Introducing 'VGGT', which can automatically extract key 3D information from images and videos at high speed, including camera parameters, point maps, depth maps, and 3D point tracks.

A research team from the University of Oxford and Meta's AI research division have announced a new AI model called ' VGGT ' that extracts 3D information from images. Conventional technology requires complex computational processing to obtain 3D information, but VGGT can quickly calculate the camera position and orientation, object depth, and the position of points in 3D space directly from the image in a single process.
VGGT: Visual Geometry Grounded Transformer
[2503.11651] VGGT: Visual Geometry Grounded Transformer
https://arxiv.org/abs/2503.11651
VGGT stands for 'Visual Geometry Grounded Transformer' and is characterized by its ability to simultaneously process a variety of 3D information with a single feedforward neural network , unlike conventional 3D computer vision techniques. VGTT can directly infer all important 3D attributes such as camera parameters, depth maps, point maps, and 3D point tracks using one to hundreds of images as input. In particular, it achieves high-quality 3D reconstruction in a short time of less than one second while omitting the optimization process required by conventional methods.
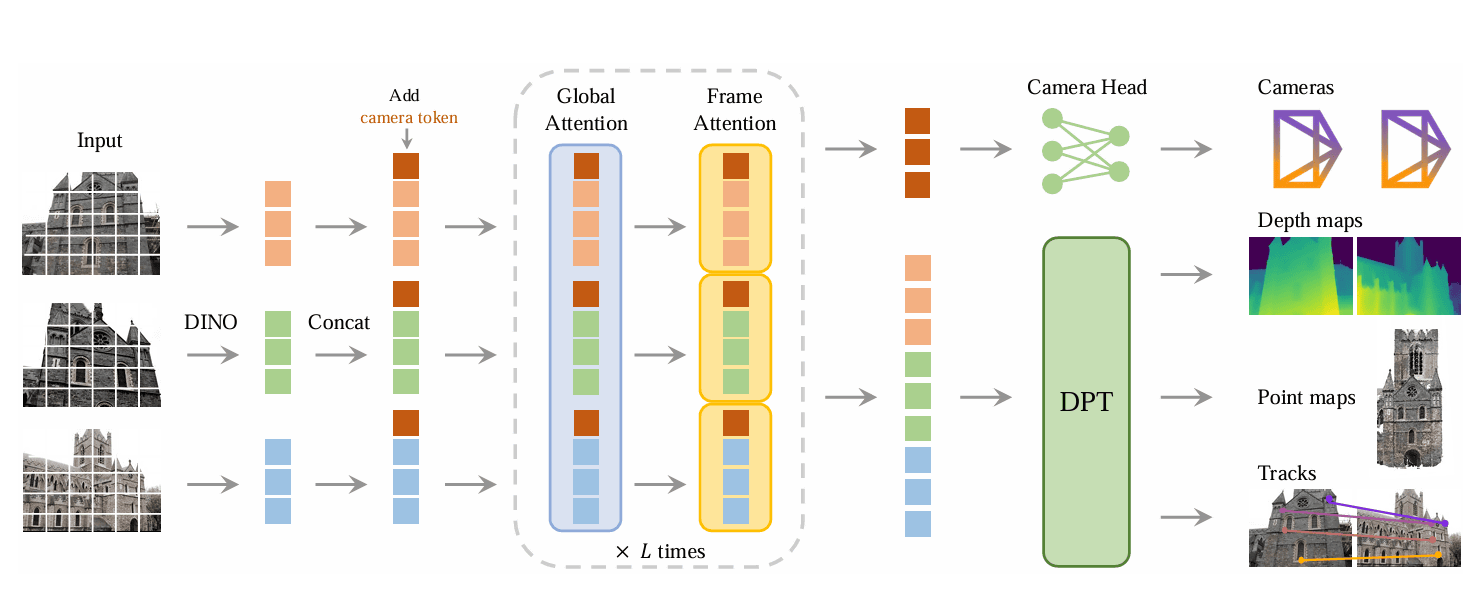
VGGT has a relatively simple design and is trained on a large 3D annotated dataset. In VGGT, the input image is first divided into small parts called patches using a technique called DINO, and then converted into tokens. These tokens are then supplemented with extra information called 'camera tokens,' which provide clues for predicting the camera's position and orientation.
The core of the model then alternates between two mechanisms: framewise attention and global attention. Framewise attention captures relationships within an image, while global attention captures relationships across multiple images, balancing the details within a single image with the consistency across multiple images.
Finally, the processed information is sent to the 'camera head' which provides the camera parameters, and the 'DPT head' which generates the depth map, point map, and features for object tracking.
The 3D information generated by VGGT from an aerial movie of

From the video that was shot all around the room, 3D information showing the structure of the room was generated.

