型AI「ChatGPT」は非常に高い性能から裁判での使用や文章の執筆などで用いられています。しかし、ChatGPTは会話用に開発されたAIであり、画像生成機能は搭載されていません。そんな中、新たにマイクロソフトリサーチアジアのチェンフェイ・ウー氏らの研究チームがChatGPTに画像生成機能を搭載した「Visual ChatGPT」を発表しました。
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
(PDFファイル)https://arxiv.org/pdf/2303.04671.pdf

GitHub - microsoft/visual-chatgpt: Official repo for the paper: Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
https://github.com/microsoft/visual-chatgpt
Microsoft Research Introduces Visual ChatGPT That Incorporates Different Visual Foundation Models Enabling Users To Interact With ChatGPT - MarkTechPost
https://www.marktechpost.com/2023/03/10/microsoft-research-introduces-visual-chatgpt-that-incorporates-different-visual-foundation-models-enabling-users-to-interact-with-chatgpt/
Stable Diffusionのような画像生成AIでは文章や参考画像をプロンプトとして入力することで、好みの画像を生成できます。しかし、画像生成AIを使いこなすには、「モデルデータ」「解像度」「サンプリング回数」など多様な要素を適切に設定する必要がある他、複雑なプロンプトの構築など、面倒な操作を実行する必要があります。
そこでウー氏らの研究チームは、従来のChatGPTを基にした「Visual ChatGPT」と呼ばれる対話型AIを開発しました。Visulal ChatGPTは、入力されるテキストやプロンプトを介して対話を行うことで、画像の生成を行うことが可能です。
