``Everything published online will be scraped for AI,'' Google announced

It turned out that on July 1, 2023, Google changed
Privacy Policy – Privacy & Terms – Google
https://policies.google.com/privacy/archive/20221215-20230701
Google Says It'll Scrape Everything You Post Online for AI
https://gizmodo.com/google-says-itll-scrape-everything-you-post-online-for-1850601486
If you check the privacy policy for the United States through VPN, Internet Archive , etc., in the item 'Purpose of use or disclosure of information', 'Google will improve Google's services and new information that will be beneficial to Google users and general users. We use information to develop our products, features and technologies, for example, using publicly available information to train Google's AI models and to build products and features such as Google Translate, Bard and cloud AI features. It will be used.'
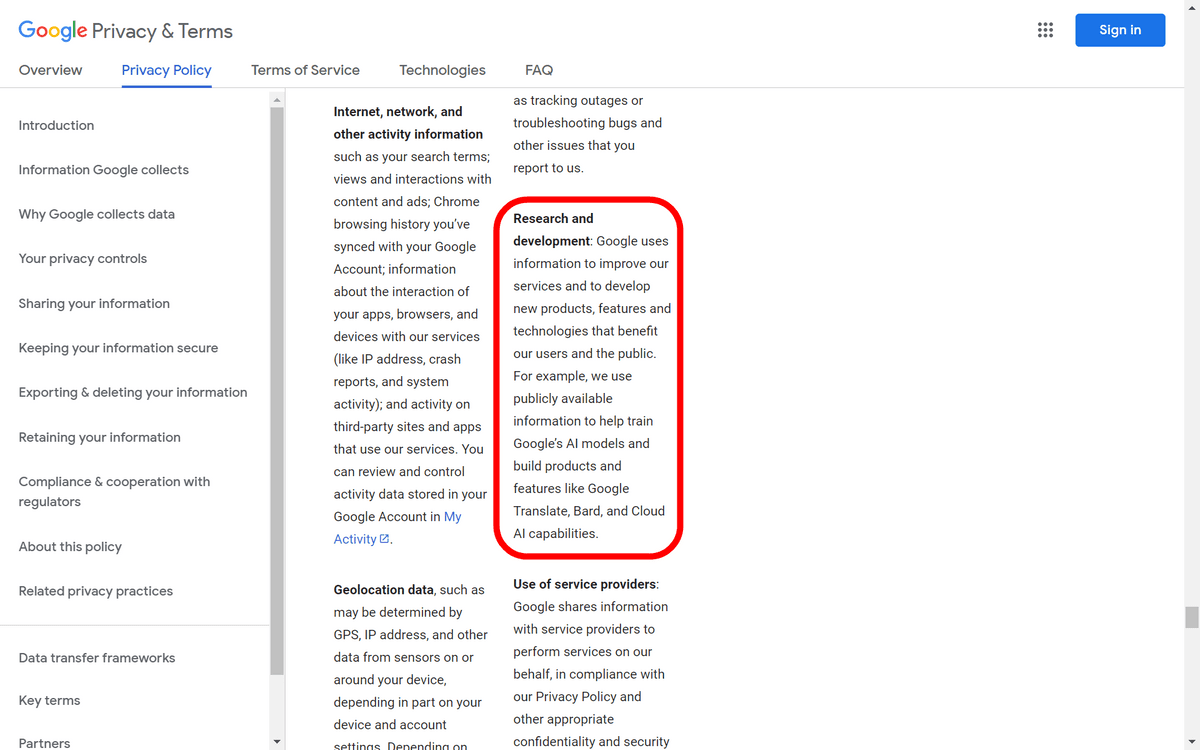

``This is an unusual clause for a privacy policy,'' GIZMODO pointed out. 'Typically, such policies describe how users can use information posted on 'their own service'. However, Google does not collect data posted 'anywhere on the public web'. It is written as if it reserves the right to use it, and it can be seen as if the entire Internet is Google's playground.'
Copyrighted content may be included in the content published on the Internet. is not legally defined in the United States. However, in the United States, people's interest in AI and copyright has increased, such as a class action lawsuit filed against OpenAI, which developed ChatGPT, that `` training datasets infringe copyright and privacy ''. continue.
OpenAI developed by ChatGPT is filed a class action lawsuit over AI learning data - GIGAZINE

Speaking of the act of collecting content published on the Internet, it is also the reason why Elon Mask, who acquired Twitter, set limits on Twitter browsing. In order to prevent scraping by AI-related companies, etc., Mr. Mask makes it completely impossible to view posts without logging in, and sets an upper limit on the number of views per day even when logged in.
Twitter sets a limit on the number of tweets that can be viewed per day, Elon Mask explains the reason as ``to deal with extreme scraping''-GIGAZINE

Related Posts: