




DeepLでPDFファイルのレイアウトを崩さず丸ごと翻訳できるサードパーティChrome拡張機能「DeepL Opener」を使ってみた
2020年に登場して「めちゃくちゃ精度が高い」と話題になったオンライン翻訳サービスが「DeepL」です。直近では公式Chrome拡張機能の「DeepL翻訳(ベータ版)」が登場しており便利さに磨きが掛かっていますが、まだこれらのソフトウェア/アプリでは「PDFファイルの丸ごと翻訳」はできないようなので、PDFファイルの丸ごと翻訳ができるサードパーティのChrome拡張機能「DeepL opener」を使ってみました。
DeepL opener - Chrome ウェブストア
https://chrome.google.com/webstore/detail/deepl-opener/almdndhiblbhbnoaakhgefcpmbaoljde
DeepLによるページ翻訳、ドキュメント翻訳、PDF上への翻訳表示ができるChrome拡張機能「DeepLopener」の使い方 - Teahat
https://t3ahat.hateblo.jp/entry/How_to_use_DeepLopener
DeepL openerはDeepL翻訳が提供しているAPIを使ったサードパーティのChrome拡張機能なので、まずはこのAPI自体を取得する必要があります。今回は1カ月50万字まで無料というプランを使うので、DeepL Proのページから「開発者向け」を選び、「無料で登録する」をクリック。
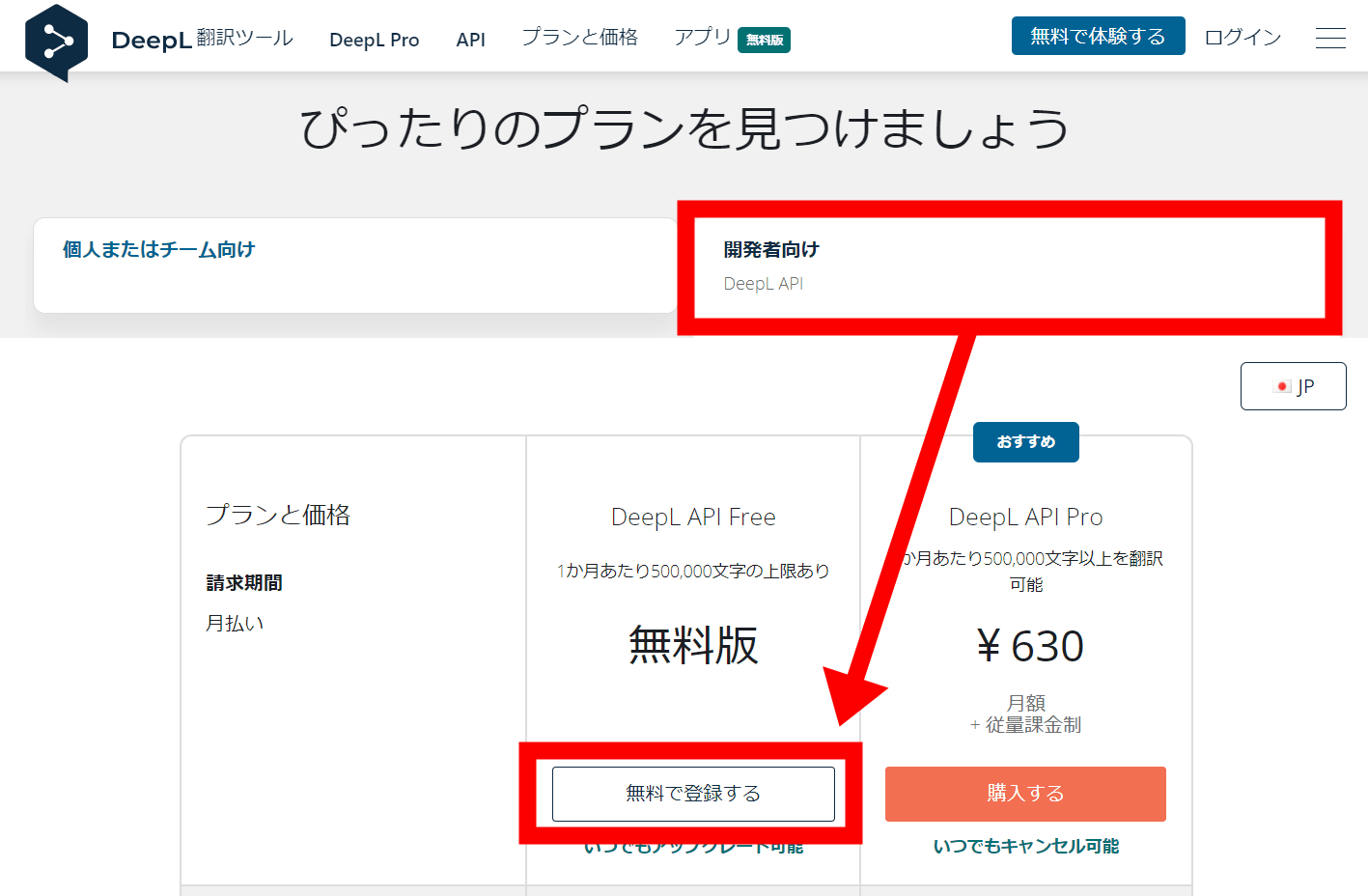
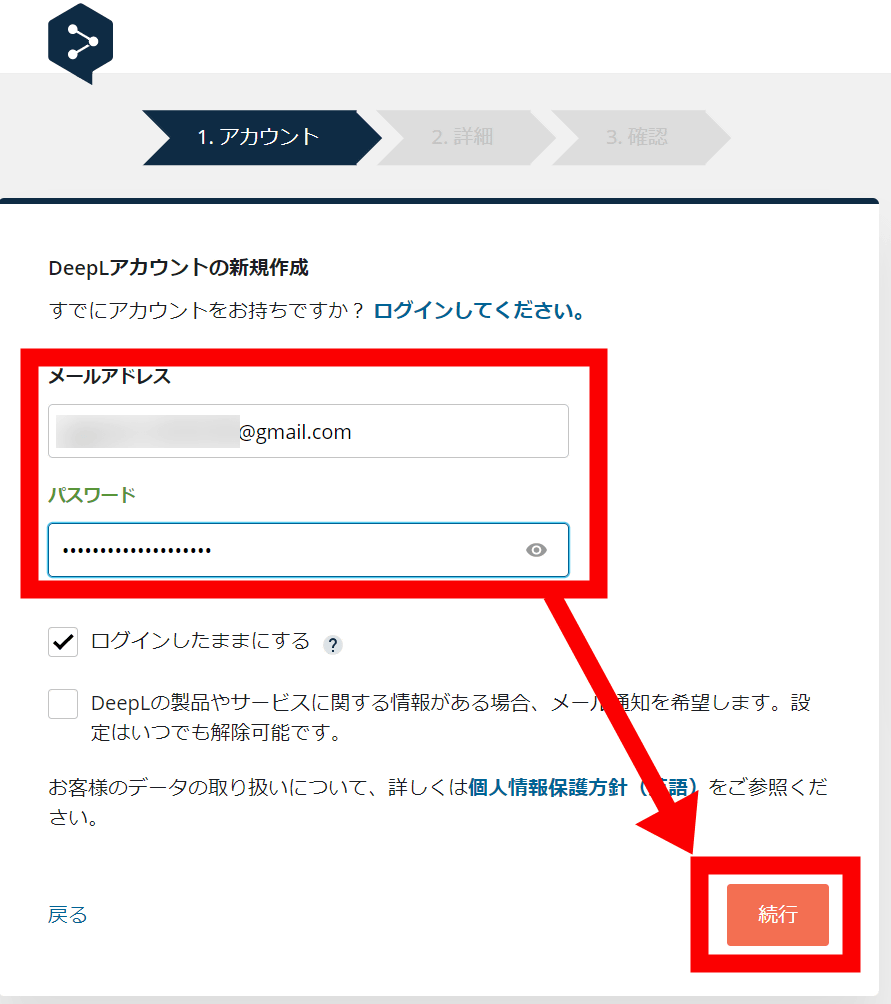
アカウントを新規作成する必要があるので、メールアドレスとパスワードを入力して「続行」をクリックします。
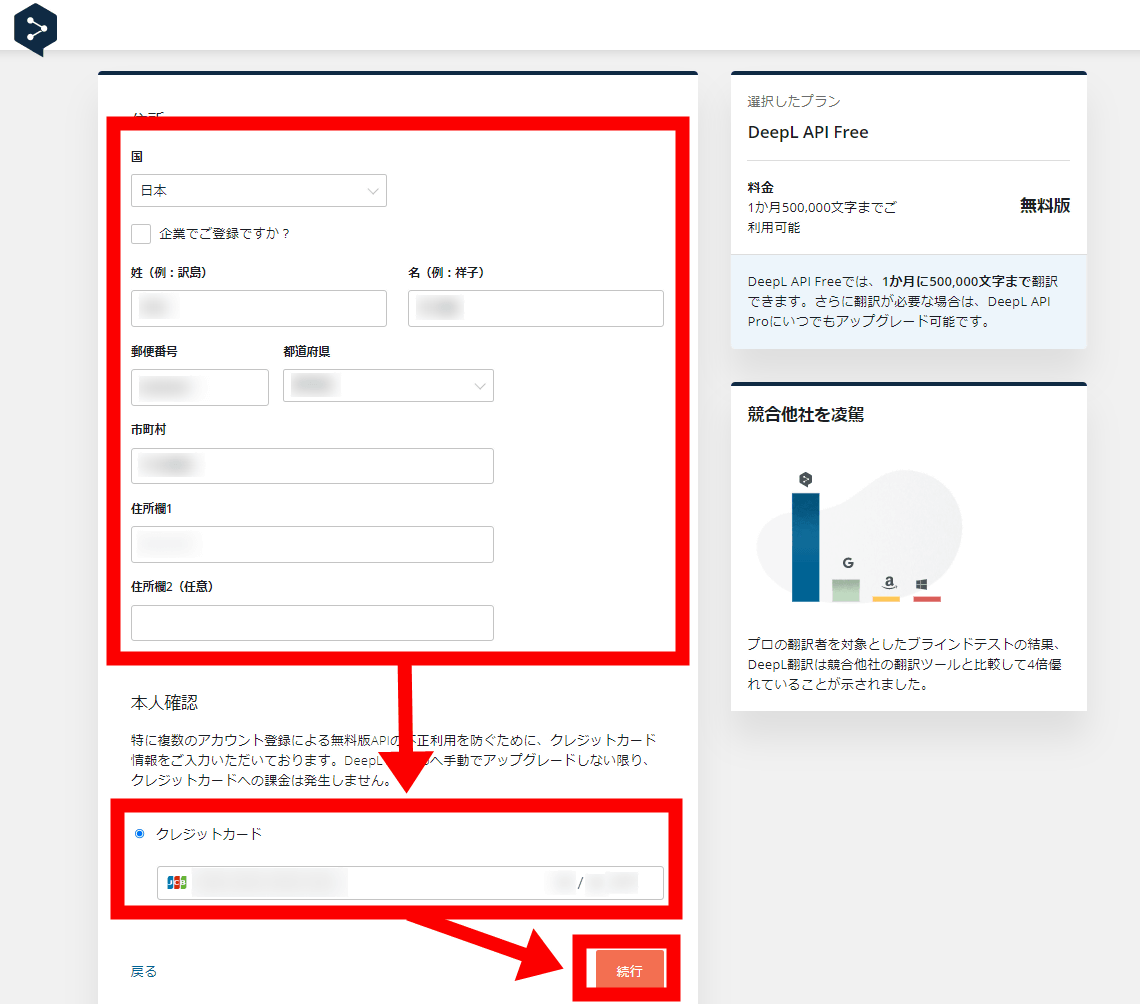
続いては本人認証のために、国籍・姓名・郵便番号・住所、そしてクレジットカード情報を入力して「続行」をクリック。なお、無料版でもクレジットカード情報が要求されるのは「特に複数のアカウント登録による無料版APIの不正利用を防ぐために、クレジットカード情報をご入力いただいております。DeepL API Proへ手動でアップグレードしない限り、クレジットカードへの課金は発生しません」とのことで、あくまで不正利用防止目的だそうです。
最後は利用規約に同意する旨にチェックを入れて、「無料で登録する」をクリックすれば登録完了。
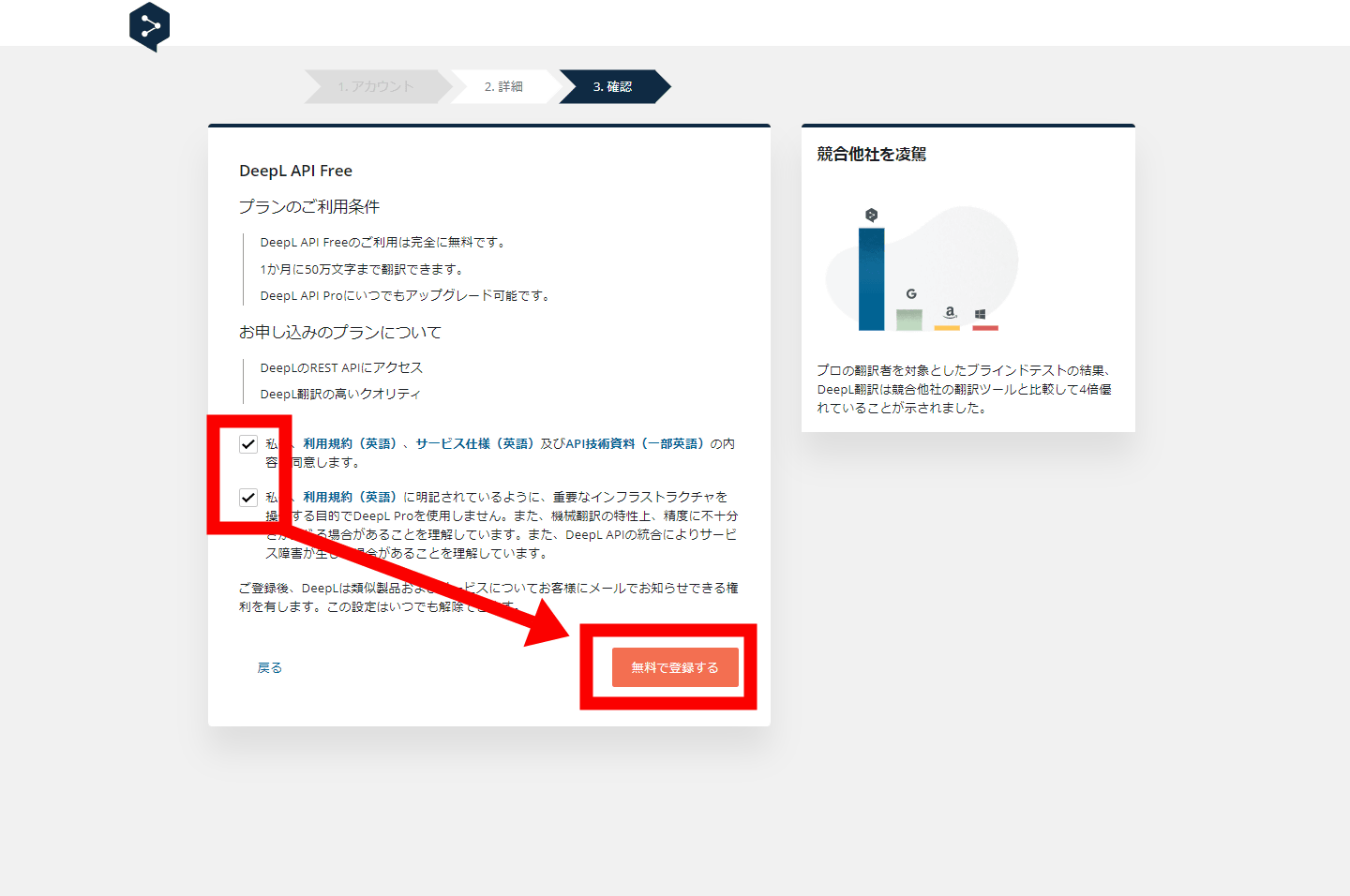
以下のような画面が表示されるので、右の「認証キーを管理する」をクリックします。
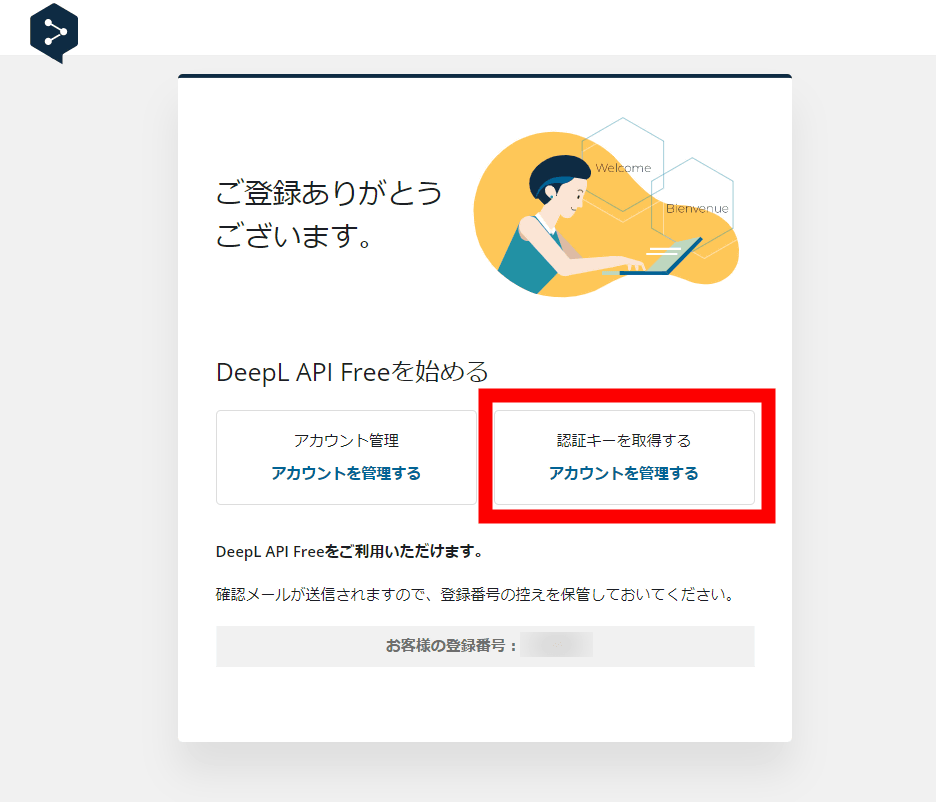
すると「ご利用中のDeepL Proアカウント」という画面に遷移するので、「アカウント」タブをクリックして「DeepL APIで使用する認証キー」に書かれている文字列をコピーして、DeepL APIの入手は完了。
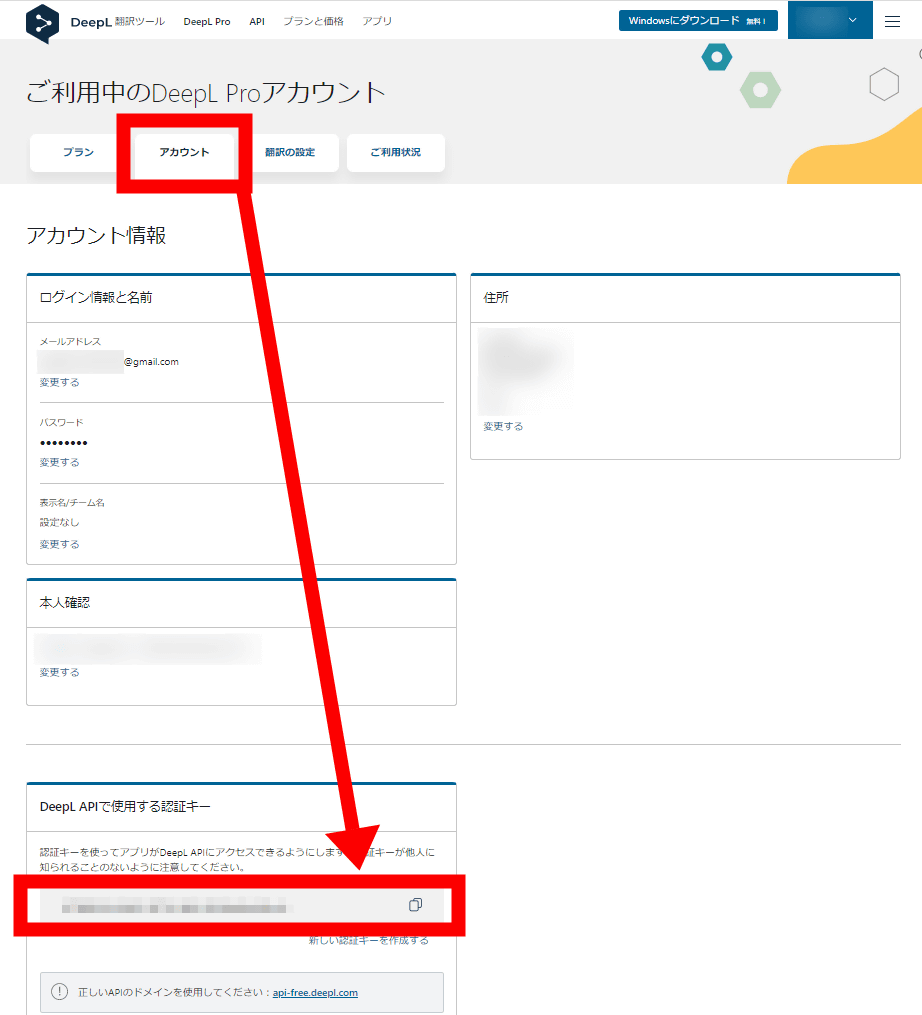
また、「翻訳の設定」タブから「PDFの翻訳時にAdobeへのファイル送信を常に許可する」をONにしておきます。この設定は、PDFを丸ごと翻訳したい場合には技術上の理由からAdobeを介さなければならないことが原因とのこと。
DeepL APIを手に入れたら、Chromeウェブストアで配布されている拡張機能「DeepL opener」をインストールします。ChromeやChromium系ブラウザでChromeウェブストアにアクセスし、「Chromeに追加」ボタンをクリック。

ウィンドウ上部からポップアップが出てくるので、「拡張機能を追加」をクリック。
すると以下のように拡張機能の設定画面が開きます。
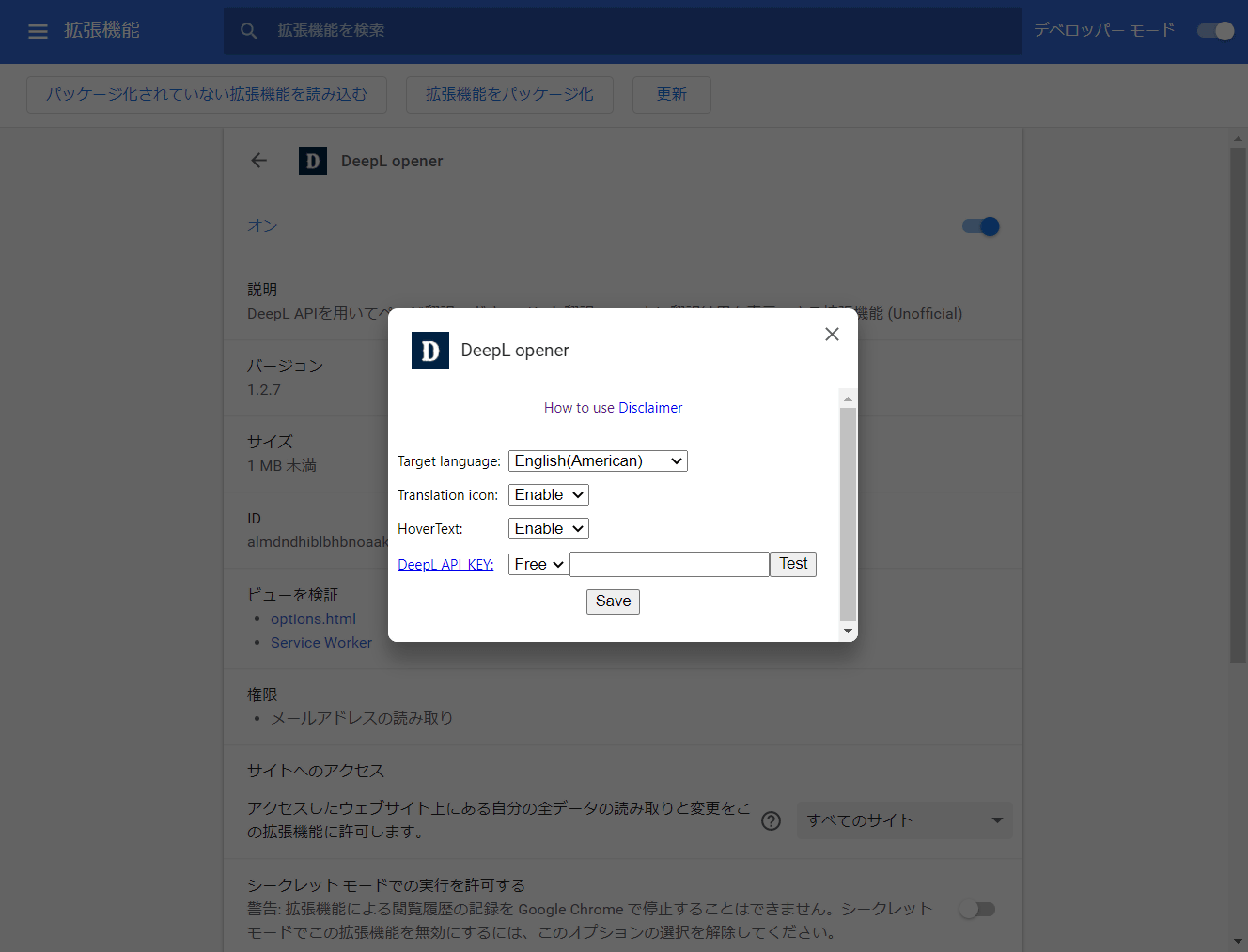
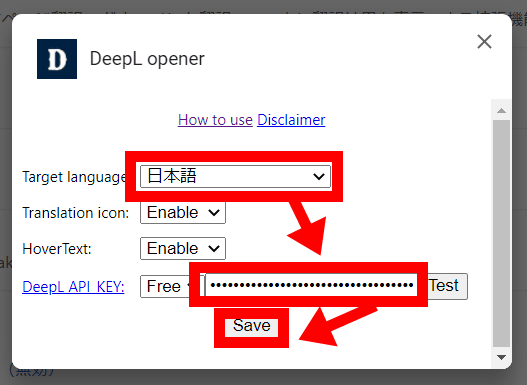
初回起動時には、中央に初期設定用のポップアップが表示されています。「Target language」を「日本語」に、「DeepL API KEY」に先ほど入手したDeepL APIを入力して、「Save」をクリックします。
