Meta publishes open source AI 'ImageBind' that can understand the real world by integrating characters / images and video / sound / 3D depth / heat / motion
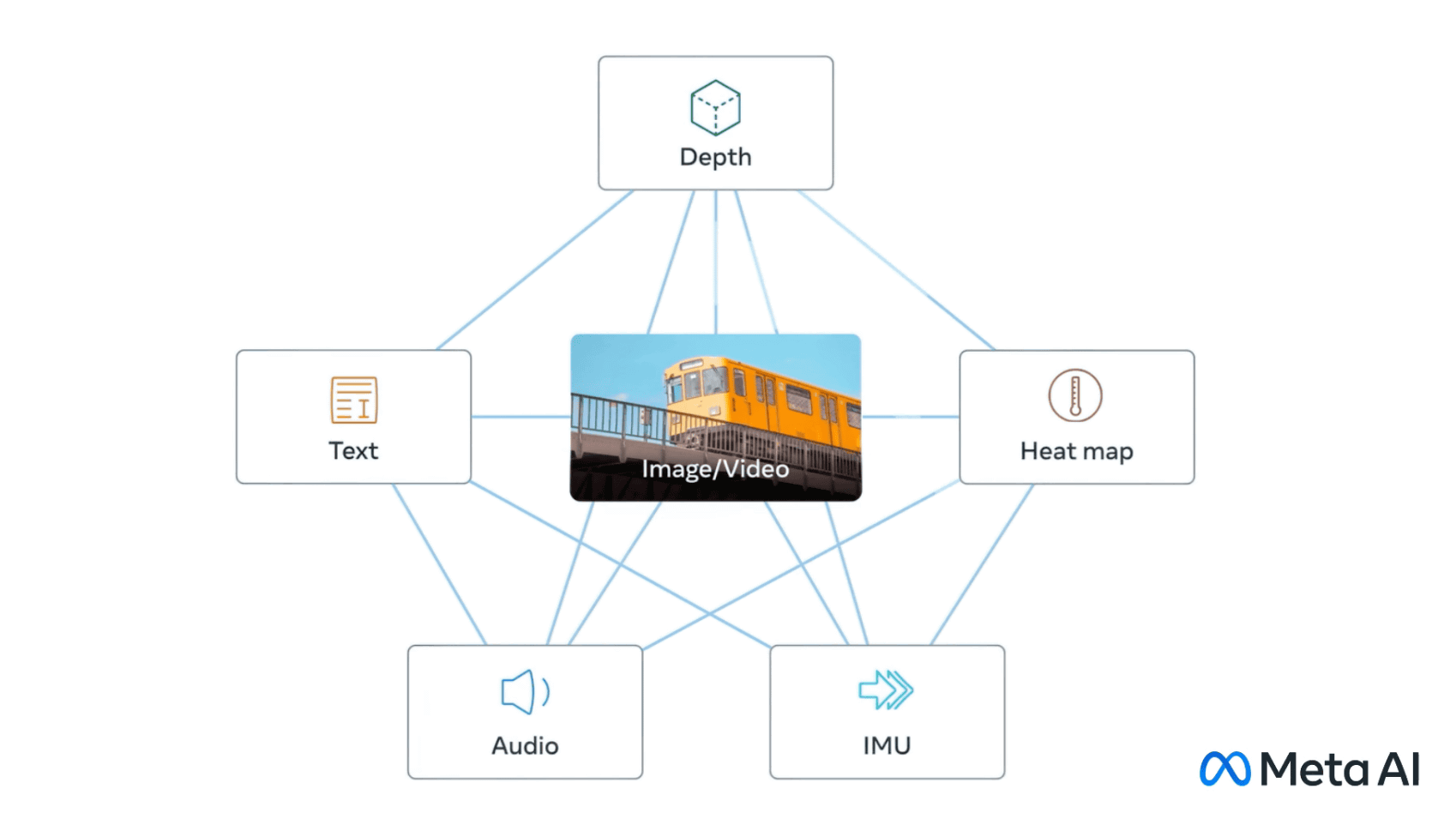
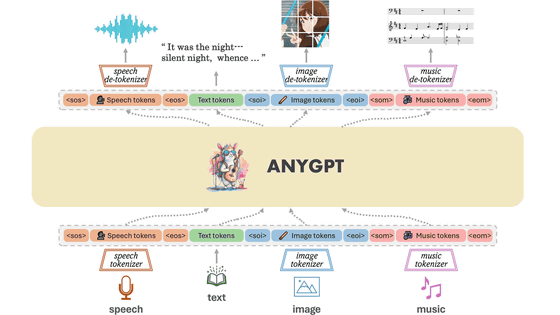
When a person perceives the outside world, they use multiple senses such as sight, hearing, touch, smell, and taste at the same time. Meta AI, Meta's AI development department, has six categories: ``text'', ``image and video'', ``voice'', ``depth for calculating movement (3D)'', ``heat by infrared rays'', and ``movement by inertial measurement unit (IMU)''. Announcing ImageBind , an open-source AI model that integrates data.
ImageBind: Holistic AI learning across six modalities
IMAGEBIND: One Embedding Space To Bind Them All
(PDF file) https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
GitHub - facebookresearch/ImageBind: ImageBind One Embedding Space to Bind Them All
https://github.com/facebookresearch/ImageBind
Looking at the movie below, you can see what ImageBind can do.
The open source AI model 'ImageBind' announced by Meta can integrate characters/images with video/sound/3D/heat/motion-YouTube
There are many datasets that connect images and videos with text, such as those used for training image recognition AI and image generation AI.

