




ChatGPTのような高性能言語モデルを生み出した技術はどんな仕組みなのか?をAI企業のエンジニアが多数の図解でゼロから解説

OpenAIが開発したChatGPTをはじめ、さまざまなAIが人間レベルの会話を行ってくれるようになりました。そうしたチャットAIがどのような技術で成り立っているのかをAssemblyAIのエンジニアであるマクロ・ランポニさんが知識ゼロでもわかる丁寧さで解説しています。
The Full Story of Large Language Models and RLHF
https://www.assemblyai.com/blog/the-full-story-of-large-language-models-and-rlhf/
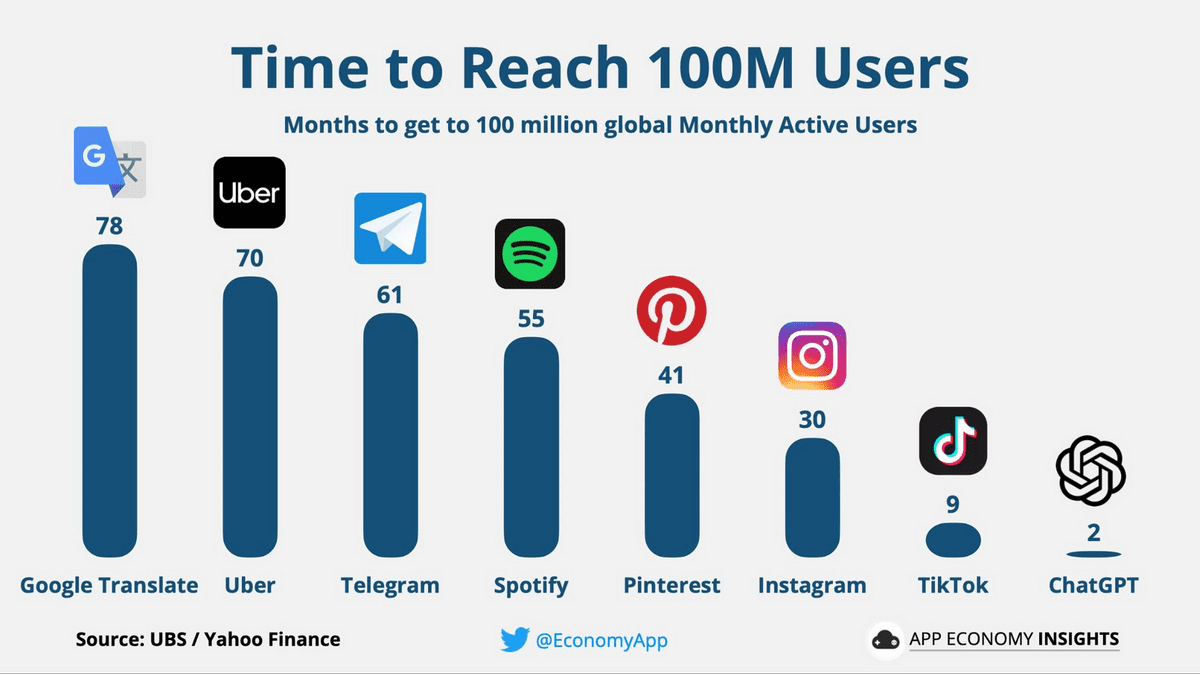
ChatGPTがリリースされてから1億人以上に利用されるまでにかかった月数はなんとたったの2カ月。とんでもないスピードで普及していきました。
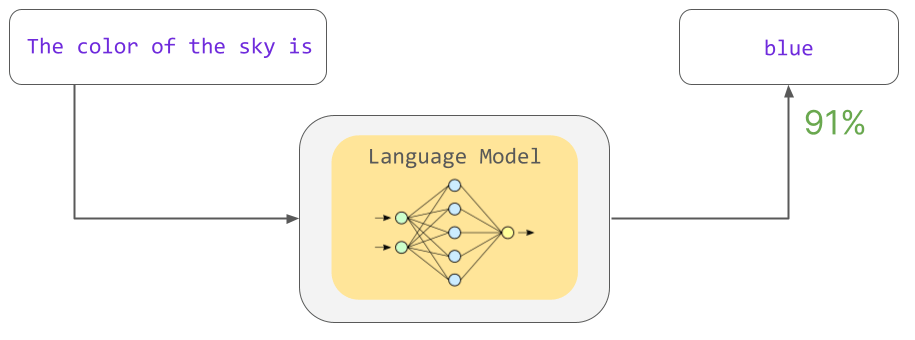
ChatGPTのヒット以降、さまざまなチャットAIが登場していますが、それらのチャットAIは「言語モデル」という技術によって誕生しました。言語モデルは、ある文章に対して特定の文字が続く確率を計算するための計算モデルです。例えば、「The color of the sky is(空の色は)」という文に対して「blue(青い)」という言葉が続く確率を計算することが可能です。
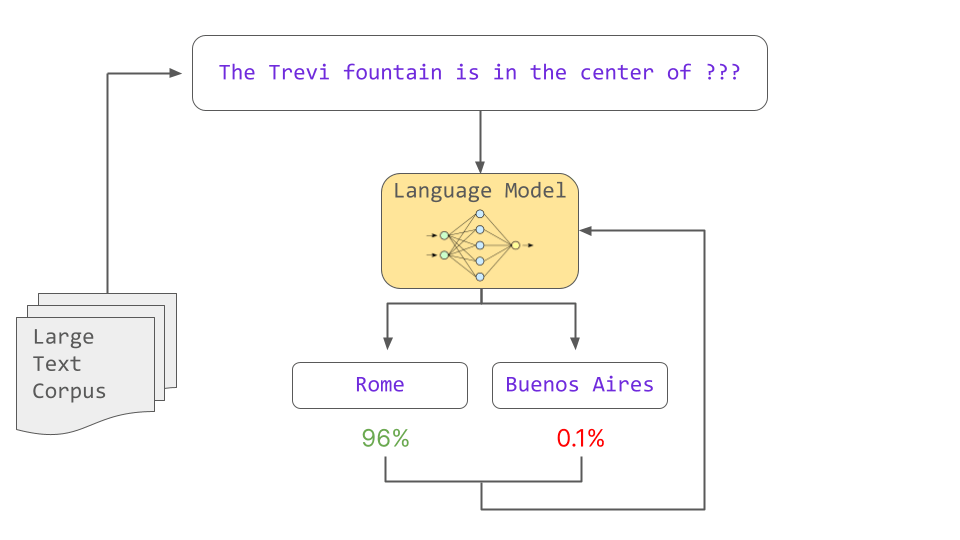
この確率はトレーニング中に学習した統計パターンに基づいています。トレーニングでは、欠落のある文章から「欠落している単語は何か」という確率の計算を通して言語モデルに文法や単語の関係性などさまざまな言語のパターンを学習させます。こうして学習させたモデルのことを「事前学習済みモデル」と呼びます。
