




GPU不要・メモリ16GBの本当の一般家庭PCでチャットAIを動作させるライブラリ「GGML」が鋭意開発中、すでにRaspberry Piで音声認識AIを動作させるデモも登場済み

ChatGPTやBardなどで利用されているチャットAIは、トレーニングだけでなく動作させるのにも数十~数百GBのVRAMなど非常に高いマシンスペックを要求するのが一般的です。そうした状況を変えるべく、GPU不要でチャットAIを動作させるライブラリ「GGML」の開発が進められています。
ggml.ai
http://ggml.ai/

ggerganov/ggml: Tensor library for machine learning
https://github.com/ggerganov/ggml
GGMLの特徴は下記の通り。
・Cで記述
・16bit floatをサポート
・4bit、5bit、8bitの整数での量子化をサポート
・自動微分
・「ADAM」「L-BFGS」という最適化アルゴリズムを搭載
・Appleシリコンへの対応&最適化
・x86アーキテクチャではAVXおよびAVX2を使用
・WebAssemblyとWASM、SIMDによるウェブのサポート
・サードパーティーへの依存性なし
・動作中にメモリを使用しない
・ガイド付き言語出力をサポート
GGMLのコードはGitHub上で公開されていますが、「このプロジェクトは開発中であることに注意してください」と太字で注意書きされています。