ウー氏らの研究チームはChatGPTにStable DiffusionやInstructPix2PixなどのVFMを追加しました。さらにChatGPTとVFMの機能間のギャップを埋めるために「入力・出力形式を指定し、各VFMの機能についてChatGPTに通知すること」「さまざまなVFMの使用履歴や優先順位などを参考に画像処理を行うこと」「png画像や深度画像などのさまざまな視覚情報を言語形式に変換することで、ChatGPTの処理を支援すること」といったプロンプトマネージャーを導入しています。
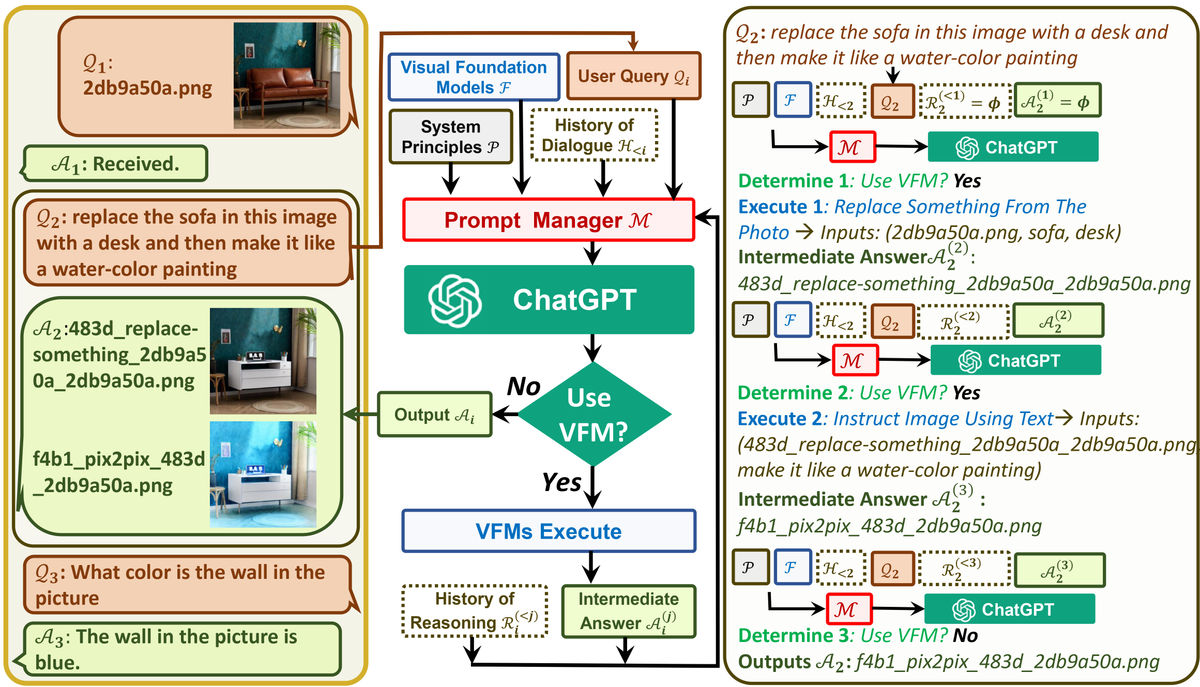
Visual ChatGPTのアーキテクチャ概要が以下の画像です。Q1で示されたソファの画像をQ2では「画像中のソファを机に置き換え、さらに水彩風にして」と問いかけています。ユーザーからのクエリを受け取ると、ChatGPTのシステムの説明や対話履歴を含め、さまざまなVFMの中から選択したツールを使用するためのプロンプトを作成し、ChatGPT上に入力します。
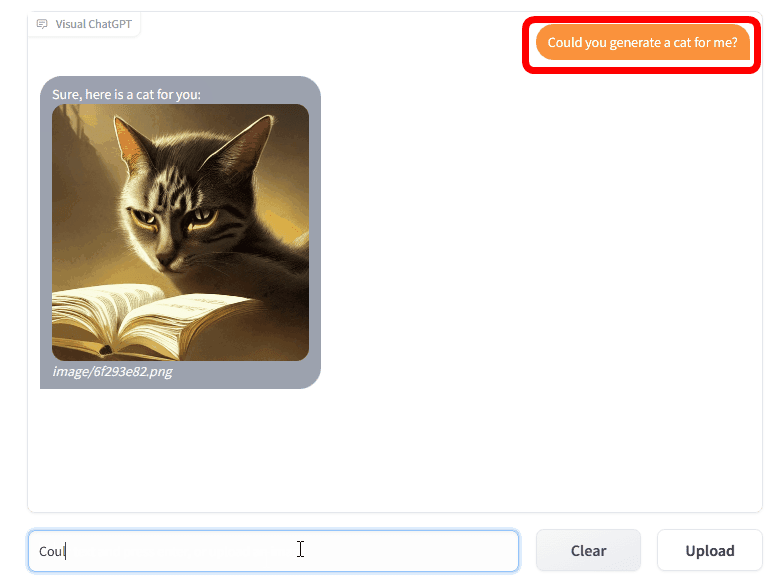
Visual ChatGPTのデモがこんな感じ。Visual ChatGPTに「Could you generate a cat for me? (猫の画像を生成してくれますか)」と入力すると、Visual ChatGPTは即座に猫の画像を生成します。
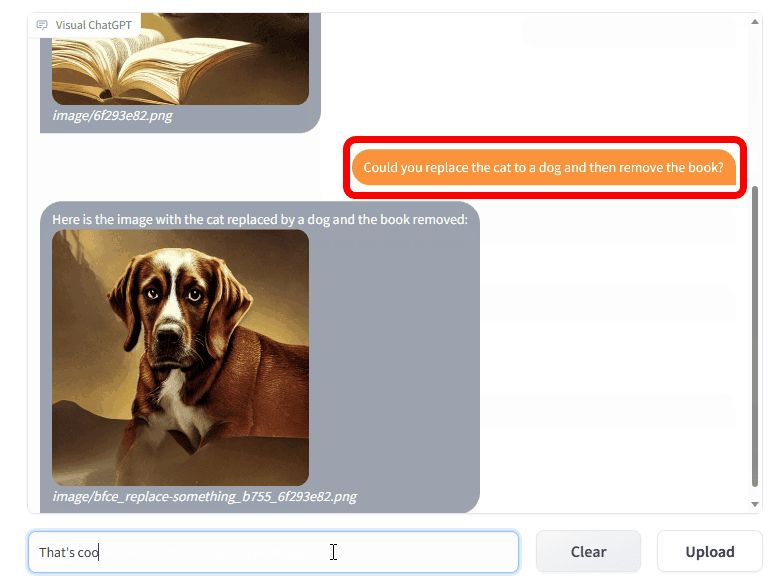
さらに「could you replace the cat to a dog and then remove a book? (猫を犬に変えて、本を除いた画像を生成してくれますか)」と入力すると、本が取り除かれた、犬だけの画像が生成されます。
また「That's cool! Could you generate the canny edge of this image? (この画像をCannyエッジ検出することはできますか)」と尋ねると、エッジ検出された犬の画像が出力されます。
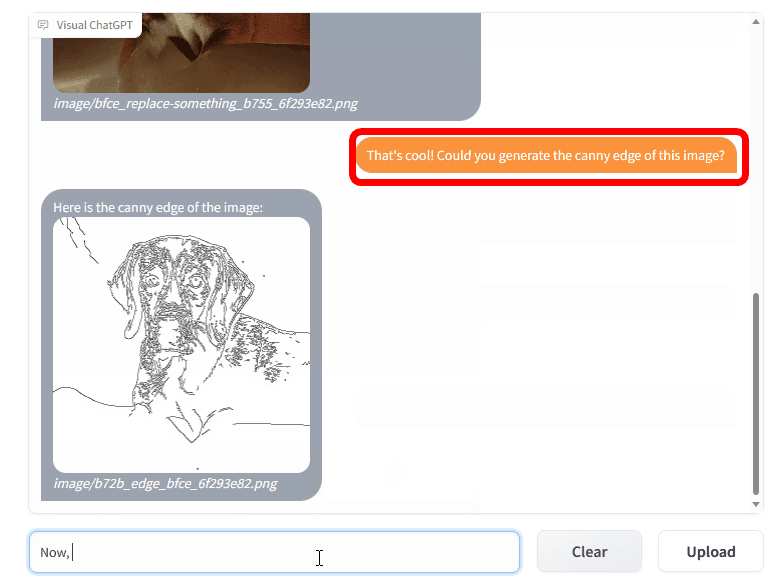
続いて「エッジ検出された犬の画像を基に、黄色い犬を生成して下さい」と入力すると、要求通り黄色い犬の画像が生成されます。
