




大規模言語モデルで「無限の入力」を受け付けることを可能にする手法「StreamingLLM」が開発される

計算コストやパフォーマンスを維持したまま無限の入力を処理することが可能な大規模言語モデルの手法「StreamingLLM」の論文が2023年9月29日に公開されました。入力が長くなるにつれて最初の方の情報は失われていくため、書籍の要約などのタスクには向いていませんが、対話が長くなってもパフォーマンスを維持したままスムーズに回答をこなすことが可能になっています。
mit-han-lab/streaming-llm: Efficient Streaming Language Models with Attention Sinks
https://github.com/mit-han-lab/streaming-llm
[2309.17453] Efficient Streaming Language Models with Attention Sinks
https://arxiv.org/abs/2309.17453
StreamingLLMによって大規模言語モデルの動作がどう変わるのかを示すムービーが用意されています。
大規模言語モデルで「無限の入力」を受け付けることを可能にする手法「StreamingLLM」のデモムービー - YouTube

モデルのロードにおいてはどちらも同じ動作をします。
大量の質問を用意し、「質問→AIによる回答→質問→AIによる回答→……」を繰り返していきます。
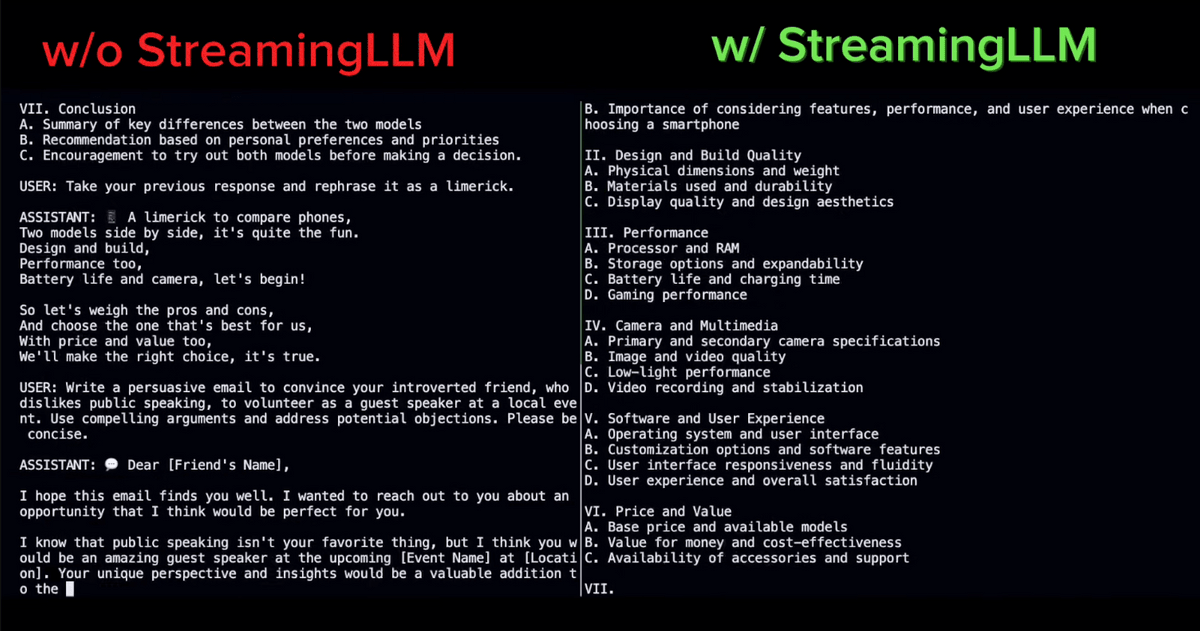
しばらく続けているうちに、StreamingLLMを使用していないモデルは回答が支離滅裂になってしまいました。一方StreamingLLMを使用したモデルは正常に受け答えできています。