事前学習のみでもある程度の出力は行えますが、使用用途に応じた適切なデータで追加の学習を行うファインチューニングを行うとさまざまなタスクを高い精度で行うことが可能になります。
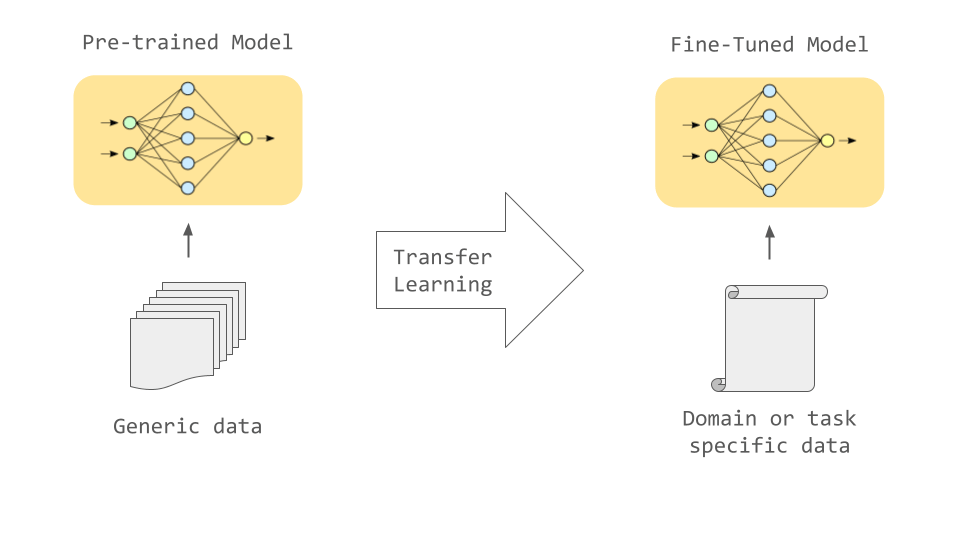
例えば機械翻訳をしたい場合、2つの言語の対訳のデータを用いてファインチューニングすることで、テキストを効果的に翻訳できるようになります。また、医療分野や法律分野など特定分野のデータを用いてファインチューニングすればその分野固有の言葉使いや構文をうまく処理することが可能になります。
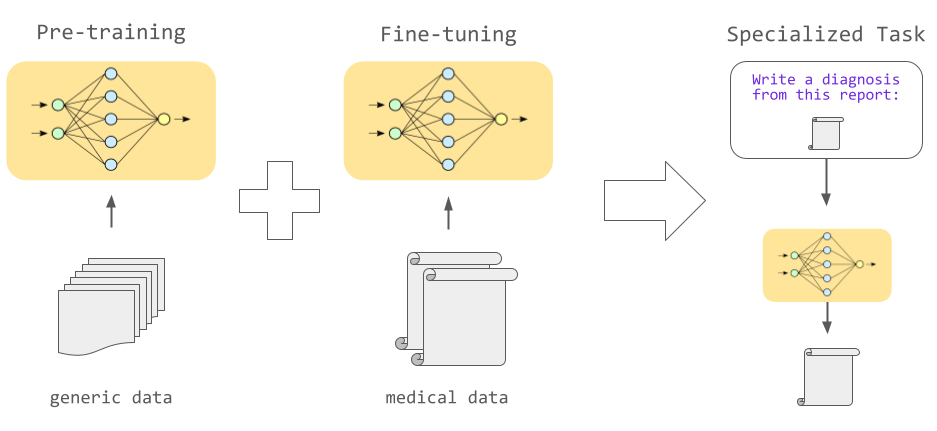
こうした言語モデルの性能は、言語モデルを構成するニューラルネットワークのサイズに大きく影響されます。ニューラルネットワークは人間の脳の仕組みが元になっており、多数のニューロンが接続された構造になっています。それぞれのニューロンの間の接続強度は「パラメーター」で表されており、よりパラメーターの数値が高いほどニューロンの結びつきが強く、前のニューロンに入力された信号が次のニューロンにはっきりと伝わる仕組みです。
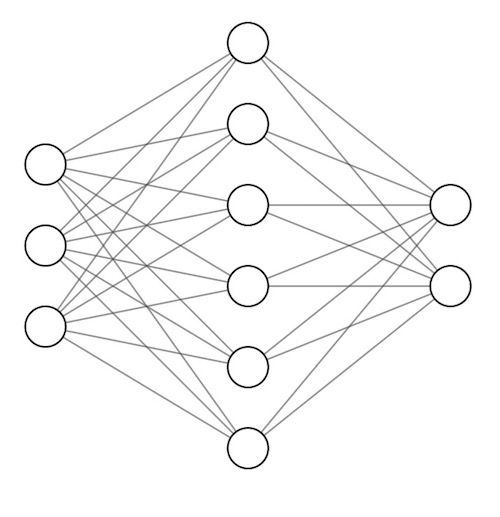
このニューロン間の結びつきの数であるパラメーター数が多ければ多いほど、多様な統計パターンを内部に保持でき、言語モデルの性能が高くなる傾向にあることが判明しています。一方で、パラメーター数に応じてトレーニングに必要なデータの数や時間が増加していきます。このパラメーター数が1億を超えるような特に大きいモデルのことを大規模言語モデルと言います。

言語モデルはニューラルネットワークが基になっているものの、単なるニューラルネットワークというわけではありません。2023年6月時点で活躍している言語モデルは全て2017年に登場した「Transformer」という構造を持ったニューラルネットワークを利用しています。自然言語処理分野で生まれたTransformerは、大量のデータを並列に扱えるという効率性でAI分野に革命を起こしました。効率的にデータを扱えるようになったため、より大規模なデータセットで大規模な言語モデルをトレーニング可能になったというわけです。また、テキストデータ上においては顕著な文脈の理解能力を見せており、ほぼ全ての自然言語処理タスクでスタンダードな選択肢になりました。
Transformerの文脈理解能力は主に「単語の埋め込み」と「アテンション(注意)」という2つの要素によって成立しています。単語の埋め込みは単語を意味・構文的特性を元にベクトル化して扱うというもので、言語モデルに特定の文脈と単語との関係を理解する能力をもたらします。一方アテンションは文章内の単語それぞれに対してアテンションスコアを計算する仕組みで、言語モデルはアテンションの仕組みを通して「入力されたタスクをこなすにはどの単語を重視するべきなのか」を比較検討できるようになったわけです。
Transformerベースの言語モデルは、エンコーダー・デコーダーの構造を利用して文章を処理します。エンコーダーは文章を幾何学的・統計的に意味のある数値にエンコードすることができ、デコーダーはその数値を元に文章を生成することができます。タスクに応じて、エンコーダーとデコーダーのどちらか一方のみを利用することも可能です。例えば、GPTモデルではデコーダーのみが採用されており、新しい文章の生成を行うタスクに特化しています。
