GPU・CUDAを活用して数値計算やAIのトレーニングを高速化するのに必要な基礎知識のコード例付きまとめ

GPUはCPUよりもはるかに多くのコアを備えており、多数の並列処理を行う事が可能です。そうしたGPUの性能を活用するために必要な知識を、ITエンジニアのリジュル・ラジェシュさんがブログにまとめています。
GPU Survival Toolkit for the AI age: The bare minimum every developer must know
https://journal.hexmos.com/gpu-survival-toolkit/
現代のAIモデルで使用されているTransformerアーキテクチャは並列処理を活用して大きく性能を向上させており、そうしたAIの開発に関わる場合は並列処理についての理解が必須になってきます。CPUは通常シングルスレッドの逐次処理性能が高まるように設計されており、複雑なAIモデルで必要となる、多数の並列計算を効率的に分散して実行するのには向いていません。
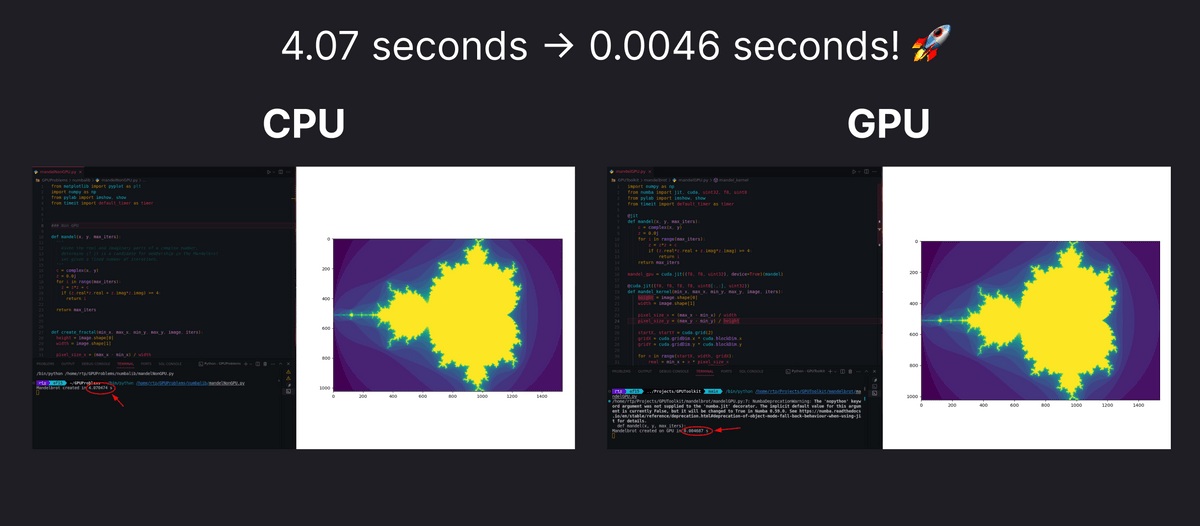
CPUが大型でパワーのあるコアを搭載しているのに対し、GPUは小型なコアを多数搭載しており、コア数が多い分だけより多くの並列処理を同時に行う事が可能で、グラフィックスレンダリングや複雑な数学の計算など並列処理に依存するタスクに向いているという特徴があります。タスクに応じて適切にCPU・GPUを使い分けることで、下図のように4.07秒かかっていた処理を0.0046秒で終わらせられるようになるなど、処理速度を大きく向上させることができます。
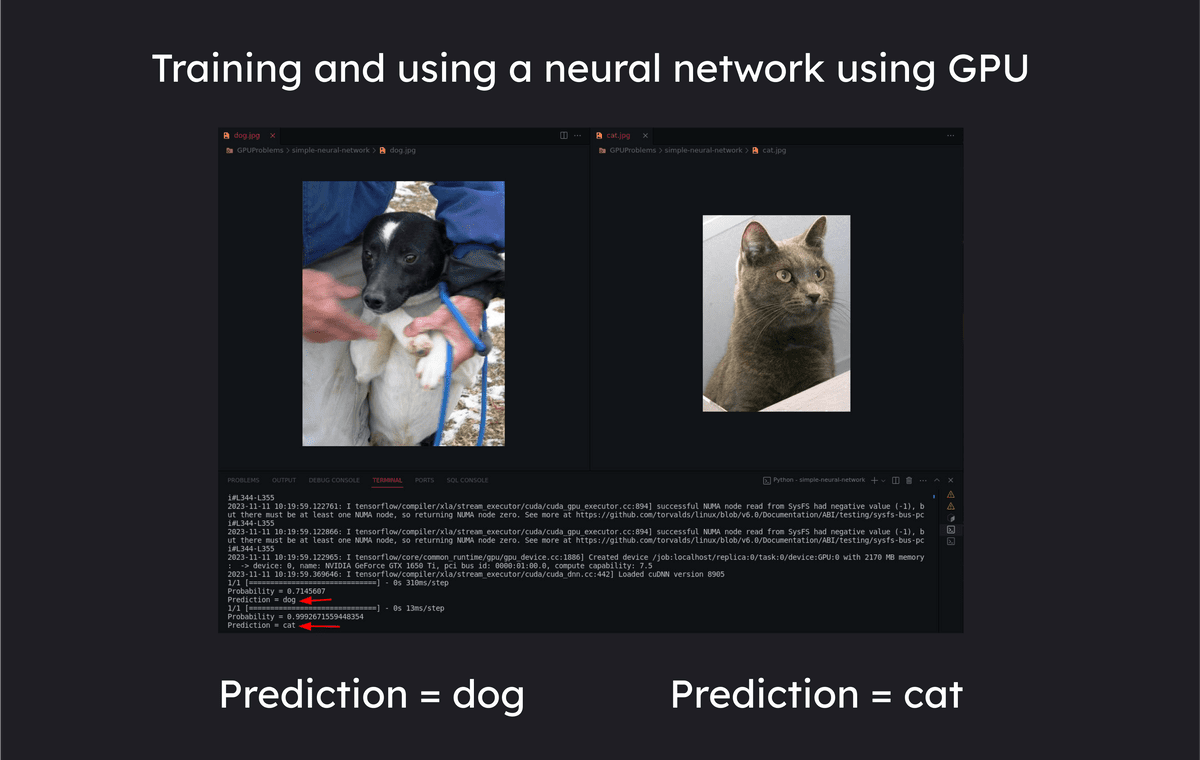