その後、StreamingLLMを使用していないモデルはメモリを使い切って停止してしまいましたがStreamingLLMを使用したモデルは動き続けていました。

既存の手法との比較イメージは下図の通り。4つの手法の動作イメージ図とともに、アルゴリズムの時間計算量をO-記法で表示したものと予測の正確性を示すPPL値が表示されています。Lは事前学習のテキストの長さで、Tは何番目のトークンを予測するのかを示しています。
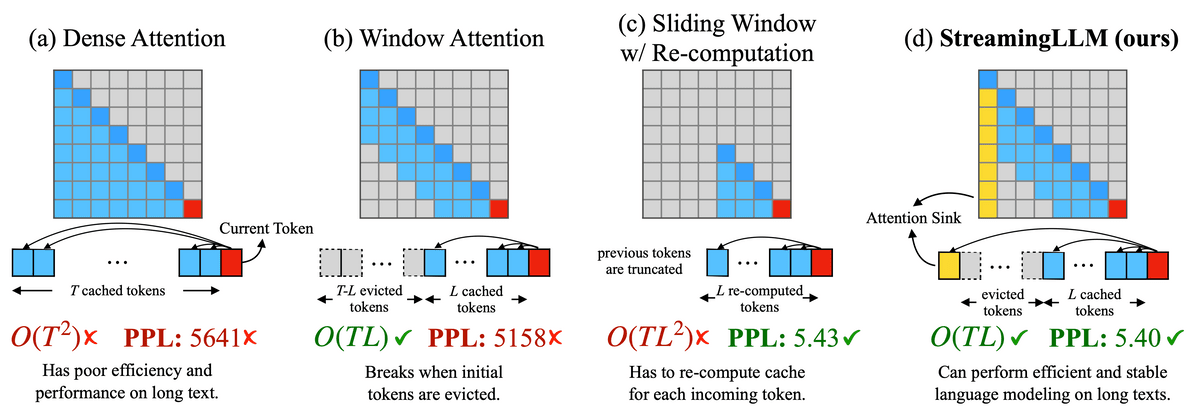
(a)のDense Attentionは時間計算量がTの2乗時間となるほか、メモリを大量に消費します。また、テキストの長さが事前学習のテキストの長さを超えると著しくパフォーマンスが低下してしまいます。
(b)のWindow Attentionは間近のLトークン分のキャッシュのみを保持する仕組みで、時間計算量は抑えられたものの最初のトークンがキャッシュ範囲から外れると一気にパフォーマンスが低下してしまうとのこと。
(c)のSliding Window w/ Re-computationはトークンごとに間近のLトークン分のキャッシュを更新する仕組み。長い文章でも予測の正確性を保つことが可能ですが、計算量は増加してしまいます。
(d)のStreamingLLMが今回開発された仕組みです。論文の著者たちは、(b)のWindow Attentionにおいて一番最初のトークンのキャッシュを保持するとパフォーマンスが回復する現象を発見し、「attention sink」という名前を付けてアテンションの計算に組み込みました。Window Attentionの時間計算量を維持したまま長い文章で良いパフォーマンスを発揮できるとのこと。
StreamingLLMを組み込むことで、「Llama-2」「MPT」「Falcon」「Pythia」などの大規模言語モデルで400万トークン以上の長さの文章を扱うことが可能になります。また、事前学習の際にattention sinkとしてプレースホルダートークンを用意するとさらなる速度の向上が確認できたとのこと。
なお、長大な文章の入力が可能になるとはいえ、コンテキスト長の制限は変更されません。例えばLlama-2を4096トークンのコンテキスト長で事前学習した場合、StreamingLLMを使用した場合でも最大キャッシュサイズは4096トークンのままとなり、足りない部分は中間のトークンを破棄することで対応しています。
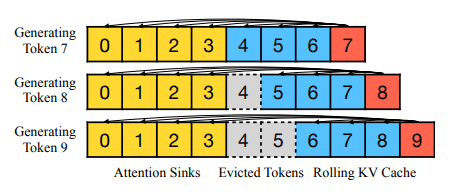
StreamingLLMは長期記憶を強化する仕組みではないため、書籍のような長いテキストの要約タスクをする場合、最後の部分のみを要約する可能性が高いとのこと。一方で、毎日のアシスタントなど、過去のデータ不要でモデルを継続的に動作させたい場合には適した手法です。会話の長さがコンテキスト長を超えた場合でも動作を継続できます。
実際に大規模言語モデルにStreamingLLMを組み込むコードについてはGitHubで公開されているので、気になる人は確認してみて下さい。
・関連記事
本当にオープンソースのライセンスで利用&検証できる大規模言語モデル「Mistral 7B」が登場、「Llama 2 13B」や「Llama 1 34B」を上回る性能のAI開発が可能 - GIGAZINE
Googleが「大規模言語モデルに視覚を与える仕組み」について解説、メルカリと協力して作成したデモも公開 - GIGAZINE
大規模言語モデルの「検閲」を解除した無修正モデルが作成されている、その利点とは? - GIGAZINE
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE
ChatGPTのような高性能言語モデルを生み出した技術はどんな仕組みなのか?をAI企業のエンジニアが多数の図解でゼロから解説 - GIGAZINE
・関連コンテンツ







in 動画, ソフトウェア, Posted by log1d_ts
You can read the machine translated English article A method called ``StreamingLLM''….