GGMLは開発中のプロジェクトであるものの、いくつかのデモが公開されています。例えば下のムービーはGGMLとwhisper.cppを利用して音声でコマンドを入力している様子です。これだけであれば普通の光景なのですが、これがRaspberry Piという超軽量PC上で動作しているのがすごいところです。
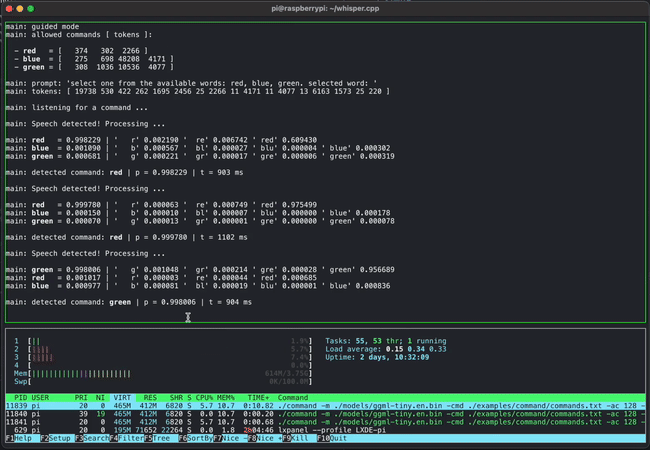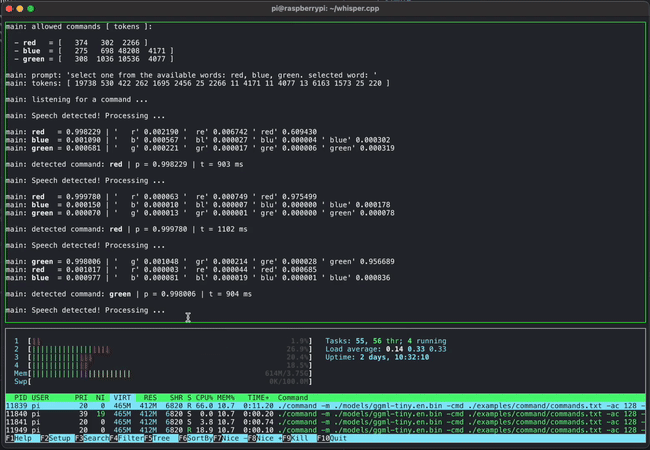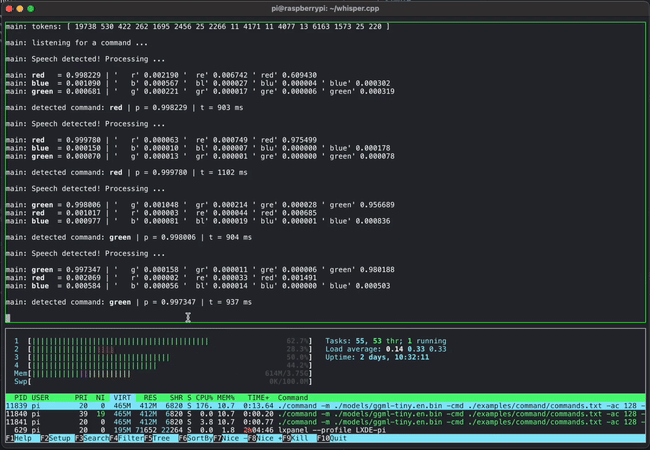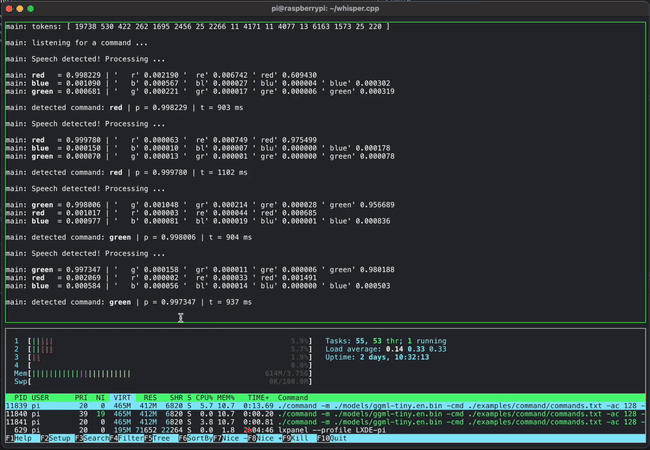
また、130億パラメーター(13B)のLLaMAとWhisperを組み合わせたモデルを同時に4つApple M1 Pro上で動作させるデモも掲載されており、存分に軽量さをアピールしています。
Apple M2 Maxで70億パラメーター(7B)のLLaMAモデルを動作させると、1秒間に40トークンを処理できるとのこと。かなりのスピードです。
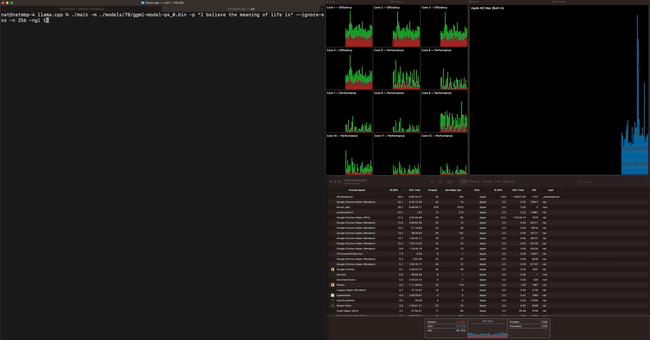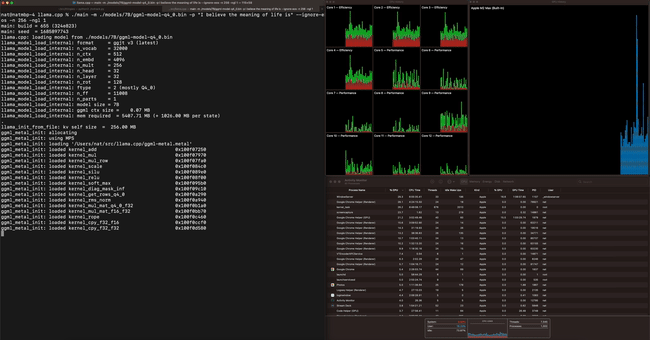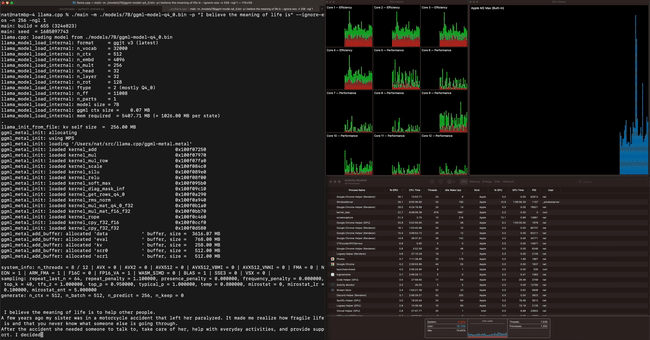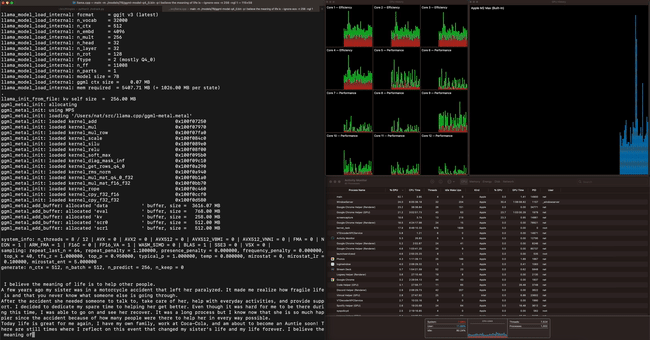
その他のテスト結果は下記の通り。
| モデル | マシン | 結果 |
|---|---|---|
| Whisper Small Encoder | M1 Pro: 7 CPU threads | 600 ms / run |
| Whisper Small Encoder | M1 Pro: ANE via Core ML | 200 ms / run |
| 7B LLaMA (4bit量子化) | M1 Pro, 8 CPU threads | 43 ms / token |
| 13B LLaMA (4bit量子化) | M1 Pro, 8 CPU threads | 73 ms / token |
| 7B LLaMA (4bit量子化) | M2 Max GPU | 25 ms / token |
| 13B LLaMA (4bit量子化) | M2 Max GPU | 42 ms / token |
GGMLはMITライセンスで提供されており、誰でも無料で使用可能。また、開発チームは「コードを書いてライブラリを改善するのが最大のサポートになります」と述べて開発協力者を広く募っています。
なお、編集部でも実際に動作できるか確かめてみましたが、ドキュメントの記載通りに進めていたところビルドでエラーが発生してしまい進めませんでした。
・関連記事
ChatGPTに匹敵する性能の日本語対応チャットAI「Vicuna-13B」のデータが公開され一般家庭のPC上で動作可能に - GIGAZINE
GPT-3のライバルとなるMetaの「LLaMA」をM1搭載Macで実行可能に、大規模言語モデルを普通の消費者向けハードウェアで実行可能であることが示される - GIGAZINE
無料で商用利用もOKな完全オープンソースの大規模言語モデルを開発するプロジェクト「RedPajama」がトレーニングデータセットを公開 - GIGAZINE
チャットAI「Alpaca」をローカルにインストールしてオフラインでAIと会話できる「Alpaca.cpp」インストール手順まとめ - GIGAZINE
Metaの大規模言語モデル「LLaMA」をM1搭載Macで実行可能にした「llama.cpp」がアップデートによりわずか6GB未満のメモリ使用量で実行可能に - GIGAZINE
GPT-3に匹敵するチャットAIモデル「LLaMA」をiPhoneやPixelなどのスマホで動かすことに成功 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by log1d_ts
You can read the machine translated English article A library called 'GGML' that runs chat A….