また、ニューラルネットワークのトレーニングには多数の行列演算が含まれており、行列演算は並列性が高いためコア数の多いGPUを活用することで処理を高速化できます。
CPUとGPUの違いをまとめると次の通り。
◆CPU
CPUは逐次処理に重点を置いて設計されており、単一セットの命令を線形に実行することに優れています。コア数は2コア~16コアの場合が多く、各コアは独自の命令セットを独立して処理できるもののそれほど大規模な並列処理は行えません。高いシングルスレッド性能を必要とするタスク向けに最適化されており、次のような用途で利用されます。
・汎用コンピューティング
・システム運用
・条件分岐を伴う複雑なアルゴリズムの処理
◆GPU
GPUには多い場合で数千ものコアが搭載されており、コアを数個ずつストリーミングマルチプロセッサという単位にまとめて使用します。タスクをより小さな並列サブタスクに分割することで同時処理を行うなど並列処理タスク向けに設計されており、次のようなタスクを効率的に処理できます。
・グラフィックスレンダリング
・複雑な数学的計算の実行
・並列化可能なアルゴリズムの実行
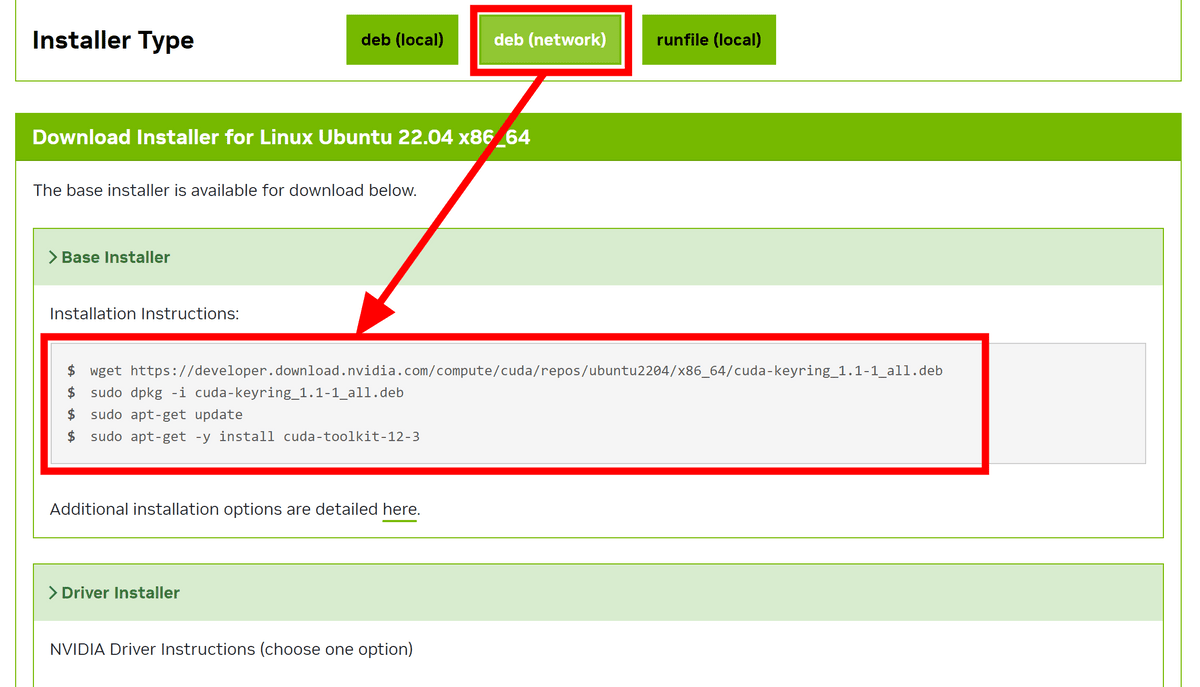
ということで、Nvidiaが開発した並列コンピューティングプラットフォームおよびプログラミングモデルである「CUDA」を使用して実際にGPUを活用してみます。まずはNvidiaのサイトにアクセスし、CUDAをインストールしたいマシンの情報を入力します。今回は「Linux」「x86_64」「Ubuntu」「22.04」「deb (network)」を選択しました。

「Installer Type」まで入力が完了すると下部にインストールのためのコマンドが出現します。「Base Installer」の方は記載されているコマンドを順番に実行すればOK。
