画像生成AI「Stable Diffusion」で絵柄や構図はそのままで背景や続きを追加する「アウトペインティング」などimg2imgの各Script使い方まとめ
2022年8月に一般公開された画像生成AI「Stable Diffusion」をユーザーインターフェース(UI)で操作できる「AUTOMATIC1111版Stable Diffusion web UI」は非常に多機能である上にものすごい勢いで更新されており、Stable DiffusionのUIツールとしては記事作成時点で決定版といえる存在です。そんなAUTOMATIC1111版Stable Diffusion web UIでは、画像から画像を生成できる「img2img」に便利なScriptが用意されているので、実際に使ってみました。
GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
AUTOMATIC1111版Stable Diffusion web UIをローカル環境あるいはGoogle Colaboratoryに導入する方法は以下の記事にまとめられています。
画像生成AI「Stable Diffusion」を4GBのGPUでも動作OK&自分の絵柄を学習させるなどいろいろな機能を簡単にGoogle ColaboやWindowsで動かせる決定版「Stable Diffusion web UI(AUTOMATIC1111版)」インストール方法まとめ - GIGAZINE
また、AUTOMATIC1111版Stable Diffusion web UIの基本的な使い方は以下の記事を読むとよくわかります。
画像生成AI「Stable Diffusion」で崩れがちな顔をきれいにできる「GFPGAN」を簡単に使える「Stable Diffusion web UI(AUTOMATIC1111版)」の基本的な使い方 - GIGAZINE
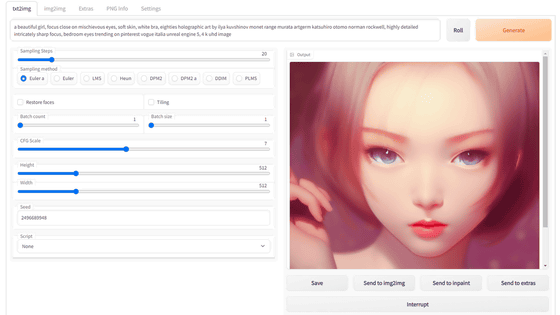
そして、img2imgの基本的な使い方は以下の記事でまとめ済み。
画像生成AI「Stable Diffusion web UI(AUTOMATIC1111版)」で元画像と似た構図や色彩の画像を自動生成したり指定した一部だけ変更できる「img2img」の簡単な使い方まとめ - GIGAZINE
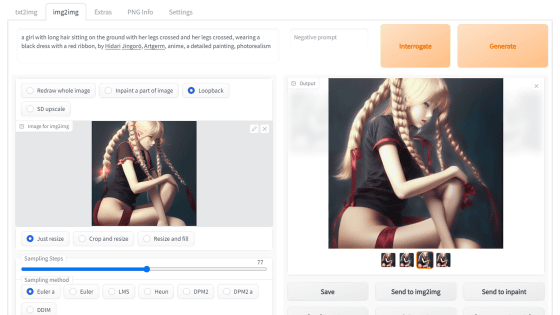
◆アウトペインティング
アウトペインティングとは、自然言語による説明文を加えることで、同じスタイルのビジュアル要素を追加したり、新しい方向にストーリーを展開したりと、本来の画像の枠を超える内容を描き足す作業です。人工知能研究団体・OpenAIが開発する「DALL・E 2」にも、アウトペインティングが搭載されています。
画像生成AI「DALL・E 2」で絵柄はそのままに背景や続きを追加する新機能「アウトペインティング」が登場 - GIGAZINE

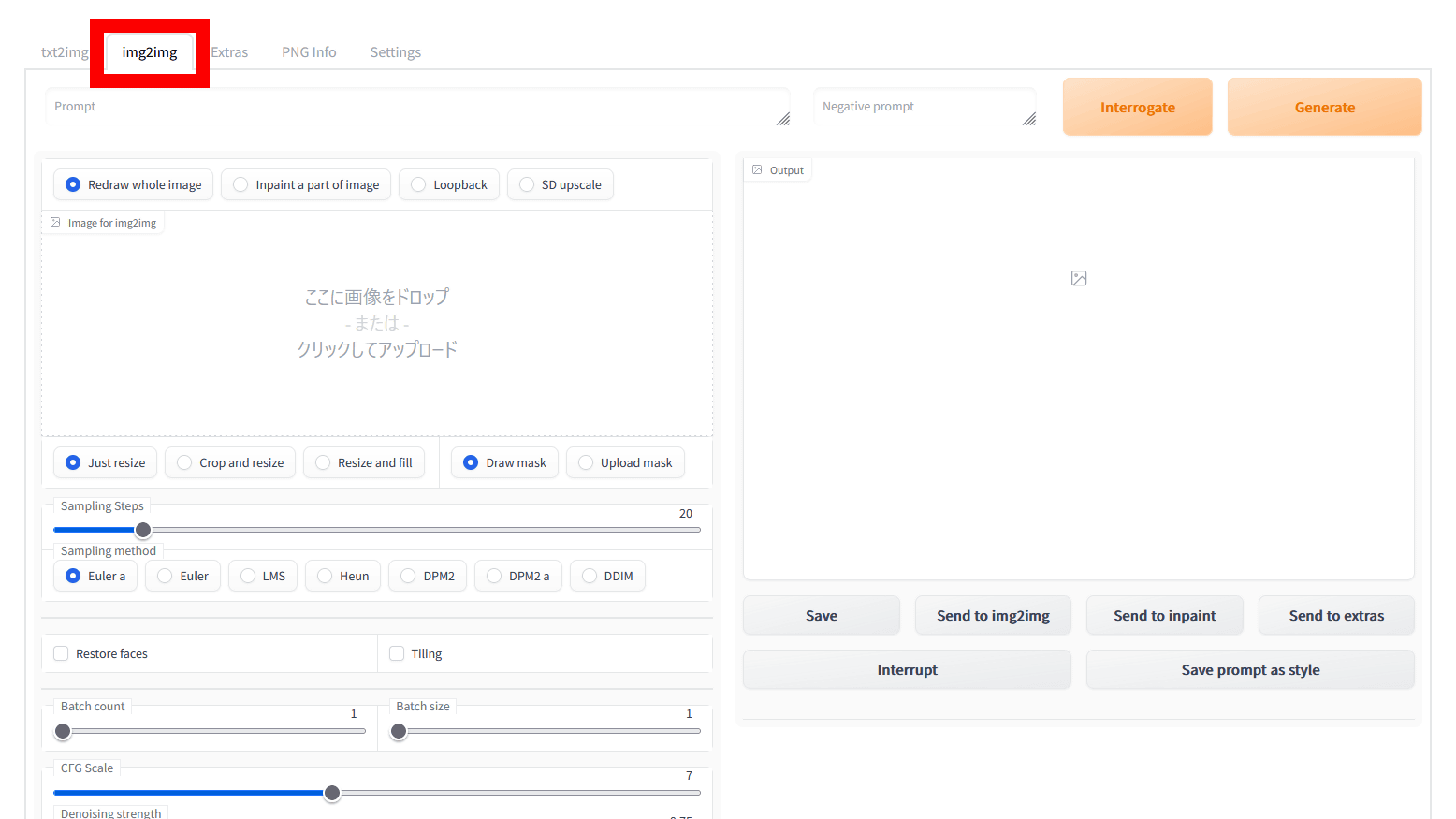
AUTOMATIC1111版Stable Diffusion web UIを起動してUIにアクセスしたら、「img2img」のタブをクリック。
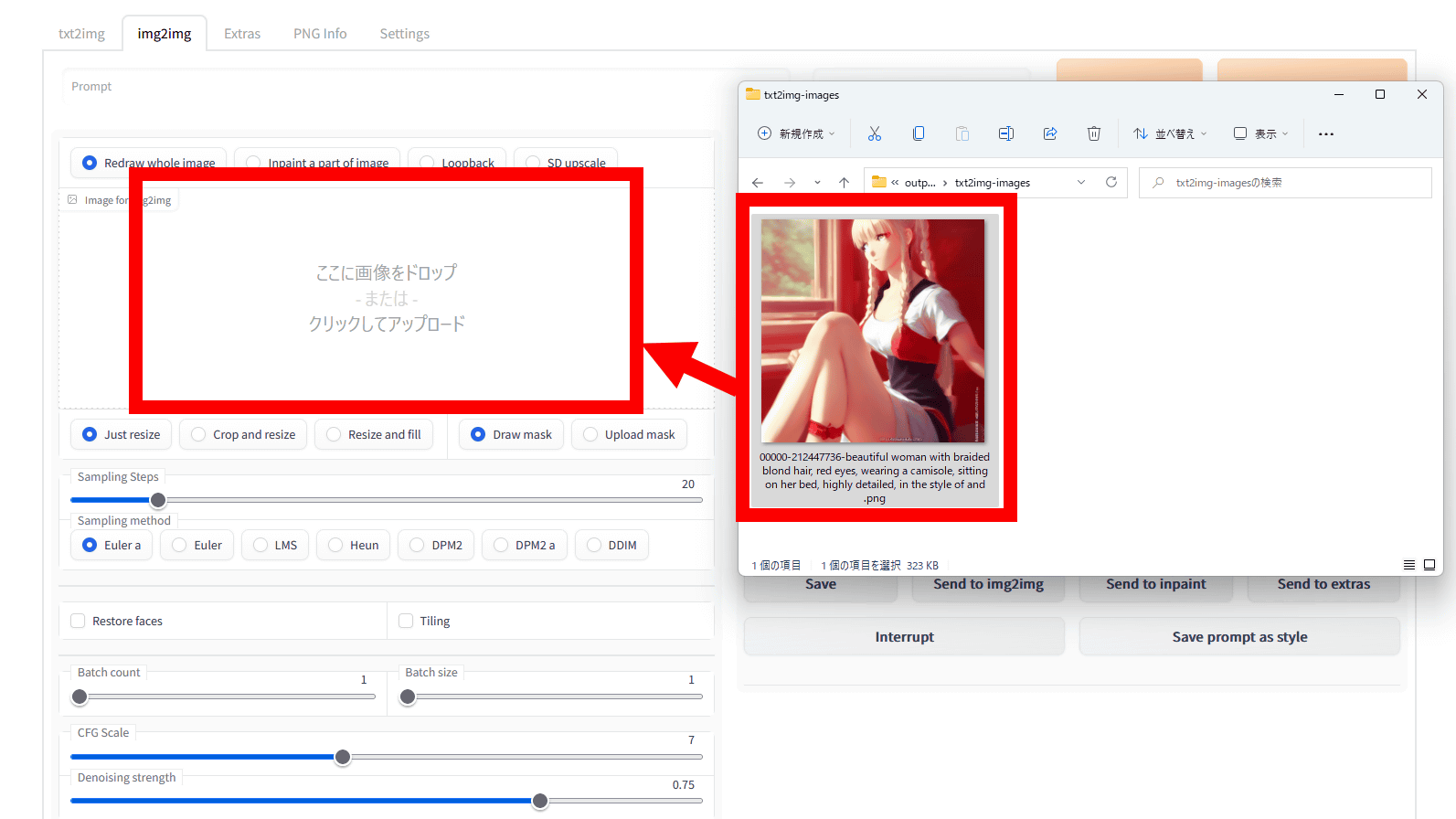
アウトペインティングしたい画像を「Image to img2img」欄に直接ドラッグ&ドロップするか、「Image to img2img」欄をクリックして選択します。
なお、このStable Diffusionで作った画像を使う場合、プロンプト・Sampling Steps・Sampling method・CFG Scale・Seedを生成時と同じ条件にすると成功率が高くなるので、生成時と同じになるように設定します。
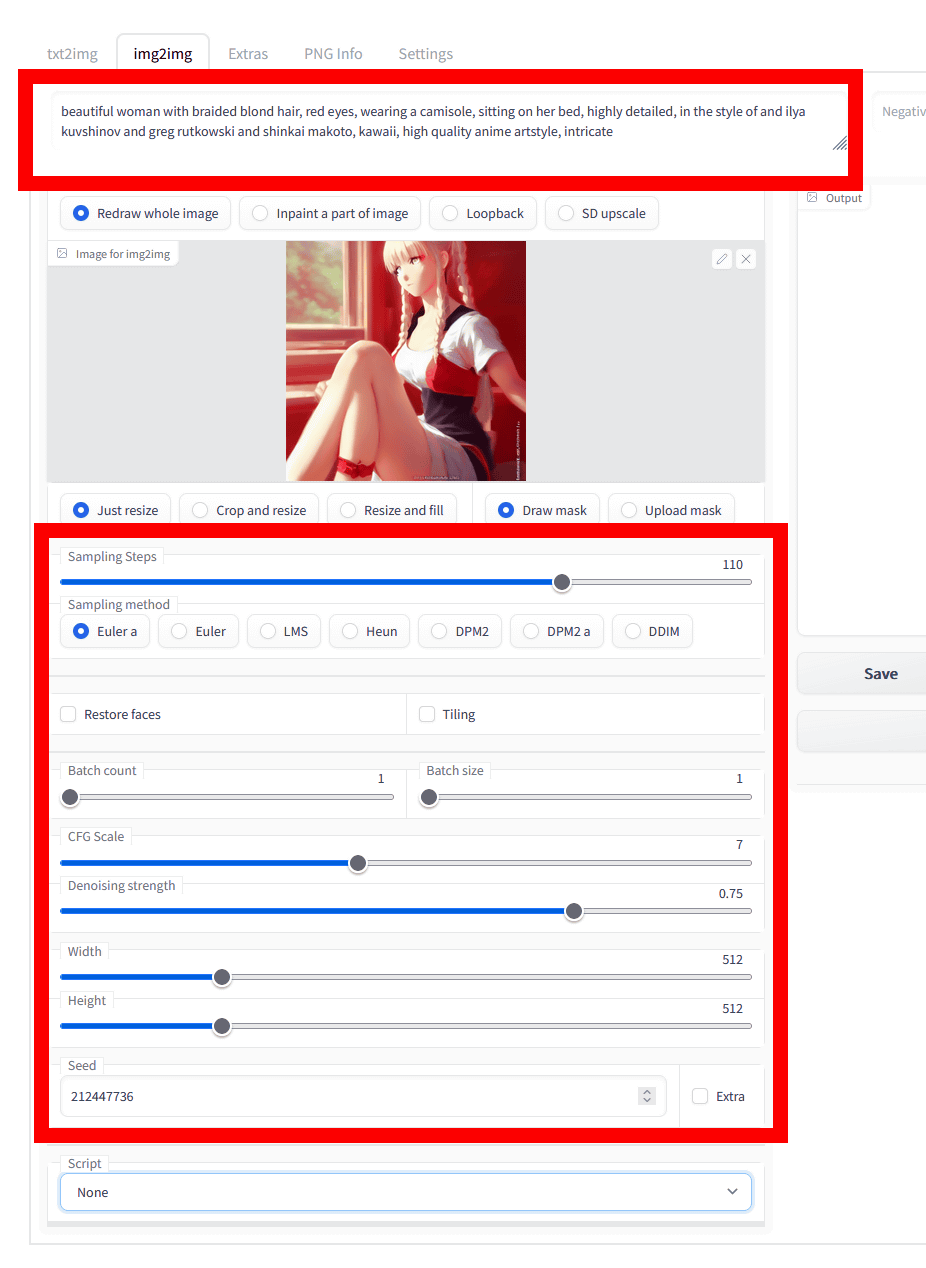
もし設定が分からない場合は、PNG infoでチェック。

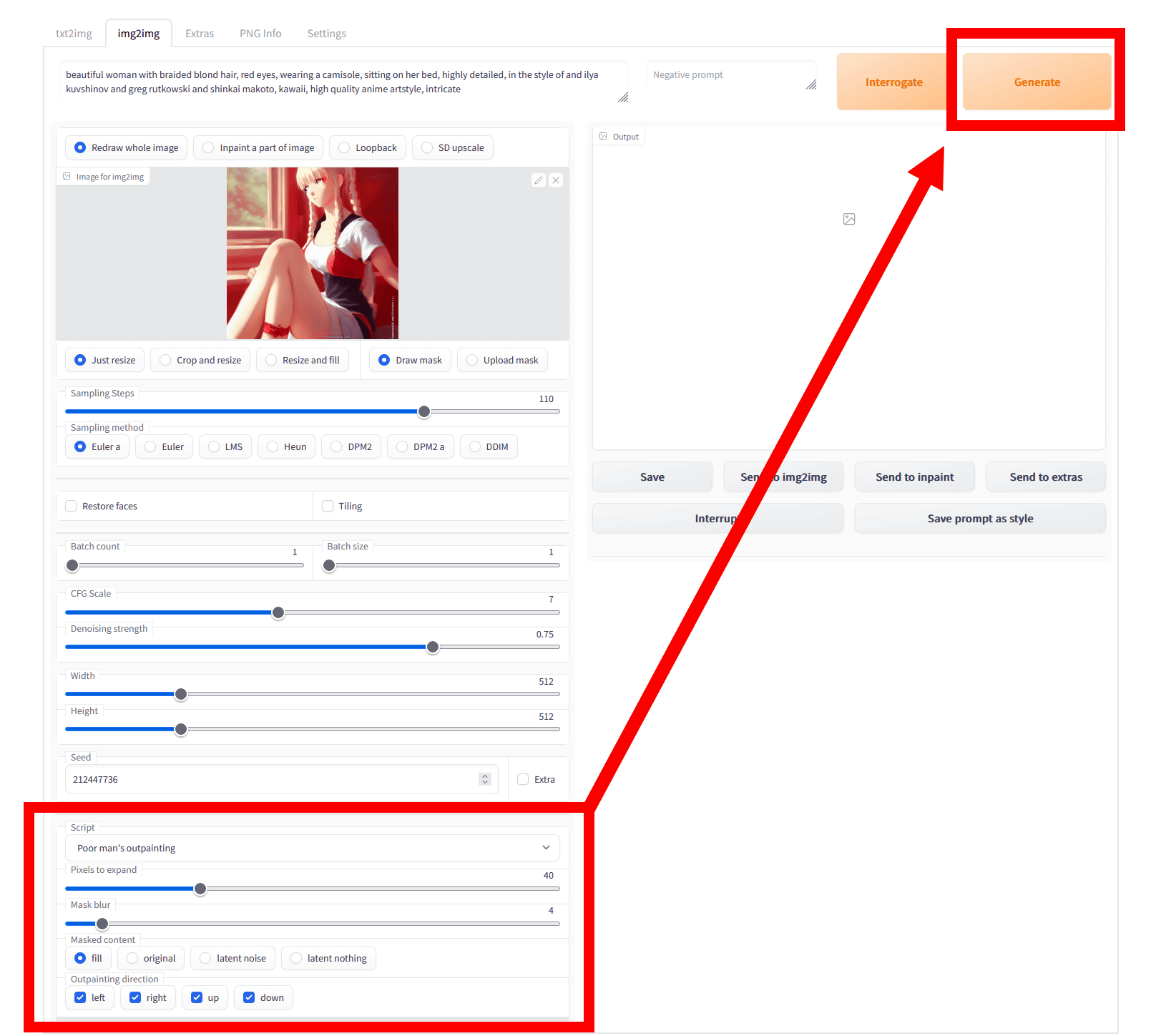
そして、設定欄の一番下にある「Script」のプルダウンで「Poor man's outpainting」を選択し、設定したら「Generate」をクリックします。その下にある設定欄の意味は以下の通り。
・Pixels to expand:画像の拡張量(ピクセル単位)。今回は40ピクセルに設定。
・Mask Blur:元画像と拡張部分の境い目をどこまでぼかすかを決める。数字が高いと、境界線がよりあいまいになる。今回は4に設定。
・Masked content:拡張した部分を埋める方法。fill、original、latent noize、latent nothingの4種類あり。
・Outpainting Direction:画像を拡張する方向を選ぶ。
元画像がこれ。

そして、「fill」でアウトペインティングするとこんな感じの画像が出力されました。左腕の先がやや怪しくありますが、元画像では切れていた頭部やお尻が自然に描き足されています。

「Original」でアウトペインティングすると、拡張した部分は黒一色に塗られていました。

