




「オンラインで公開されたものすべてをAIのためにスクレイピングする」とGoogleが発表

2023年7月1日にGoogleがプライバシーポリシーを変更し、「GoogleのAIモデルのトレーニング」のために「一般に公開される情報」を使用すると明言したことが分かりました。記事作成時点で、このプライバシーポリシーはアメリカ国内向けに発行されています。
プライバシー ポリシー – ポリシーと規約 – Google
https://policies.google.com/privacy/archive/20221215-20230701
Google Says It'll Scrape Everything You Post Online for AI
https://gizmodo.com/google-says-itll-scrape-everything-you-post-online-for-1850601486
VPNやインターネットアーカイブなどを通してアメリカ国内向けのプライバシーポリシーを確認すると、「情報の利用または開示目的」という項目の中に「Googleは、Googleのサービスを向上させ、Googleのユーザーや一般ユーザーに有益な新しい製品、機能、技術を開発するために情報を使用します。たとえば、GoogleのAIモデルのトレーニングや、Google翻訳、Bard、クラウドAI機能などの製品や機能の構築に、一般に公開されている情報を使用します」との文言が記載されています。
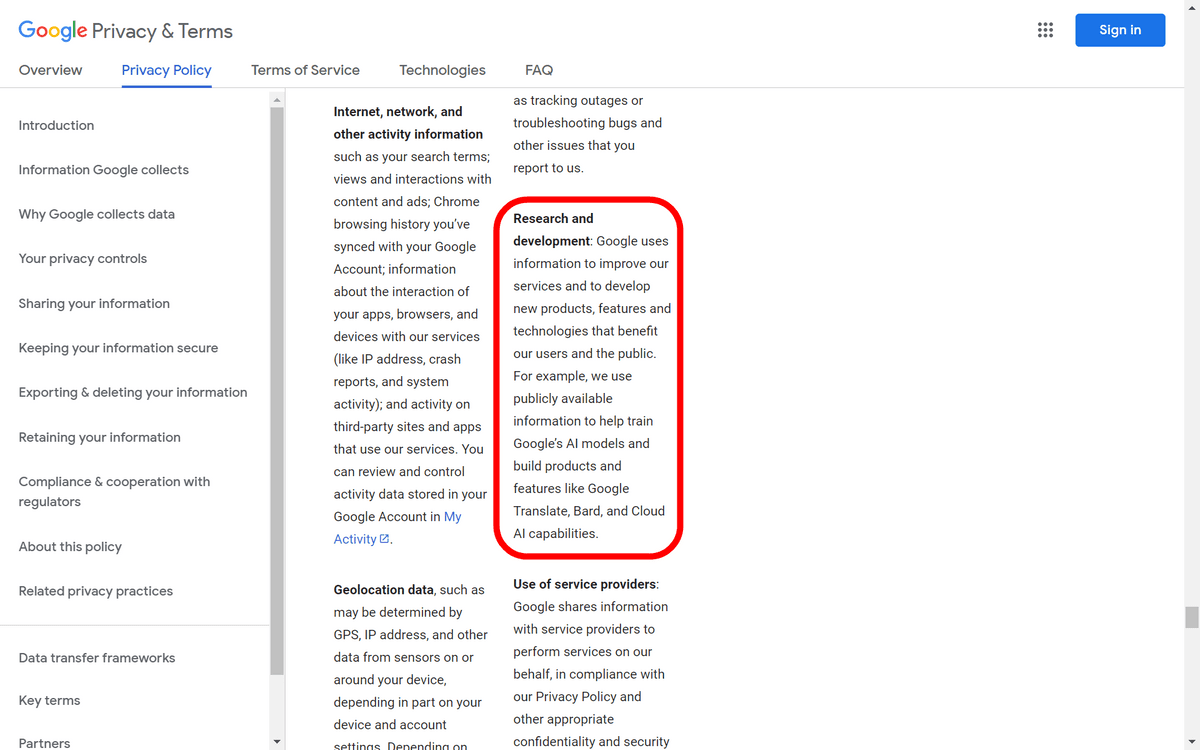
2022年10月4日に施行された改正前のプライバシーポリシーでは「Googleの言語モデルをトレーニングし、Google翻訳などの機能を構築するために、一般に公開されている情報を使用します」と表現されていたため、プライバシーポリシーの改正により情報の使用目的の範囲が広がったことが分かります。

GIZMODOは「これはプライバシーポリシーとしては珍しい条項です」と指摘。「通常、このようなポリシーでは、ユーザーが『自社のサービス』に投稿した情報を利用する方法について説明します。しかし、Googleは『公共のウェブのあらゆる場所』に投稿されたデータを収集して利用する権利を留保するかのように書いており、まるでインターネット全体がGoogleの遊び場であるかのようにも見て取れます」と述べました。
インターネット上で公開されているコンテンツの中には著作権で保護されたコンテンツが含まれていることもありますが、学習用データセットの作成に著作権で保護されたコンテンツを使用することの是非については、アメリカでは法的に明確に定められているわけではありません。しかし、アメリカではChatGPTを開発したOpenAIに対して「学習用データセットが著作権とプライバシーを侵害している」との集団訴訟が提起されているなど、AIと著作権への人々の関心は高まり続けています。
ChatGPT開発のOpenAIがAI学習用データをめぐって集団訴訟を起こされる - GIGAZINE

インターネット上に公開されたコンテンツを収集するという行為といえば、Twitterを買収したイーロン・マスク氏がTwitterの閲覧に制限を設けた理由として上げたものでもあります。マスク氏はAI関連企業等のスクレイピングを阻止するため、非ログイン状態での投稿閲覧を完全に不可能にし、ログイン状態でも1日当たりの閲覧件数に上限を設けています。
Twitterが1日に閲覧できるツイート数に制限を設ける、イーロン・マスクは理由を「極端なスクレイピングに対処するため」と説明 - GIGAZINE

・関連記事
「ChatGPTの学習に海賊版の本が使われた」として作家がOpenAIを告訴 - GIGAZINE
AI学習データの開示を義務づける法案がEUで提出される - GIGAZINE
「AIのトレーニングに楽曲が使用されるのを阻止してほしい」とユニバーサルミュージックグループがSpotifyやApple Musicに要求 - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, Posted by log1p_kr
You can read the machine translated English article ``Everything published online will be sc….