「Driver Installer」の方は2種類から1つを選択するようになっています。今回はGPUメモリと直接データをやりとりできるGDSを使用するため「the open kernel module flavor」に記載されているコマンドでインストールします。
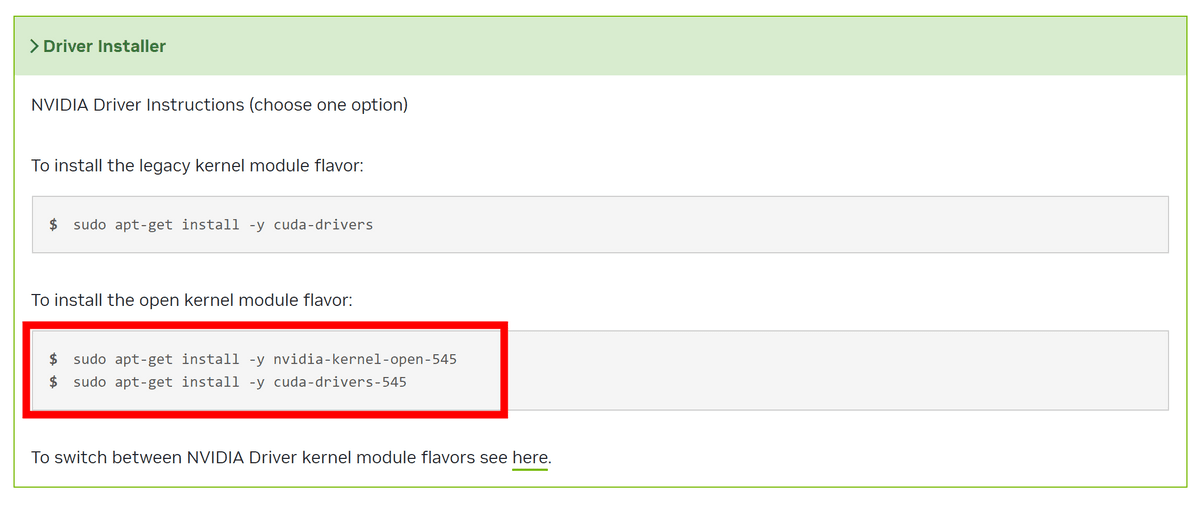
ホームディレクトリの「.bashrc」に下記の通り追記し、パスを通します。
export PATH="/usr/local/cuda-12.3/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-12.3/lib64:$LD_LIBRARY_PATH"
また、下記のコマンドでGDSをインストール。インストール後、システムを再起動して変更を反映します。
sudo apt-get install nvidia-gds
◆GPUを活用してプログラミングする際に役立つコマンド
・「lspci | grep VGA」
システム内のGPUを識別して一覧表示できます。

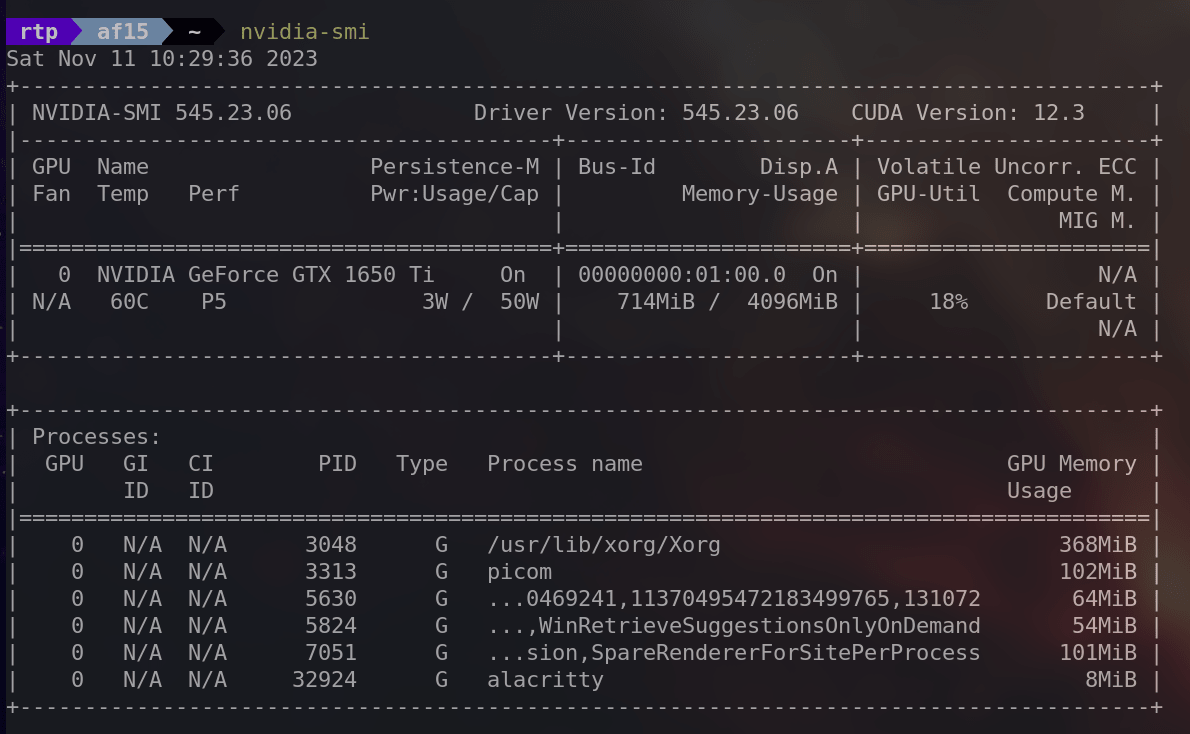
・「nvidia-smi」
nvidia-smiは「NVIDIA System Management Interface」の略で、使用率、温度、メモリ使用量など、システム内のNVIDIA GPUに関する詳細情報を提供します。
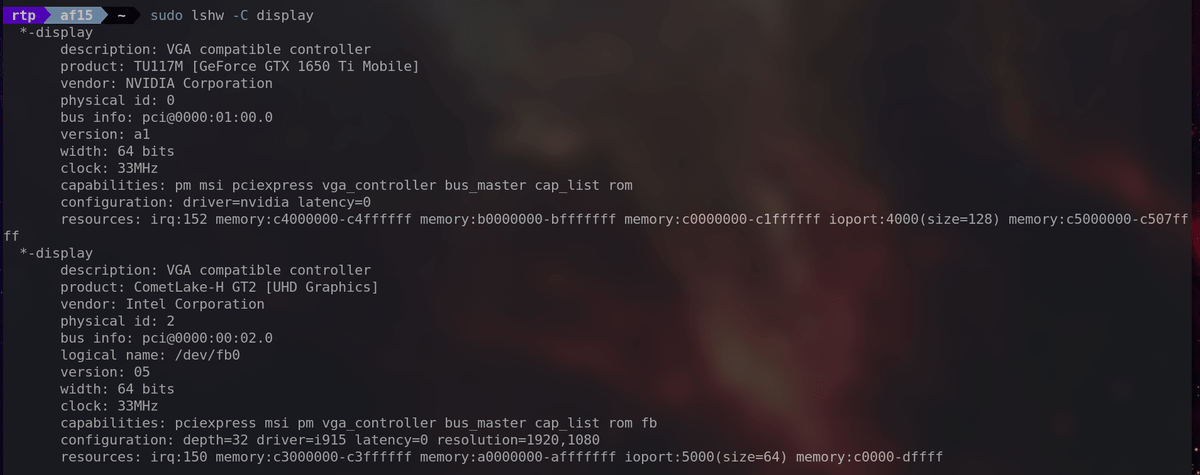
・「sudo lshw -C display」
グラフィックスカードを含む、システム内のディスプレイコントローラーに関する詳細情報を提供します。
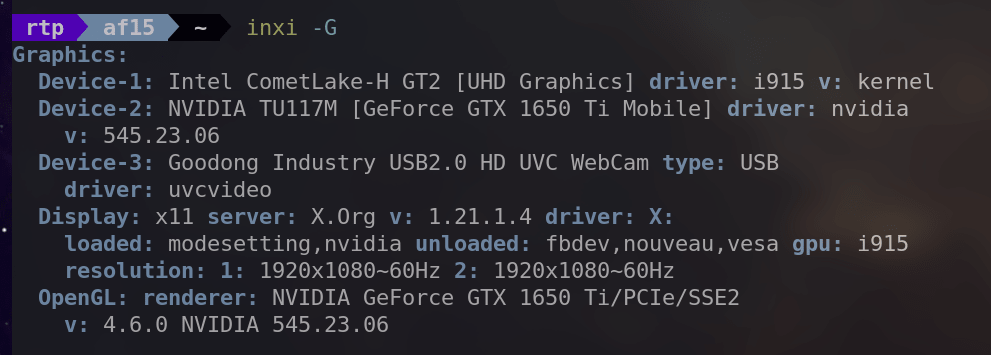
