




文字・画像と映像・音・3D深度・熱・動作を統合して現実世界を理解できるAI「ImageBind」をMetaがオープンソースで公開
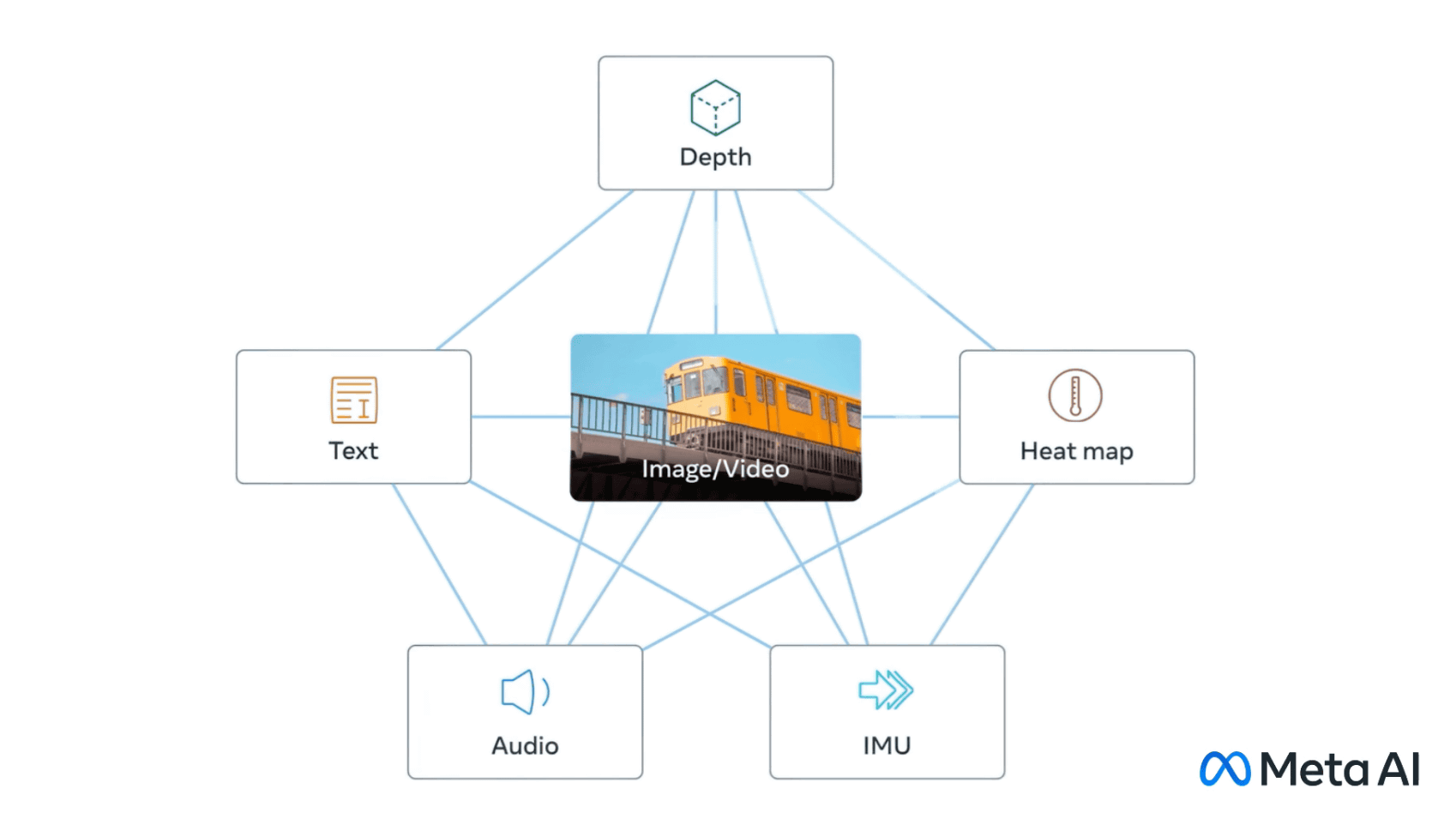
人が外界を認識する時、「人通りの多い通りを見ながら、車のエンジン音を聞く」というように、視覚・聴覚・触覚・嗅覚・味覚という複数の感覚を同時に使います。MetaのAI開発部門であるMeta AIが、「テキスト」「画像と映像」「音声」「動きを計算する深度(3D)」「赤外線による熱」「慣性測定ユニット(IMU)による動き」という6つのデータを統合するオープンソースのAIモデル「ImageBind」を発表しました。
ImageBind: Holistic AI learning across six modalities
https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
IMAGEBIND: One Embedding Space To Bind Them All
(PDFファイル)https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
GitHub - facebookresearch/ImageBind: ImageBind One Embedding Space to Bind Them All
https://github.com/facebookresearch/ImageBind
以下のムービーを見ると、ImageBindによってどういうことが可能になるのかがよくわかります。
Metaが発表したオープンソースのAIモデル「ImageBind」は文字・画像と映像・音・3D・熱・動作を統合できる - YouTube
画像認識AIや画像生成AIの学習に使われるように、画像や動画とテキストを結び付けるデータセットは多く存在しています。