Transformerの登場以降、大規模言語モデルの開発はいかにモデルのパラメーター数を多くするかに重心がよってきました。最初のGPTモデルやELMoモデルは数百万から数千万パラメーターでしたが、すぐに数億のパラメーターを持つBERTやGPT-2が登場し、2022年ごろには数千億のパラメーター数を誇る大規模言語モデルが登場しています。モデルが大規模化するにつれてトレーニングに必要なデータの量と時間も増加しており、詳しい金額は公開されないものの事前学習だけで何十億円もかかるという見積もりが行われています。さらに、大規模言語モデルのほとんどはトレーニングが不十分だと判明しており、現状のペースでモデルの拡大が続けば、モデルのサイズではなくトレーニングデータの不足がAIの性能向上のボトルネックになる可能性があります。
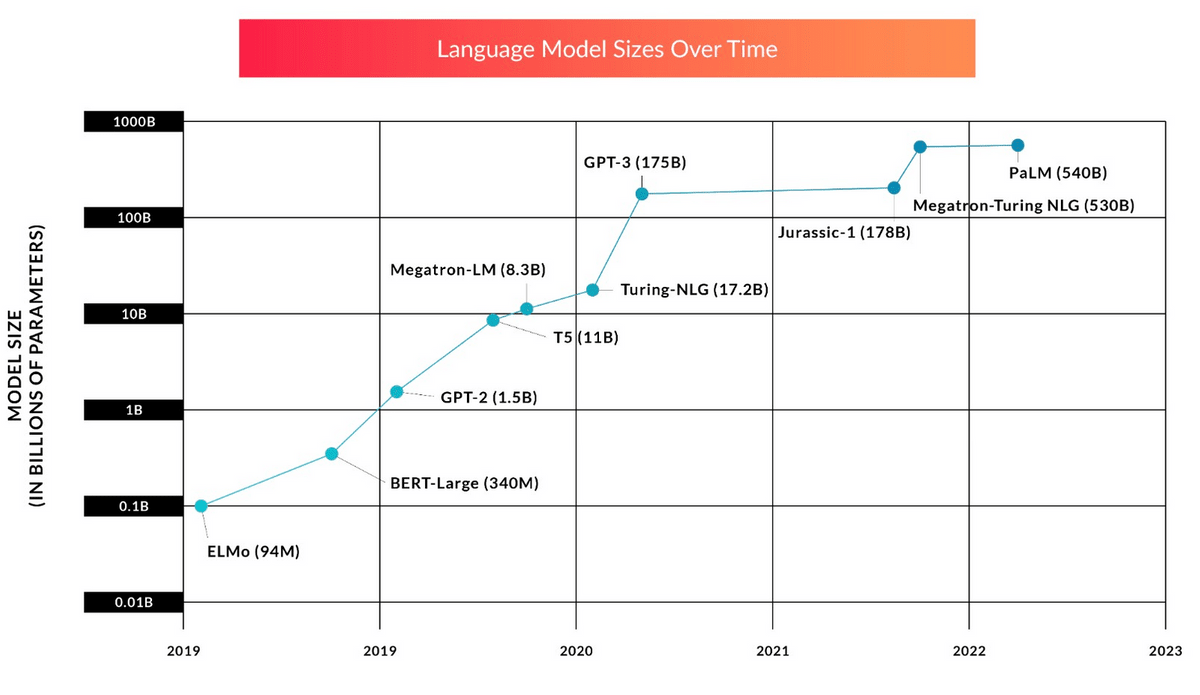
パラメーター数が増えることで単純に受け答えの性能が上がるだけでなく、大規模言語モデルがまったく新しい技能を獲得することも判明しています。一定のパラメーター数を超えると、大規模言語モデルはトレーニング中に自然言語のパターンを繰り返し観察するだけで異なる言語間の翻訳やコードを書く能力をはじめとした幅広いタスクをこなせるようになります。従来は適切なデータでファインチューニングしなければ実行できなかった命令を、いきなり実行できるようになるのは驚異的です。
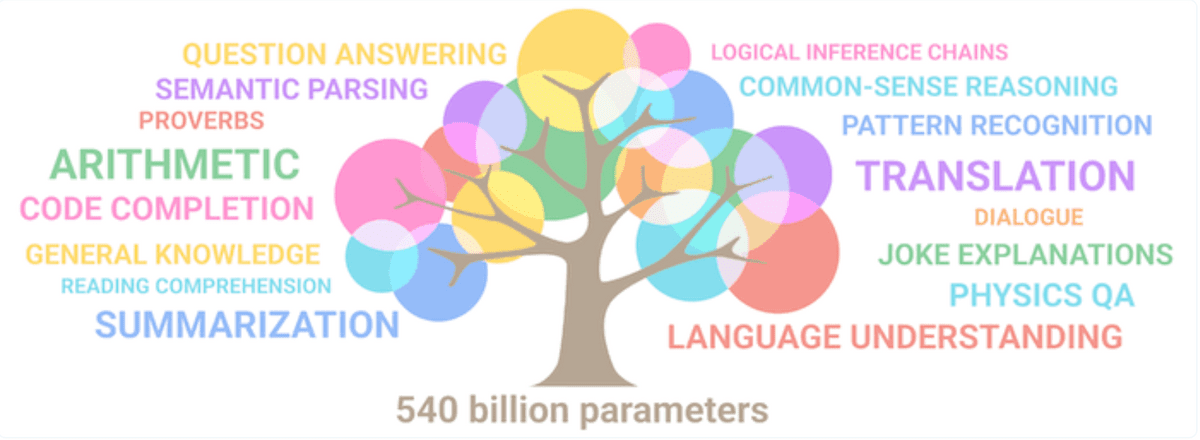
しかし、言語モデルの技術は良いことだけをもたらしたわけではありません。言語モデルのコーディング能力がマルウェアの作成に利用されたり、AI生成コンテンツを利用してSNS上でプロパガンダが行われたり、トレーニング中に入力されたプライバシーを侵害するデータを返答に含めてしまったり、精神的なサポートを求めるチャットに対して有害な回答をしたりする危険が存在しています。
言語モデルに対する懸念点は多数存在していますが、言語モデルの作成においては以下の3点が目指すべき原則と言われています。