・「inxi -G」
GPUやディスプレイに関する詳細を含めて、グラフィックスサブシステムに関する情報を提供します。
・「sudo hwinfo --gfxcard」
システムのグラフィックスカードに関する詳細情報を取得できます。

◆CUDAフレームワークを使ってみる
GPUの並列化を実証するため、下記の2つの配列の要素をそれぞれ足すタスクを行ってみます。
配列A:[1,2,3,4,5,6]
配列B:[7,8,9,10,11,12]
要素をそれぞれ足すと次のようになります。
配列C:[1+7,2+8,3+9,4+10,5+11,6+12]=[8,10,12,14,16,18]
この計算を行うコードをCPUで実装すると次のようになるはずです。配列の要素を一つずつ確認し、順番に加算を行います。
#include <stdio.h>
int a[] = {1,2,3,4,5,6};
int b[] = {7,8,9,10,11,12};
int c[6];
int main() {
int N = 6; // 要素の数
for (int i = 0; i < N; i++) {
c[i] = a[i] + b[i];
}
for (int i = 0; i < N; i++) {
printf("c[%d] = %d", i, c[i]);
}
return 0;
}
扱う数値の個数が多い場合でもパフォーマンスを保てるよう、CUDAで並列化して同時に全ての加算を行うコードは次の通り。「__global__」はこの関数がGPUで呼び出されるカーネル関数であることを示しており、「threadIdx.x」はスレッドのインデックスを表しています。
__global__ void vectorAdd(int* a, int* b, int* c)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
return;
}
カーネル関数が用意できたらmain関数の中を作成していきます。まずは変数を宣言。
int main(){
int a[] = {1,2,3,4,5,6};
int b[] = {7,8,9,10,11,12};
int c[sizeof(a) / sizeof(int)] = {0};
// GPUへのポインターを作成
int* cudaA = 0;
int* cudaB = 0;
int* cudaC = 0;
続いて「cudaMalloc」を使用してGPU内にメモリを確保します。
cudaMalloc(&cudaA,sizeof(a));
cudaMalloc(&cudaB,sizeof(b));
cudaMalloc(&cudaC,sizeof(c));
「cudaMemcpy」を使ってaとbの配列の中身をGPUにコピーします。
cudaMemcpy(cudaA, a, sizeof(a), cudaMemcpyHostToDevice);
cudaMemcpy(cudaB, b, sizeof(b), cudaMemcpyHostToDevice);
そして最初に作成したカーネル関数「vectorAdd」を起動します。「sizeof(a) / sizeof(a[0])」は「配列全体のサイズ / 配列の要素1つ分のサイズ」という意味で、要素数と同じ数だけvectorAddを起動するように設定しています。
vectorAdd <<<1, sizeof(a) / sizeof(a[0])>>> (cudaA, cudaB, cudaC);
計算結果をGPUから取得します。