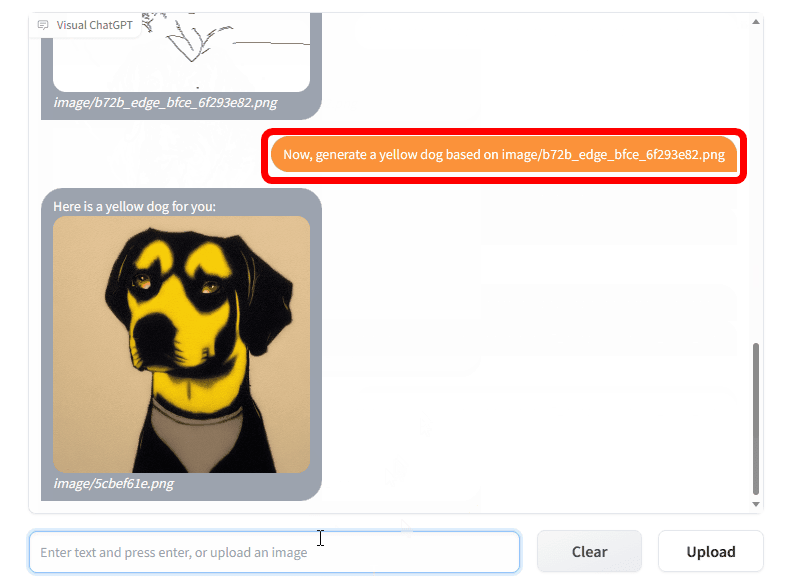
Visual ChatGPTのようなツールを使用することで、テキストから画像を生成する際の障壁を軽減することや、さまざまなAIツールに相互運用性を追加することも可能だとされています。
ウー氏らの研究チームは、「VFMの失敗やプロンプトの不規則性によって、満足のいく生成結果をもたらさない可能性があり、懸念材料となっています」と述べ、「生成される画像が人間の意図と一致するような単一の自己修正モジュールが必要です。さらに、このモジュールの導入によって生成時間が増加する可能性があるため、今後も調査を行う予定です」と述べています。
ウー氏らが開発したVisual ChatGPTのソースコードはGitHubで公開されています。なお、Visual ChatGPTの使用にはChatGPTのAPIが必要です。
GitHub - microsoft/visual-chatgpt: Official repo for the paper: Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
https://github.com/microsoft/visual-chatgpt
・関連記事
OpenAIがチャットAI「ChatGPT」を1000トークン当たり0.2円でアプリに導入できるAPI提供開始 - GIGAZINE
人間並みの精度で会話が可能な対話型AI「ChatGPT」は何が画期的なのか? - GIGAZINE
文章だけでなく視覚的なコンテンツも理解してIQクイズに答えられるAI「Kosmos-1」をMicrosoftが発表、汎用人工知能の開発に前進 - GIGAZINE
人間のように思考する「汎用人工知能(AGI)」が実現するまでのロードマップ - GIGAZINE
言語の壁を超えて複雑な文章や画像も理解できる新検索アルゴリズム「MUM」をGoogleが発表 - GIGAZINE
「初代iPhoneと同等の衝撃」と評されるOpenAIの次世代言語モデル「GPT-4」が2023年3月発表予定、画像認識機能や多言語対応の強化が実現か - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article Microsoft develops 'Visual ChatGPT' that….