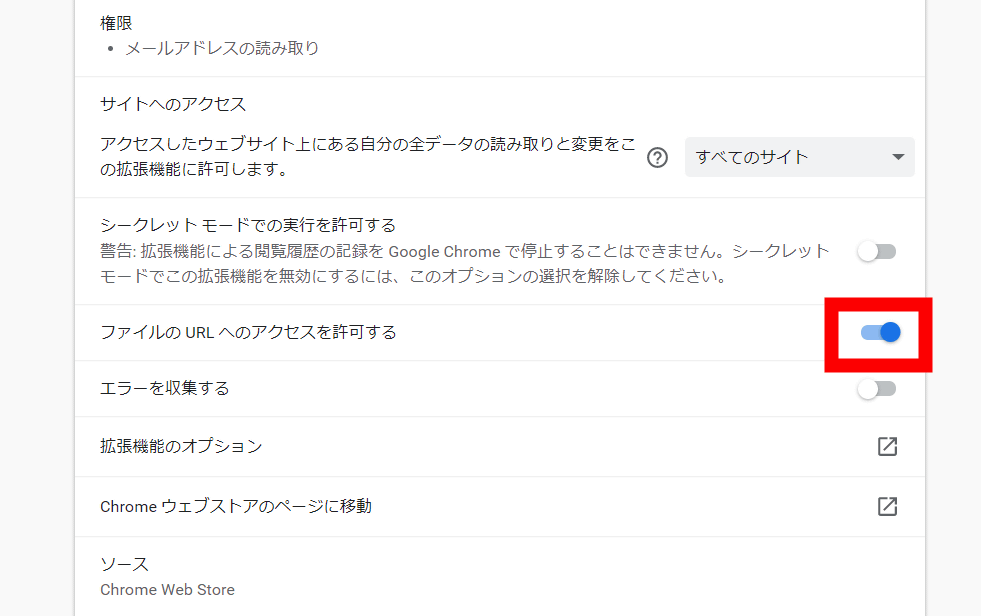
ローカルに保存されたPDFファイルを翻訳したい場合は、「ファイルのURLへのアクセスを許可する」のトグルをオンにしておきます。
また、Chromeにログインして同期を有効化する必要があるため、同期がオンになっていることを確認しておきます。
同期のオン/オフの切り替え方法は以下を参照。
Chrome で同期のオンとオフを切り替える - パソコン - Google Chrome ヘルプ
https://support.google.com/chrome/answer/185277