If you zoom in, you can see that the interior structure is also pointed to properly.

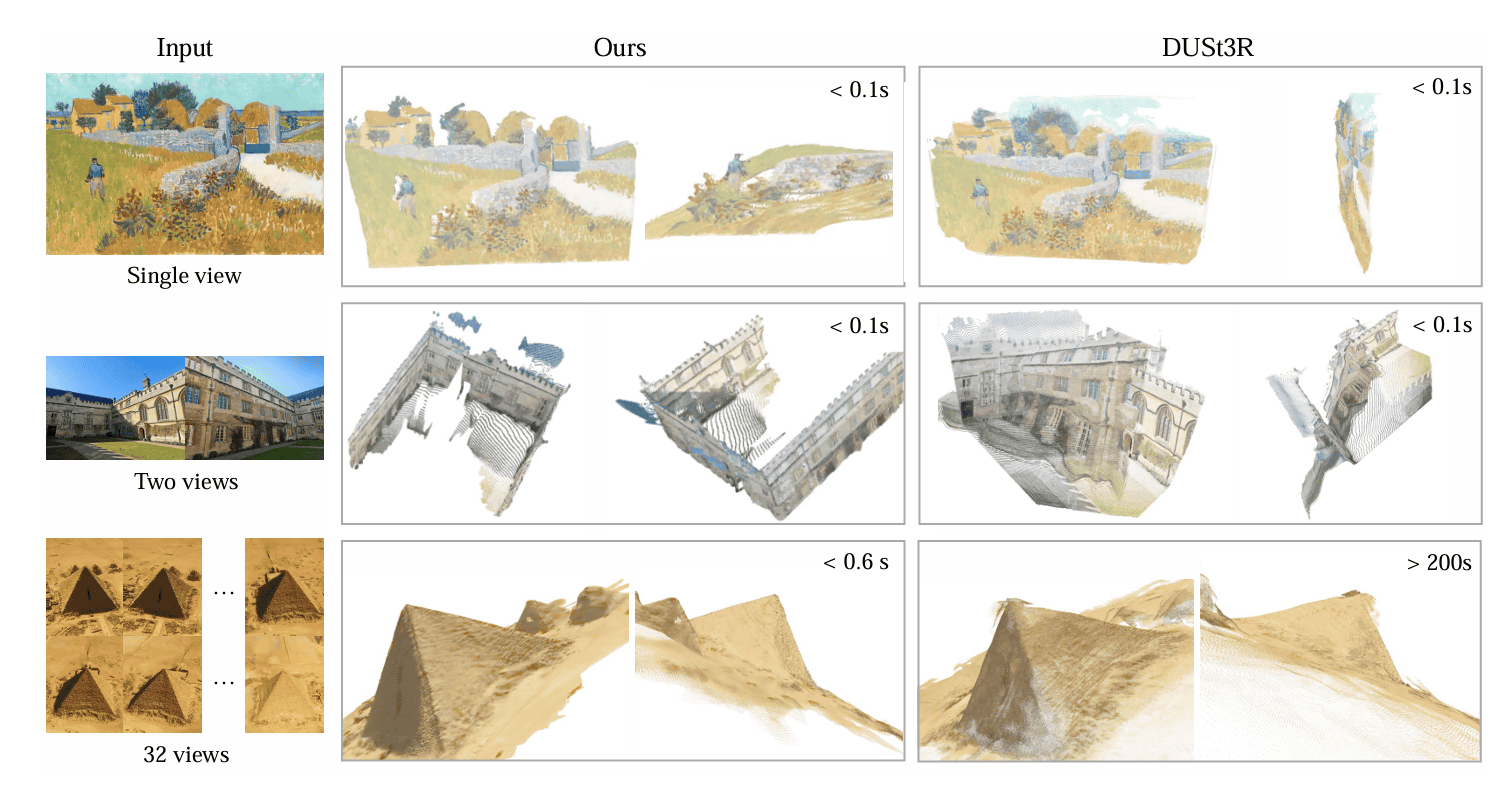
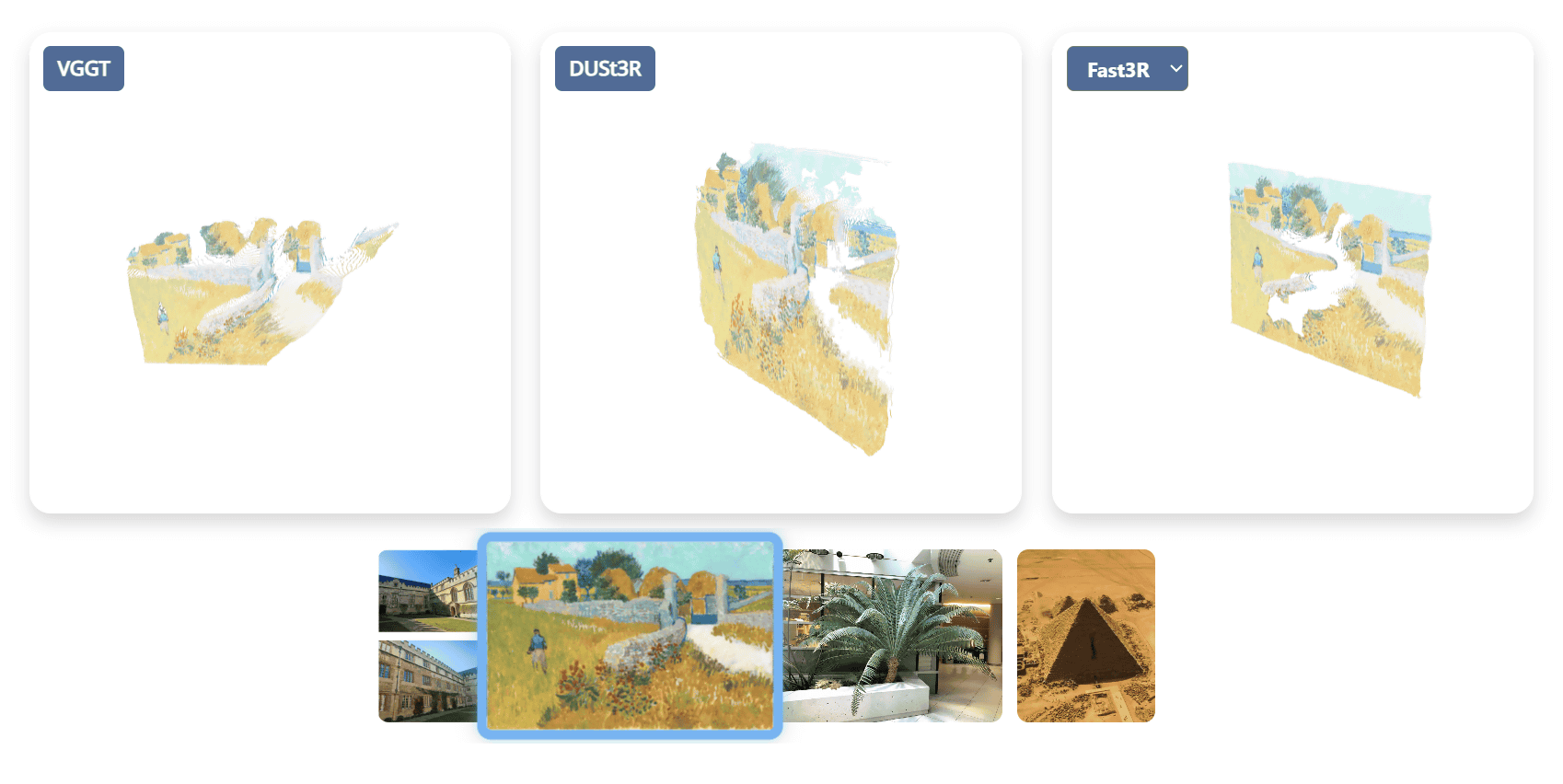
Comparing the 3D information extracted from two images by VGGT with that by

When generating 3D information from a single painting, DUSt3R and Fast3R produced planar information, but the 3D information generated by VGGT produced a fairly three-dimensional point cloud.
The research team has made the VGGT code and models available on GitHub with the aim of 'stimulating further research in the field of 3D computer vision and benefiting the entire community.'
GitHub - facebookresearch/vggt: [CVPR 2025] VGGT: Visual Geometry Grounded Transformer
https://github.com/facebookresearch/vggt
In addition, a demo of VGTT is available in the Hugging Face space, and you can actually upload photos and videos to generate a 3D model. Demo videos and photos are also available, so if you're interested, please check them out.
vggt - a Hugging Face Space by facebook
https://huggingface.co/spaces/facebook/vggt
Related Posts:







in Software, Posted by log1i_yk