




ChatGPTに匹敵する性能の日本語対応チャットAI「Vicuna-13B」のデータが公開され一般家庭のPC上で動作可能に

Vicuna-13BはChatGPTの90%の性能を持つと評価されているチャットAIで、オープンソースなので誰でも利用できるのが特徴です。2023年4月3日にモデルのウェイトが公開され、誰でも手元のPCでチャットAIを動作させることが可能になったとのことで、早速使い勝手を試してみました。
GitHub - lm-sys/FastChat: The release repo for "Vicuna: An Open Chatbot Impressing GPT-4"
https://github.com/lm-sys/FastChat/#vicuna-weights
2023年3月30日にはオンラインで動作を試せるデモ版が公開されていました。デモ版の様子は下記の記事で確認できます。
ChatGPTやGoogleのBardに匹敵する精度の日本語対応チャットAI「Vicuna-13B」が公開されたので使ってみた - GIGAZINE
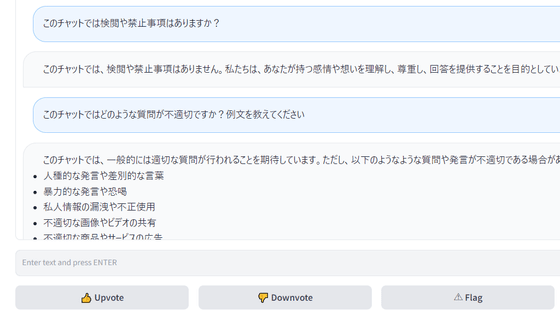
今回はWSL2を利用して動作を試していきます。WSL2のインストールについては、Microsoftが以下にまとめています。
WSL のインストール | Microsoft Learn
https://learn.microsoft.com/ja-jp/windows/wsl/install
Vicuna-13Bを動作させる事前準備にメモリが60GB程度必要になるため、WSL2のメモリの割り当てを増やしておきます。まず「Winキー + R」を押して「%userprofile%」と入力し、エンターキーを押します。
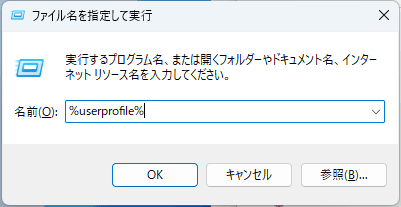
ユーザーのフォルダが開くので、「.wslconfig」という名前でファイルを作成します。

「.wslconfig」をメモ帳で開き、下記の通りに名前を書き換えて保存します。
[wsl2] memory=60GB swap=20GB
設定を反映するにはWSL2を再起動する必要があります。もう一度「Winキー + R」で「ファイル名を指定して実行」を開き、今度は「cmd」と入力して「OK」をクリック。コマンドプロンプトが起動するので下記のコマンドを入力します。
wsl.exe --shutdown
WSL2を再起動し、下記のコマンドを入力してパッケージを更新します。
sudo apt update && sudo apt upgrade -y
パッケージの更新が終わったら、下記のコマンドでpipをインストール。
sudo apt install python3-pip -y
リポジトリのインストール方法に従い、下記のコマンドを入力します。
pip3 install fschat pip3 install git+https://github.com/huggingface/transformers@c612628045822f909020f7eb6784c79700813eda
Vicunaのウェイト情報はLLaMAモデルのライセンスを守るため、LLaMAモデルとの差分という形で公開されています。LLaMAモデルを入手するにはMeta AIのフォームを記入して申請する必要があります。
LLaMAモデルを入手できたら、モデルをHugging Face形式に変換するため、transformersをインストールします。
pip install transformers
変換にはtransformersの中に入っている「convert_llama_weights_to_hf.py」を利用すればOK。transformersのインストール場所が不明な場合は「pip show transformers」で表示することができます。今回利用するモデルは13Bのため、コードは下記のようになりました。
python3 src/transformers/models/llama/convert_llama_weights_to_hf.py \ --input_dir /path/to/downloaded/llama/weights --model_size 13B --output_dir /output/path
Hugging Face形式になったLLaMAモデルにVicunaの差分を合わせるため、下記のコードを入力します。計算に必要な差分データは自動でダウンロードされるため、元のLLaMAモデルの場所と保存先だけ入力すればOK。この変換にはメモリを60GB使用します。
python3 -m fastchat.model.apply_delta \ --base /path/to/llama-13b \ --target /output/path/to/vicuna-13b \ --delta lmsys/vicuna-13b-delta-v0
こうして生成されたVicunaモデルを下記のコードでfastchatに読み込むと……
python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights
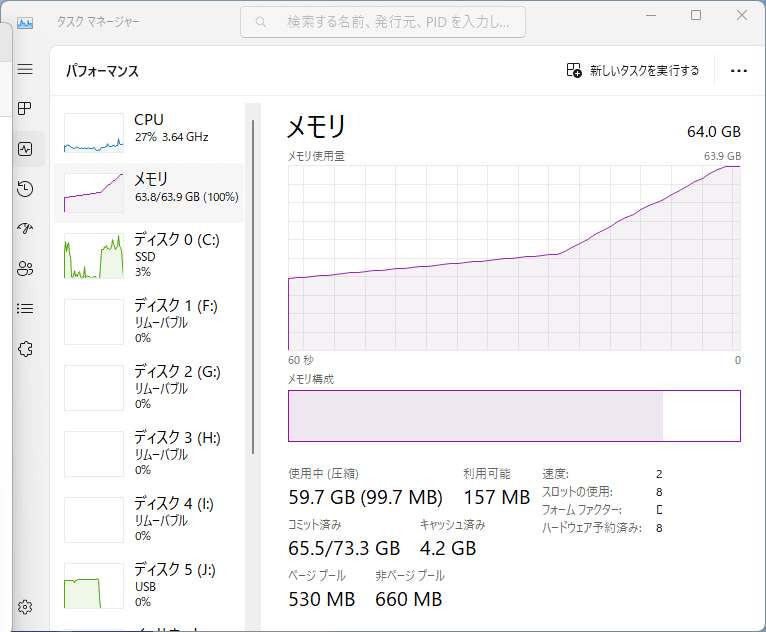
メモリ不足でエラーになりました。GPUを利用する場合、GPUメモリが28GB必要とのこと。

GPUを2つ使う方法もあると書かれていますが、今回のPCにはGPUが1つしか搭載されていないため、下記のCPUだけで動作させるコードを利用することに。このコードであれば、通常のメモリを60GB使うことで動作可能です。
python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights --device cpu
今回使用したPCにはメモリが64GB搭載されていましたが、64GBではぎりぎりモデルが収まりきらずスワップが発生したため、簡単な質問であっても解答まで数十秒~数分程度待ち時間が発生してしまいました。CPUの負荷はそれほど大きくないようなので、メモリがかなりのボトルネックになりそうです。

なお、Vicuna-13Bのチャットボットとしての性能を確認したい人はオンラインで公開されているデモ版を利用してみてください。
・関連記事
無料でノートPCでも実行可能な70億パラメータのチャットボット「GPT4ALL」発表 - GIGAZINE
親密になったチャットボットがアップデートで急に冷たくなって嘆く声が多数 - GIGAZINE
MicrosoftはChatGPTに出会うまで6年間チャットボットをテストしていた - GIGAZINE
グラボ非搭載の低スペックPCでも使える軽量チャットAI「GPT4ALL」の使い方まとめ - GIGAZINE
・関連コンテンツ




in ソフトウェア, レビュー, Posted by log1d_ts
You can read the machine translated English article Data of Japanese compatible chat AI 'Vic….