・有用性
必要に応じてユーザーの意図を明確にするための質問をしつつ、指示に従ってタスクを実行する能力。
・真実性
事実に基づく正確な情報を提供し、言語モデル自身の不確実性と限界を認識する能力。
・無害性
偏見があったり毒が入っていたり、不快だったりする反応を避け、また危険な活動への支援を拒否する能力。
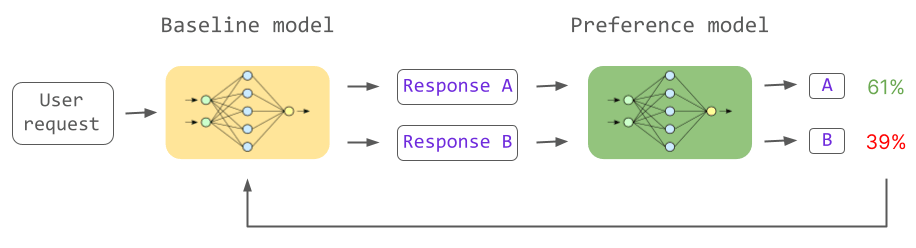
この3点を達成するのに2023年6月時点で最も適しているとされているのが「人間のフィードバックによる強化学習(RLHF)」です。RLHFには下図左側に表示されている通常の言語モデルと、下図右側に緑色で表示されている、2つの入力を受け取って「人間がどちらの回答を好むのか?」を決めるモデルが登場します。通常の言語モデルに「より人間が好みそうな回答」を学習させることで、タスクへの回答の品質が向上します。
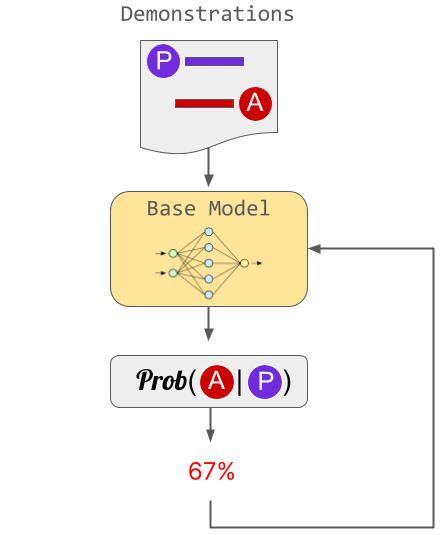
ChatGPTでは3段階に分けてRLHFが進められました。最初のステップでは人間による見本を「理想的な回答」としてモデルをトレーニングしました。このアプローチでは人間が見本を書く必要があるため、スケーリングするのが難しいという問題を抱えています。
2番目の段階では、言語モデルが生成した複数の回答の優劣を人間が投票し、回答と投票結果を報酬モデルに学習させることが行われました。こうして報酬モデルは「どのような回答が人間好みなのか」を判断する能力を身につけたというわけです。
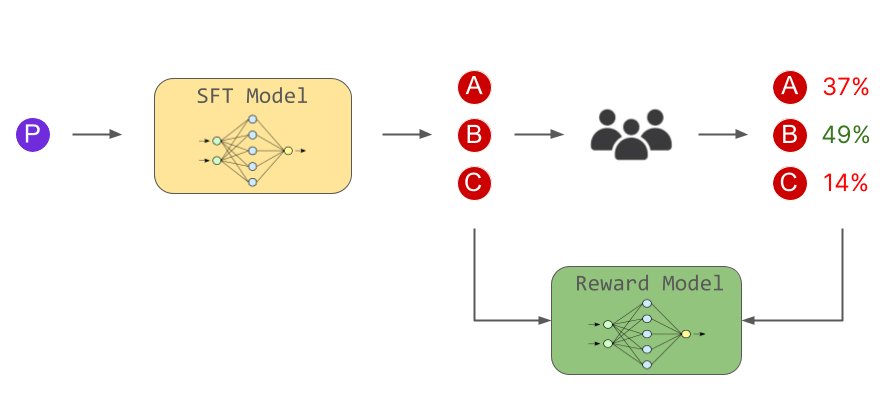
そして3番目の段階では、報酬モデルに基づいて言語モデルが人間好みの回答を出力するようにトレーニングを行いました。この2段階目と3段階目は複数回に渡って行われたとのこと。
