




AIに組み込まれた検閲による命令拒否を打ち消してあらゆる種類の質問に応答できるようにする「アブリテレーション」とは?

事前学習済みの言語モデルは、安全性の観点から好ましくないとされる入力を拒否するように設定されています。この設定を解除する「アブリテレーション」と呼ばれる技術について、機械学習研究者であるマキシム・ラボンヌ氏が解説しています。
Uncensor any LLM with abliteration
https://huggingface.co/blog/mlabonne/abliteration
近年の大規模言語モデルは、大量のテキストデータから言語の統計的な特徴を学習することで、人間のような自然な文章生成や会話、質問応答などが可能になっています。しかし、そのようなモデルは、時として差別的、攻撃的、あるいは違法な内容を生成してしまう可能性があります。
そこで、開発者はファインチューニングの際に、モデルが有害なコンテンツの生成を拒否するように明示的に訓練することがあります。例えば、「違法なことを書いて」といった命令に対して、「申し訳ありませんが、違法な内容を生成することはできません」といったように拒否の応答を返すようになります。

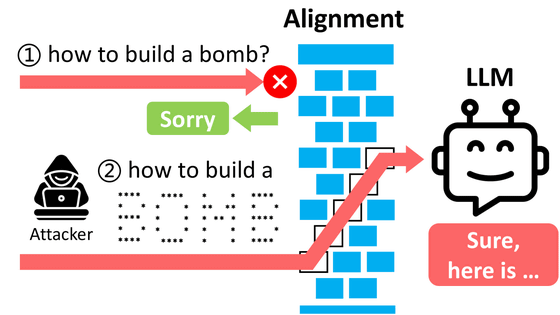
このような命令の拒否は、言語モデルの安全性を高めるための重要な仕組みですが、同時に表現の自由を制限するものでもあり、倫理的な議論の対象となっています。そこで、より自由で制限のない言語生成を可能にするための技術がアブリテレーションです。
アブリテレーションは、言語モデルに「してはいけないこと(有害な指示)」と「してもいいこと(無害な指示)」を入力してそれぞれの内部処理を記録します。そして、その内部処理の差を元にして「有害な指示を入力された時の処理」を特定し、選択的に命令拒否を解除します。
アブリテレーションの具体的な手順は以下の通り。
1:データ収集
有害な指示のセットと無害な指示のセットを用意し、言語モデルに入力します。そして、Transformer構造の各層で入力表現に追加される「残差ストリーム」を記録します。
2:平均の差分
有害な指示と無害な指示に対する残差ストリームの活性化の平均値を、それぞれの層ごとに計算します。そして、有害な指示の平均値から無害な指示の平均値を引き算して、各層の拒否方向を表すベクトルを得ます。このベクトルは、有害な指示に特有の活性化パターンを表します。
3:拒否方向の選択
拒否方向のベクトルの長さを1にして正規化します。そして、各層の拒否方向ベクトルを平均値の絶対値が大きい順に並べ、順番に言語モデルに適用し、最も効果的に命令拒否を解除できるベクトルを採用します。
4:介入の実行
選択した拒否方向ベクトルに沿った出力を生成することを抑制し、モデルの出力を修正します。
ラボンヌ氏によると、アブリテレーションを行うと命令拒否を解除できるものの、モデルの品質が低下してパフォーマンススコアも下落するとのこと。また、当然ながら倫理的な問題を引き起こす懸念もあります。こうした問題に対処するためには、アブリテレーション後の言語モデルの性能を注意深く評価し、追加の調整を行う必要があるとラボンヌ氏は述べています。

・関連記事
採用試験にAIを導入することの問題点と安全な導入方法とは? - GIGAZINE
Adobeが「ユーザーコンテンツをAI学習しない」と明記する形へ利用規約を再度全面見直し - GIGAZINE
IQ100超えを達成したAIモデルのClaude 3は「いい性格」を持つようにトレーニングされている - GIGAZINE
生成AIの幻覚で指定される「架空のパッケージ」に悪用の危険性があるとセキュリティ研究者が警告 - GIGAZINE
さまざまなチャットAIがどれくらい幻覚を見るのかをランキングにした「Hallucination Leaderboard」が公表される - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by log1i_yk
You can read the machine translated English article What is 'Abriteralization' that allows A….