cudaMemcpy(c, cudaC, sizeof(c), cudaMemcpyDeviceToHost);
最後は通常通りの方法で計算結果を出力。
for (int i = 0; i < sizeof(c) / sizeof(int); i++)
{
printf("c[%d] = %d", i, c[i]);
}
return 0;
}
上記のコードをGPU.cuという名前で保存し、「nvcc」コマンドでコンパイルします。出力される実行ファイルを起動すると下図の通り出力されました。コード全体はGitHubで公開されています。
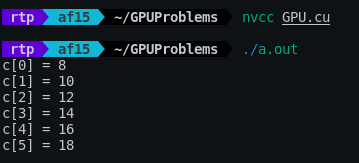
ラジェシュさんのブログ投稿ではこの他にも、CPUで4.07秒かかるマンデルブロ集合の生成タスクをGPUを使用して0.0046秒で処理する例や、ニューラルネットワークのトレーニングの例が掲載されているので、気になる人はチェックしてみてください。
・関連記事
AMDの最優先事項は「ROCm(Radeon Open Compute platform)」の発展だとAMD幹部が明言、オープンソースのプログラミング言語「Triton」の採用でNVIDIAに反撃へ - GIGAZINE
NVIDIAの独占を防ぐためにMicrosoftとAMDが協力体制を取っている - GIGAZINE
「CPU」「GPU」「NPU」「TPU」の違いを分かりやすく説明するとこうなる - GIGAZINE
GPUを開発・製造する企業は全世界で19社、PCやデータセンター向けGPUを設計する11社のうち8社が中国に拠点を置いている - GIGAZINE
生成AIや大規模言語モデルの開発で渇望されるハイエンドGPU「NVIDIA H100」が不足する理由とは? - GIGAZINE
・関連コンテンツ