「latent noize」だと、左足と左手の先が生成されていました。また、色合いは少し異なりますが、奥にある窓枠も描き足されています。

「latent nothing」は「latent noize」とほぼ同じ内容。ただし、女の子が座っている場所がやわらかな曲線になっていたり、左手のブレスレットがなくなっていたりと、細かいところが異なりました。

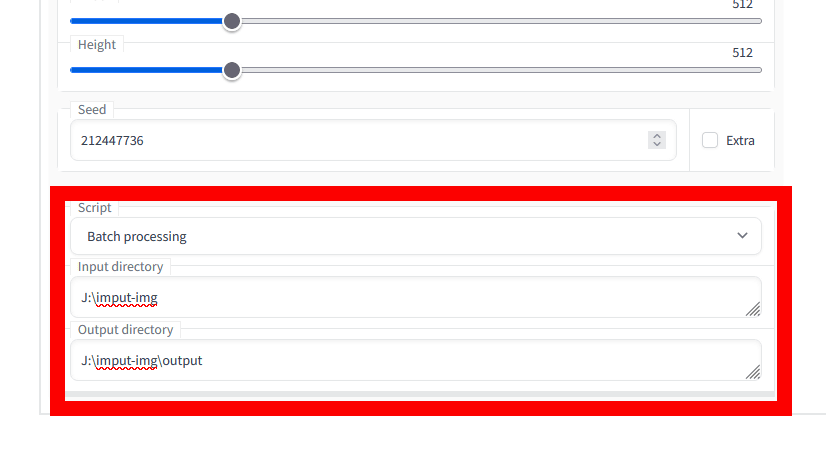
◆Batch processing
Batch processingでは、入力画像を複数読み込むことができます。「Input directory」に入力したい画像を収めたフォルダのパスを、「Output directory」に画像の出力先フォルダのパスを入力して指定します。
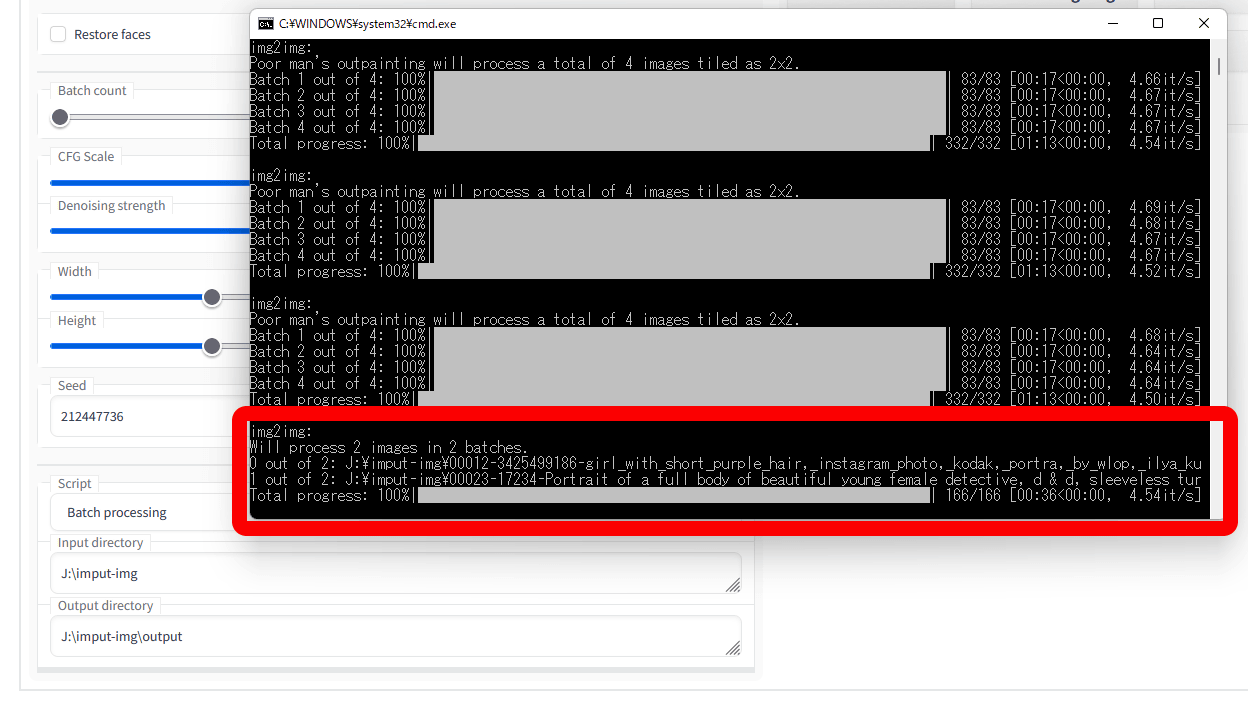
コマンドプロンプトをみると、入力ディレクトリに入っている2枚の画像からimg2imgが行われました。img2imgに入力したい画像が複数ある場合、Batch processingを使えば、その都度「Image to img2img」で画像を選択し直す必要がなくなります。ただし、Batch processingでは生成の設定がすべての画像で共通になります。
◆img2img alternative test
img2imgは追加で画像を入力することで、Stable Diffusionで画像生成中に行われるノイズ除去プロセスの方向性を固め、生成される画像のブレ幅を狭くすることができます。それでもやはりノイズ強度によっては元の画像から遠くかけ離れた画像が生成されることもあります。そこで、元の画像により近い結果を出力するための方法がオンライン掲示板サイト・Redditで提案され、これを参考に導入されたのが「img2img alternative test」です。
A better (?) way of doing img2img by finding the noise which reconstructs the original image : StableDiffusion
https://www.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/

img2imgで画像を読み込んだ状態で、「Script」から「img2img alternative test」を選択。その下の「Original Prompt」に、入力した画像を生成した時のプロンプトを入力します。
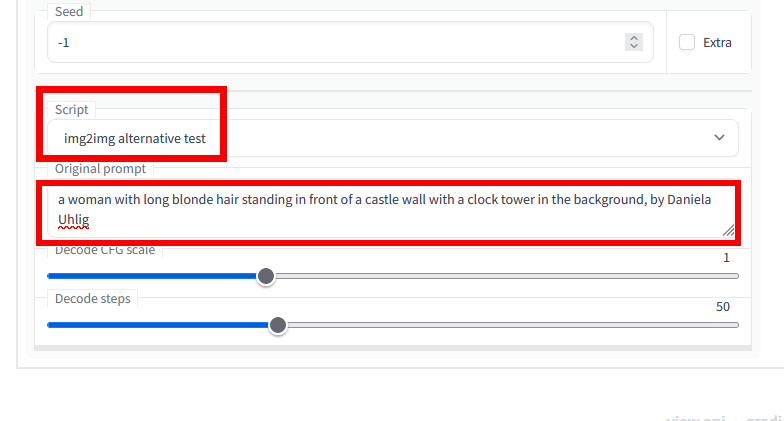
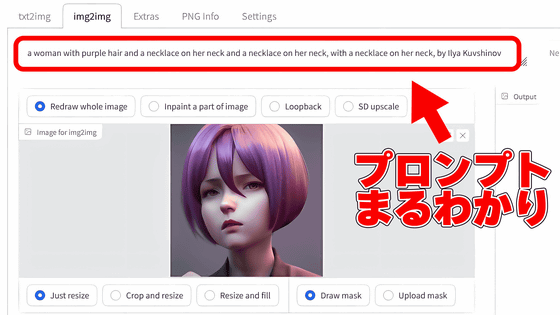
もしプロンプトがわからない、あるいはAIで生成した画像ではないという場合は、AUTOMATIC1111版Stable Diffusion web UIに搭載されている「CLIP Interrogator」という機能を使えば、プロンプトを解析することも可能です。
画像生成AI「Stable Diffusion」で自動生成された画像からどのようなプロンプト・呪文だったのかを分解して表示できる「CLIP interrogator」の使い方 - GIGAZINE
「Image to img2img」欄の上にあるプロンプト入力欄に、キーワードを入れて「Generate」をクリック。今回は「red hair」と入力したところ、髪の真っ赤な女性の画像が出てきました。
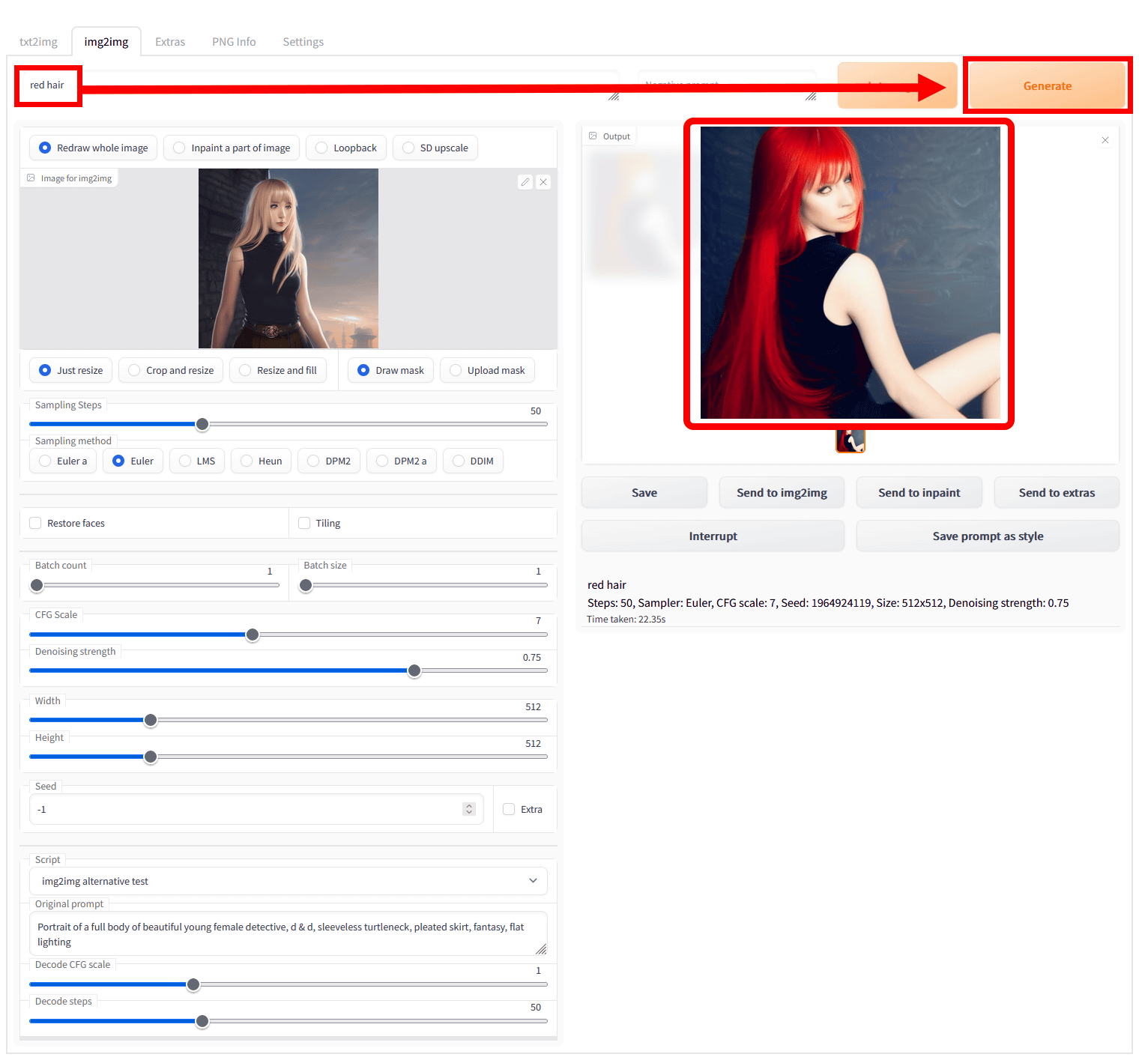
女性がよりリアルになってポーズは変わっていますが、髪型や顔のメイク、着ている服装、背景の雰囲気は元画像をちゃんと踏襲しています。

◆Prompts matrixとX/Y plot
AUTOMATIC1111版Stable Diffusion web UIでは、さらに「Prompt from file」「Prompt matrix」「X/Y plot」を使うことができます。
これらの機能は文字列から画像を生成する「txt2img」でも使うことが可能。「Prompt matrix」「X/Y plot」については、以下の記事で詳しく解説しています。なお、「Prompt from file」はプロンプトを文字列入力ではなくCSVファイル読み込みで行うモードです。
画像生成AI「Stable Diffusion」でプロンプト・呪文やパラメーターを変えるとどういう差が出るか一目でわかる「Prompt matrix」と「X/Y plot」を「Stable Diffusion web UI(AUTOMATIC1111版)」で使う方法まとめ - GIGAZINE

「Prompt matrix」は、プロンプトで複数の要素を「,」で区切って関連させるところを、「|」で区切ることで各要素の有無で組み合わせを行い、その全パターンを一度に出力します。「Script」から「Prompt matrix」を選択肢、「Put variable parts at start of prompt(プロンプトの最初に変数を置く)」のチェックを入れ、プロンプトを入力したら「Generate」をクリック。
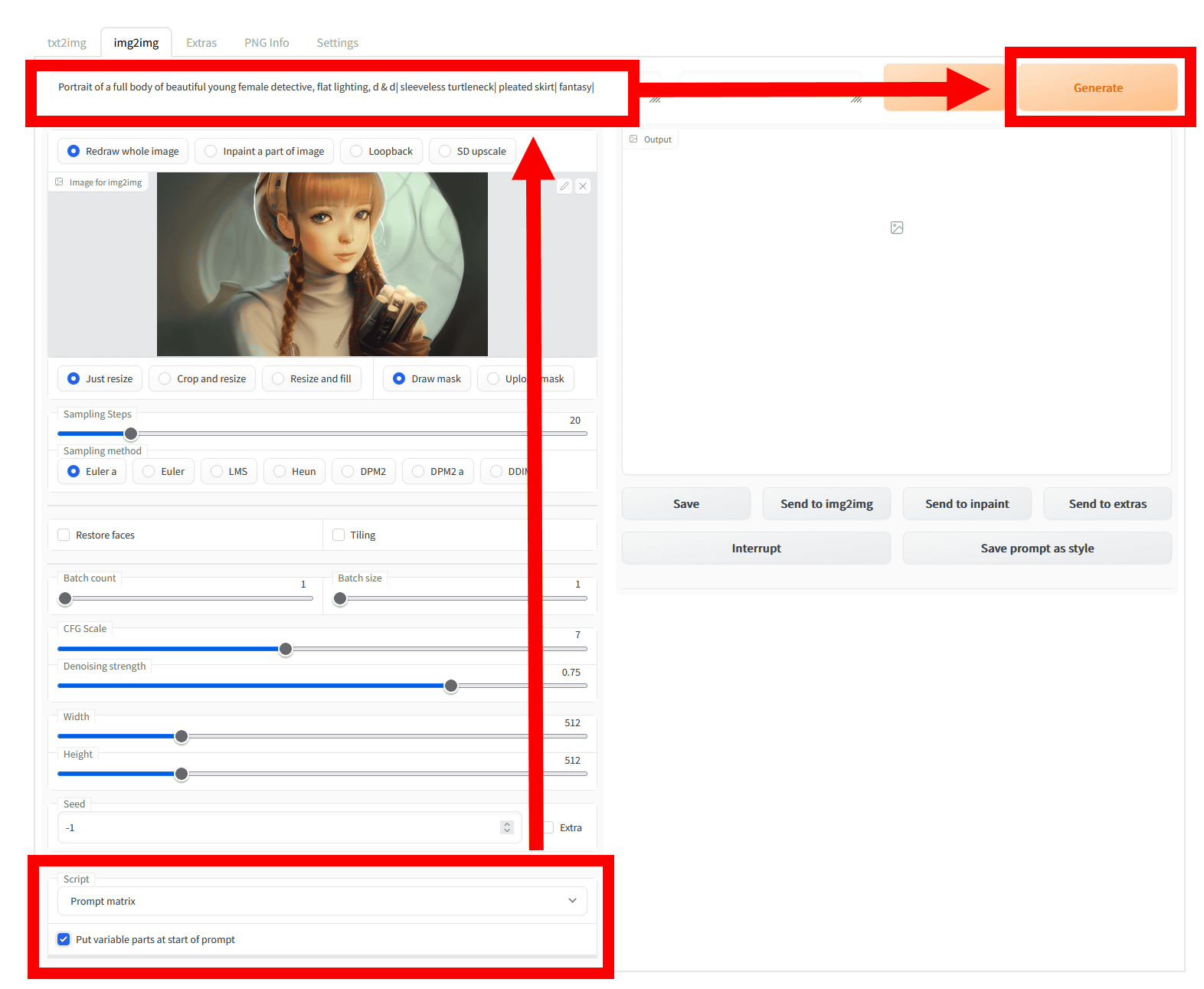
出力した結果はこんな感じ。元画像からかなりかけ離れてしまっていますが、各条件に応じて髪型や服のデザイン、ポーズが異なるものになっているとわかります。

そして、「X/Y plot」は設定した2要素で複数パターンを用意し、その組み合わせとなる画像すべてを生成するモード。今回はX typeで「Seeds(シード値)」に1645・94672・5463を、Y typeで「Denoising(ノイズ除去強度)」に0.2・0.6・1.0を割り当ててみました。
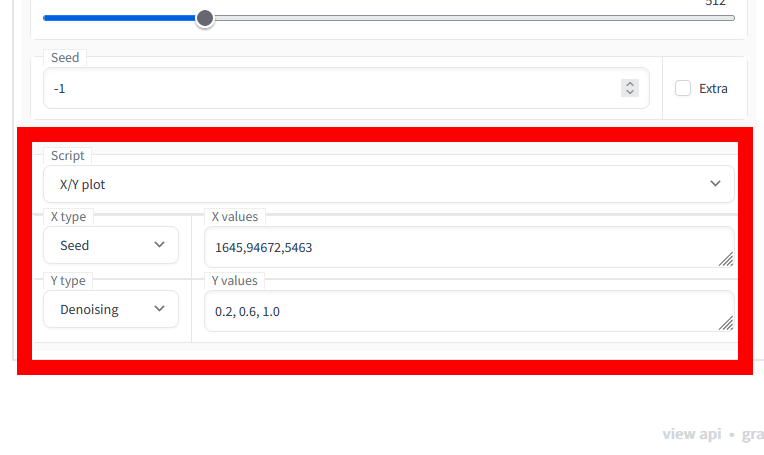
生成された画像のマトリックスはこんな感じ。バッチサイズは2なので、1つの組み合わせごとに2枚ずつ生成されています。ノイズ除去強度0.2ではシード値が違ってもほぼ元画像と同じものが生成されました。しかし、ノイズ除去強度を0.6にあげると、構図やポーズは同じですが、タッチはかなり変わっていることがわかります。そして、ノイズ除去強度1.0になると、元画像から完全に離れた上に平面的なイラストに変化。実際にX/Yplotを使って比較することで、ノイズ除去強度の重要性がよくわかりました。

というわけで次回は「Extras」の内容と、初期値では1つのバッチで16枚ずつしか生成されない画像を一気に爆増させる方法などを予定しています。
<つづく>
・関連記事
画像生成AI「Stable Diffusion」を4GBのGPUでも動作OK&自分の絵柄を学習させるなどいろいろな機能を簡単にGoogle ColaboやWindowsで動かせる決定版「Stable Diffusion web UI(AUTOMATIC1111版)」インストール方法まとめ - GIGAZINE
画像生成AI「Stable Diffusion」で崩れがちな顔をきれいにできる「GFPGAN」を簡単に使える「Stable Diffusion web UI(AUTOMATIC1111版)」の基本的な使い方 - GIGAZINE
画像生成AI「Stable Diffusion」でプロンプト・呪文やパラメーターを変えるとどういう差が出るか一目でわかる「Prompt matrix」と「X/Y plot」を「Stable Diffusion web UI(AUTOMATIC1111版)」で使う方法まとめ - GIGAZINE
画像生成AI「Stable Diffusion」で自動生成された画像からどのようなプロンプト・呪文だったのかを分解して表示できる「CLIP interrogator」の使い方 - GIGAZINE
簡単なスケッチとその説明を入れるだけで画像生成AI「Stable Diffusion」が画像を作ってくれる「Draw Anything」 - GIGAZINE
CPUだけで画像生成AI「Stable Diffusion」を動かせる環境をWindowsへ簡単にインストールできる「Stable Diffusion UI」を使ってみた - GIGAZINE
ついに「CLIP STUDIO PAINT(クリスタ)」で画像生成AI「Stable Diffusion」を動かすプラグインが登場 - GIGAZINE
・関連コンテンツ