




Metaが映像処理モデル「DINOv2」を発表、将来はAIにより没入型VR環境が作れる可能性

Metaが2023年4月17日に、映像モデルをトレーニングする新しい手法である「DINOv2」を発表しました。自己教師あり学習により映像を高度に理解するこの新手法により、将来的には単純な指示やプロンプトからVR世界を構築できるジェネレーティブAIが登場すると期待されています。
[2304.07193] DINOv2: Learning Robust Visual Features without Supervision
https://doi.org/10.48550/arXiv.2304.07193
DINOv2: State-of-the-art computer vision models with self-supervised learning
https://ai.facebook.com/blog/dino-v2-computer-vision-self-supervised-learning/
Meta Outlines its Latest Image Recognition Advances, Which Could Facilitate its Metaverse Vision | Social Media Today
https://www.socialmediatoday.com/news/Meta-Shares-Latest-Image-Recognition-Developments/647894/
Metaが今回発表した「DINOv2」のデモンストレーション映像が以下。「DINOv2」はMetaが以前発表した「DINO」という画像モデルの発展系で、動的な映像を取り込んで従来のものより高精度なセグメンテーションを生成することができます。
Announced by Mark Zuckerberg this morning — today we're releasing DINOv2, the first method for training computer vision models that uses self-supervised learning to achieve results matching or exceeding industry standards.
— Meta AI (@MetaAI) April 17, 2023
More on this new work ➡️ https://t.co/h5exzLJsFt pic.twitter.com/2pdxdTyxC4
Metaによると、これまでの視覚的タスクの標準的なアプローチとなっている「画像-テキスト事前学習」という手法は、手動で書かれたキャプションに依存したものであるため、テキストで明示的に言及されていない情報が無視されてしまうとのこと。
例えばイスが置かれた部屋に「1脚のオーク材のイス」というラベルがつけられていたとすると、その部屋がどんな部屋かの情報が欠落してしまいます。また、顕微鏡で捉えた細胞の映像に正しくラベルをつけられる専門家が一握りしかいないように、人間によってキャプションをつけなければならないという部分がボトルネックになる場合も考えられます。
しかし、DINOv2は自己教師あり学習を採用していて人間によるキャプションが必要ないため、背景や人間の説明が困難なデータも余すところなくモデルに組み込むことができます。また、映像の中に何があるのか、状況に応じて何をどこに配置するべきなのかを理解するAIの構築にも役立つとされており、特にVRコンテンツの開発に大きな優位性を持ちます。

Metaは自然再生事業を行う非営利団体・WRI Restorationと共同で、大陸ほどの面積の森林を樹木1本単位でマッピングすることに成功しました。
Models like this will be useful in a wide variety of applications. For example, we recently collaborated with @RestoreForward to use AI to map forests, tree-by-tree, across areas the size of continents. pic.twitter.com/T2we4cqTa4
— Meta AI (@MetaAI) April 17, 2023
Metaが公開しているDINOv2のデモサイトでは、実際に写真の深度推定を行わせることが可能。試しに風景の写真を読み込ませてみたところ、木や雲海、その向こうに見える山をきちんと捉えることができることが示されました。

巣穴からひょっこり顔を出す子ギツネたちの輪郭も正確に捉えています。
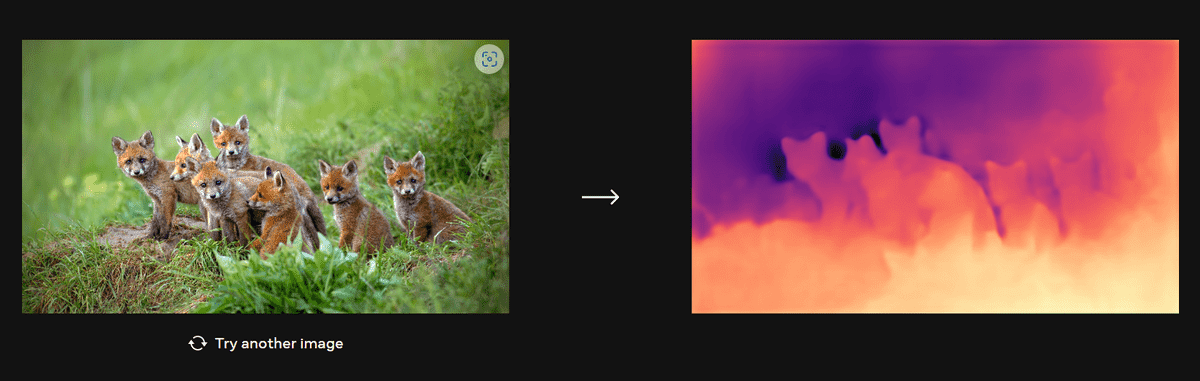
DINOv2を使用すると、ビデオチャットのデジタル背景の改善や、映像コンテンツのタグ付け、新しいタイプのARコンテンツやビジュアルツールなどが実現すると期待されているとのこと。ひいては、AIが生成するVR世界の開発も可能になり、最終的にはインタラクティブな仮想環境を丸ごと構築することも不可能ではないと、海外メディアのSocial Media Todayはコメントしました。
MetaはDINOv2をオープンソース化しており、PyTorchコードとしてGitHubから誰でも入手することが可能になっています。
GitHub - facebookresearch/dinov2: PyTorch code and models for the DINOv2 self-supervised learning method.
https://github.com/facebookresearch/dinov2
・関連記事
無料でキャラクターイラスト1枚からぬるぬる動くアニメーションを作成するAI「Animated Drawings」をMeta AIがリリース - GIGAZINE
Metaが写真に写っている物体を分離して選択できるAIモデル「Segment Anything Model」を公開 - GIGAZINE
Metaが動画生成AI「Make A Video」発表、空飛ぶスーパードッグや自画像を描くテディベアの動画を公開 - GIGAZINE
Metaが大規模言語モデル「LLaMA」を発表、GPT-3に匹敵する性能ながら単体のGPUでも動作可能 - GIGAZINE
Metaのマーク・ザッカーバーグCEOがInstagram・WhatsApp・Messenger向けのAI開発チームを設立したことを発表 - GIGAZINE
AIを駆使した音声翻訳システムをMetaが公開、テキストデータの収集が困難なマイナー言語にも対応 - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article Meta announces video processing model 'D….