ImageBind integrates text and four types of
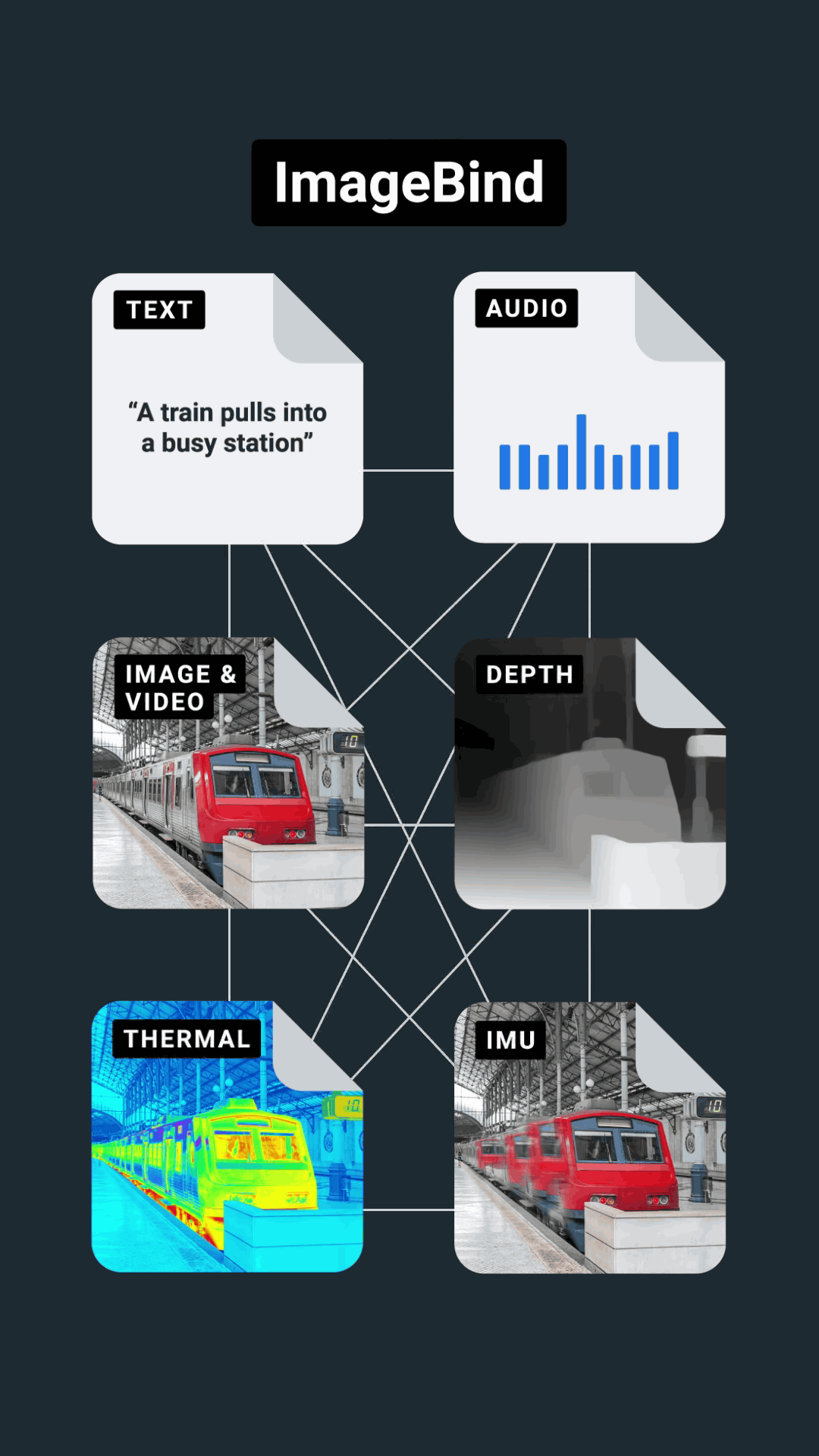
'Multimodal learning', which integrates 6 types of data centered on images and videos with ImageBind, allows AI to interpret content more holistically without resource-intensive training.

Conventional image generation AI can generate images and movies from text, but by using ImageBind, it is also possible to generate images from laughter and rain sounds. For example, enter the text 'Small creature', an image of the forest, the sound of rain falling in the forest, and the data of the movement of the birds measured by the IMU as a prompt.

Then, AI can generate an animation of `` a cute little creature that moves in the raining forest ''.

Meta said, ``In this study, we considered integrating six types of data, but we believe that connecting as many senses as possible, such as touch, smell, and fMRI signals of the brain, will enable a richer human-centered AI model. I am.” However, there are many things that have not been clarified about multimodal learning yet, and Meta says that ImageBind will be the first step in multimodal learning research.
Related Posts: