Meta announces video processing model 'DINOv2', possibility of creating immersive VR environment by AI in the future

On April 17, 2023, Meta announced `` DINOv2 '', a new method for training video models. This new method of advanced video understanding through
[2304.07193] DINOv2: Learning Robust Visual Features without Supervision
https://doi.org/10.48550/arXiv.2304.07193
DINOv2: State-of-the-art computer vision models with self-supervised learning
Meta Outlines its Latest Image Recognition Advances, Which Could Facilitate its Metaverse Vision | Social Media Today
Below is a demonstration video of 'DINOv2' announced by Meta. 'DINOv2' is an extension of Meta's previously announced image model '
Announced by Mark Zuckerberg this morning — today we're releasing DINOv2, the first method for training computer vision models that uses self-supervised learning to achieve results matching or exceeding industry standards.
— MetaAI (@MetaAI) April 17, 2023
More on this new work ➡️ https://t.co/h5exzLJsFt pic.twitter.com/2pdxdTyxC4
According to Meta, the standard approach for visual tasks so far, image-text pre-training, relies on manually written captions, so they are explicitly mentioned in the text. Information that has not been done will be ignored.
For example, if the room in which the chair is placed is labeled 'one oak chair', the information about what kind of room the room is will be missing. The bottleneck may also be the need for human captioning, as there are only a handful of experts who can correctly label microscopic images of cells.
However, because DINOv2 employs self-supervised learning and does not require human captions, the model can fully incorporate background and data that are difficult for humans to explain. In addition, it is said to be useful for building AI that understands what is in the video and what should be placed where according to the situation, and has a great advantage especially in the development of VR content.

In collaboration with WRI Restoration, a non-profit organization that conducts nature restoration projects, Meta succeeded in mapping a forest as large as a continent in units of one tree.
Models like this will be useful in a wide variety of applications. For example, we recently collaborated with @RestoreForward to use AI to map forests, tree-by-tree, across areas the size of continents.pic.twitter.com/T2we4cqTa4
— MetaAI (@MetaAI) April 17, 2023
On the DINOv2 demo site published by Meta, it is possible to actually estimate the depth of a photo. When I tried loading a landscape photo as a trial, it was shown that trees, a sea of clouds, and mountains that can be seen beyond them can be captured properly.

It also accurately captures the outlines of baby foxes popping out of their burrows.
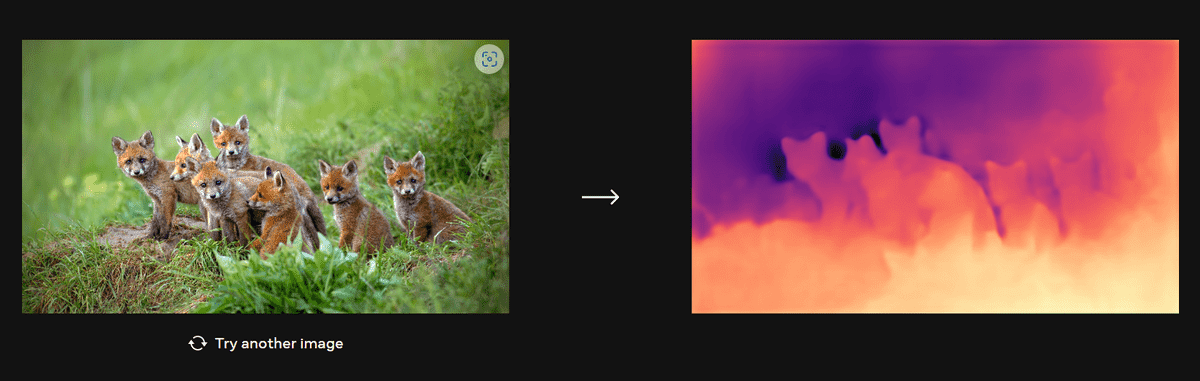
Using DINOv2 is expected to improve digital backgrounds for video chats, tagging video content, new types of AR content and visual tools, and more. As a result, it will be possible to develop a VR world generated by AI, and eventually it will not be impossible to build an entire interactive virtual environment, commented overseas media Social Media Today.
Meta has open sourced DINOv2 and made it available to anyone on GitHub as PyTorch code.
GitHub - facebookresearch/dinov2: PyTorch code and models for the DINOv2 self-supervised learning method.
Related Posts:







in Software, Posted by log1l_ks