ImageBindは、画像や動画を橋渡し役として、テキストの他に「音声」「3D深度」「熱」「動き」という4種類の自己教師あり学習用データを統合します。Metaによると、熱や3D深度は画像と強い相関があるため、データセットの整列が容易だとのこと。ただし、IMUで測定した動きや音声については相関性が弱いため、赤ちゃんの泣き声のように視覚的なコンテキストに付随するデータになるそうです。
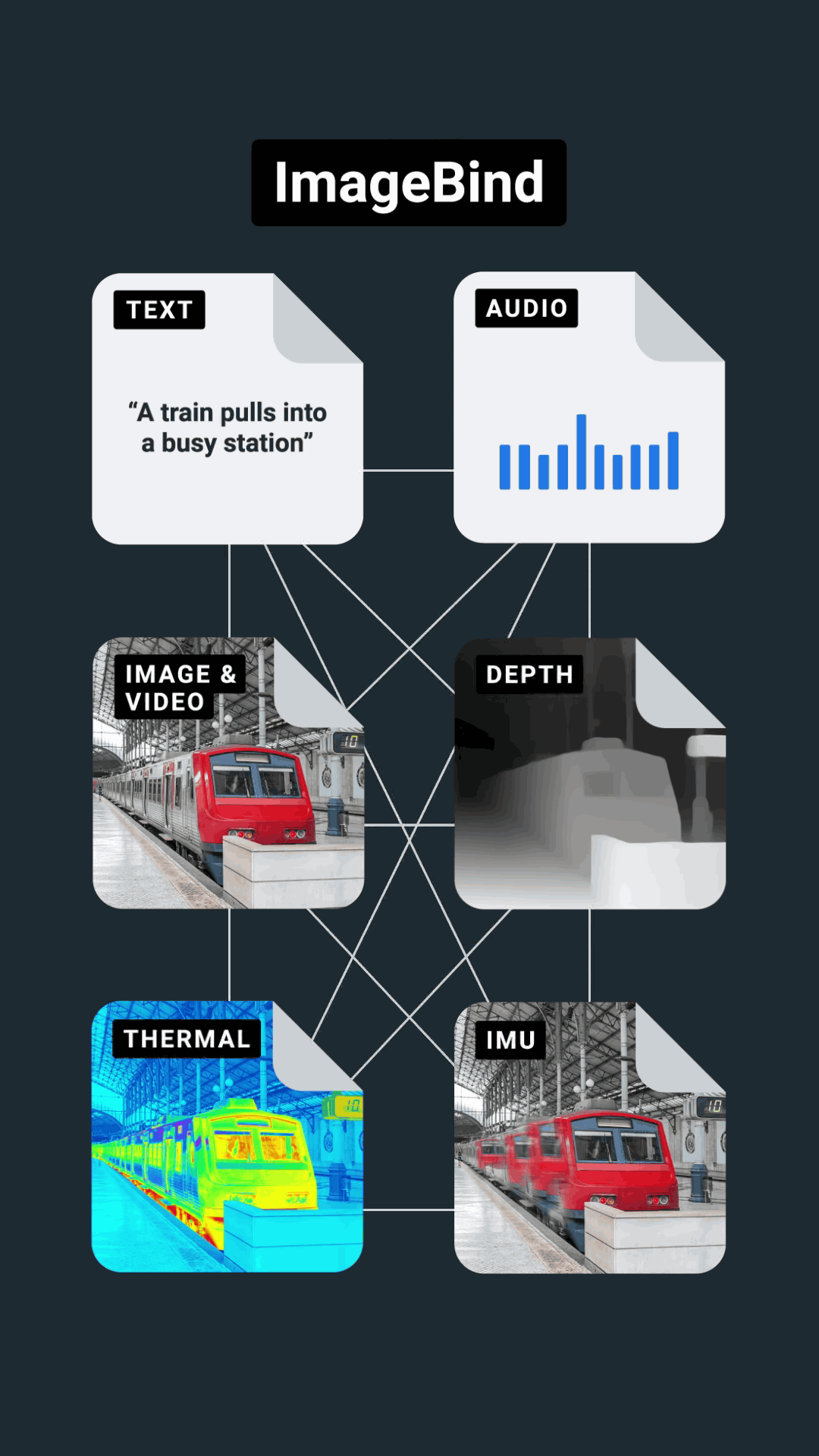
ImageBindで画像や動画を中心に6つのデータを統合した「マルチモーダル学習」によって、AIはリソースを大量に消費するトレーニングなしに、コンテンツをより全体的に解釈することが可能となります。

従来の画像生成AIはテキストから画像や動画を生成することができますが、ImageBindを使うことで、笑い声や雨の音から画像を生成することも可能になるとのこと。例えば、「Small creature(小さな生き物)」というテキスト、森の画像、森の中で雨が降る音、鳥の動きをIMUで計測したデータをプロンプトとして入力します

すると、「雨が降る森の中でかわいらしく動く小さな生き物」のアニメーションをAIで生成できるというわけ。

Metaは「今回の研究では6つのデータの統合を検討しましたが、触覚や嗅覚、脳のfMRI信号など、できるだけ多くの感覚を結び付けることで、より豊かな人間中心のAIモデルが可能になると考えています」と述べています。ただし、マルチモーダル学習はまだ解明されていないことがたくさんあるとのことで、MetaはImageBindがマルチモーダル学習研究の第一歩になるとしています。
・関連記事
オープンソースで商用利用可能な言語モデル「MPT-7B」リリース、GPT-4の2倍の長さの文章を受け付ける - GIGAZINE
FacebookやInstagramに画像生成AIを搭載する計画をマーク・ザッカーバーグCEOが語る - GIGAZINE
Metaが映像処理モデル「DINOv2」を発表、将来はAIにより没入型VR環境が作れる可能性 - GIGAZINE
無料でキャラクターイラスト1枚からぬるぬる動くアニメーションを作成するAI「Animated Drawings」をMeta AIがリリース - GIGAZINE
Metaが写真に写っている物体を分離して選択できるAIモデル「Segment Anything Model」を公開 - GIGAZINE
・関連コンテンツ





in AI, 動画, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article Meta publishes open source AI 'ImageBind….