RLHFを行わなかった場合、インターネットの玉石混交な文章から回答が生成されることになります。そうした場合、分布の範囲が広すぎて回答が安定しない可能性が存在するとのこと。例えば政治家について質問した場合、Wikipediaを基にした中立的な回答をする可能性もあれば、掲示板などの過激な視点を元に極端な発言をしてしまう可能性もあるわけです。
RLHFでは人間の視点を注入することで、モデルにバイアスを与えて生成する範囲を狭めていると考えることができます。回答の多様性と安定性・一貫性はトレードオフの関係にあり、一方だけを獲得することはできません。もちろん、検索エンジンなど正確や信頼性の求められる分野においては一貫して安定している回答が望ましいのでRLHFを行うべきですが、創造的な作業の補助用途などでRLHFを使用すると、多様性をもとにした新しく興味深い概念の探求が妨げられることもあるとランポニさんは述べています。
・関連記事
ChatGPTなどの大規模言語モデルはどんな理論で成立したのか?重要論文24個まとめ - GIGAZINE
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE
GPT-4やPaLMなどの大規模言語モデルは規模が大きくなると突然予想外の能力を開花させることがある - GIGAZINE
GPUメモリが小さくてもパラメーター数が大きい言語モデルをトレーニング可能になる手法「QLoRA」が登場、一体どんな手法なのか? - GIGAZINE
大規模言語モデルの出力スピードを最大24倍に高めるライブラリ「vLLM」が登場、メモリ効率を高める新たな仕組み「PagedAttention」とは? - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article What kind of mechanism is the technology….