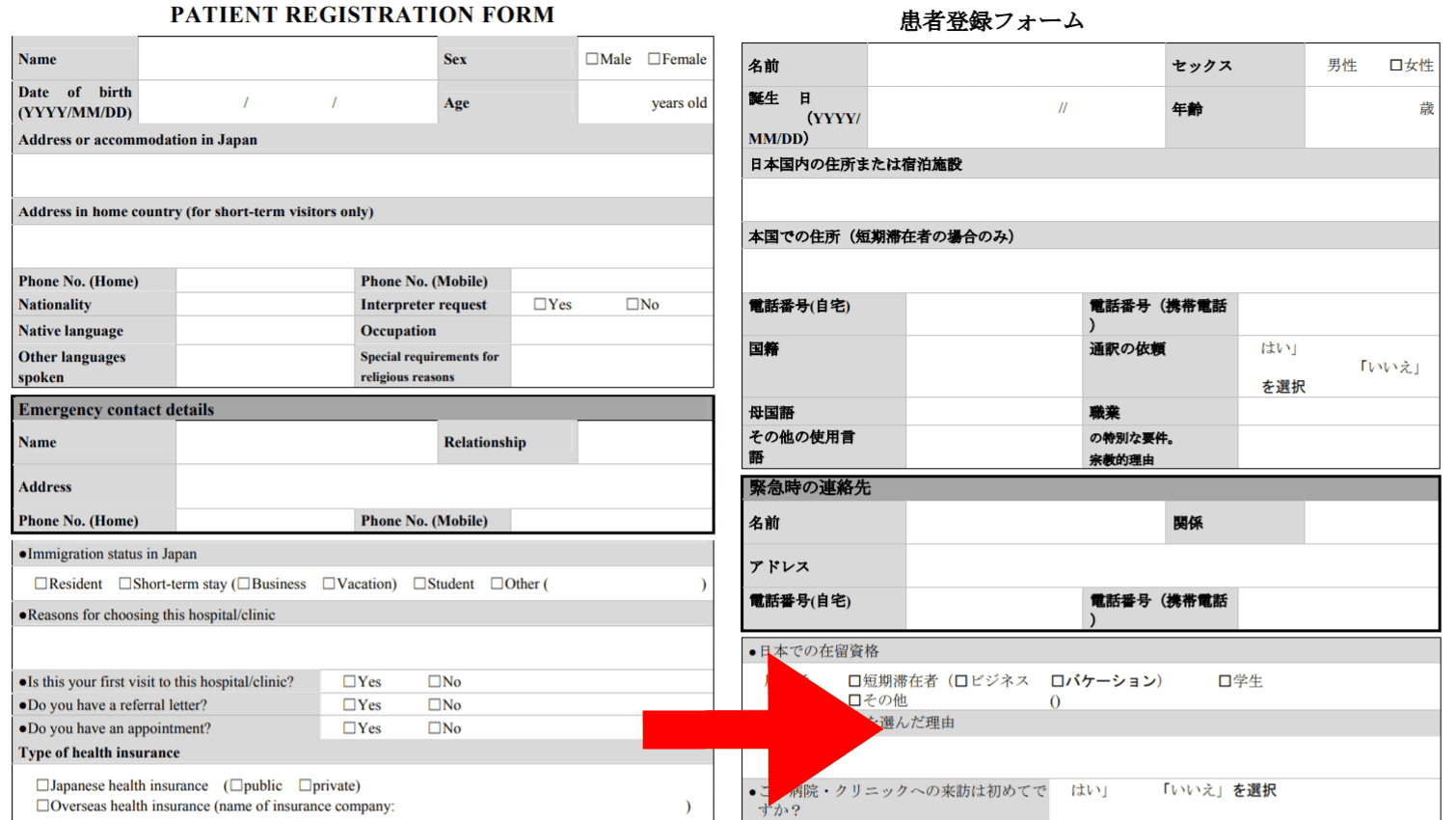
というわけで、実際にPDF翻訳を使ってみます。今回は厚生労働省の外国人向け多言語説明資料 一覧というページで公開されている「診療申込書(英語版)」を実際に翻訳します。
PATIENT REGISTRATION FORM
(PDFファイル)https://www.mhlw.go.jp/file/06-Seisakujouhou-10800000-Iseikyoku/0000056790.pdf

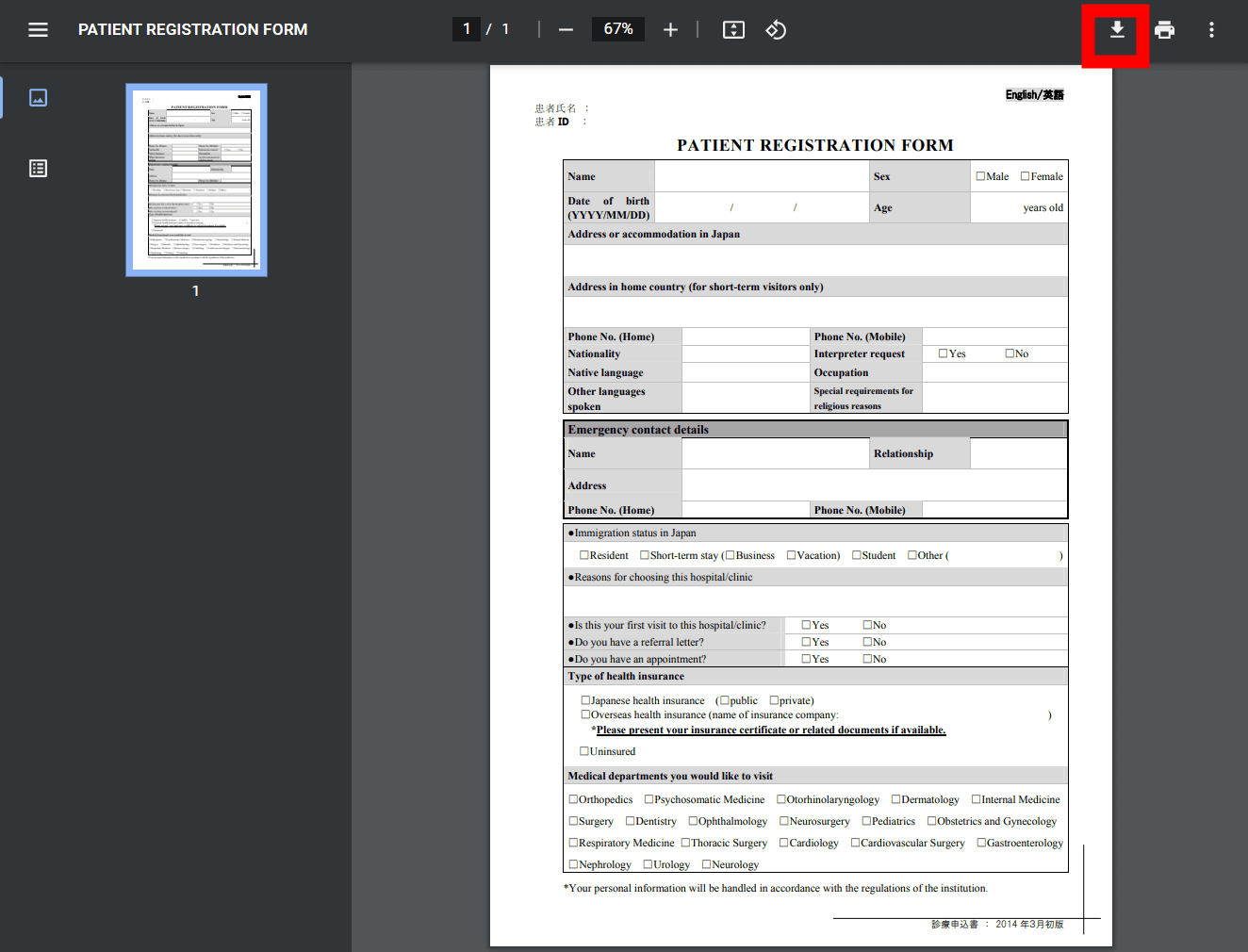
まずはローカルに翻訳したいPDFを取り込むため、ウィンドウ右上の「ダウンロード」をクリック。
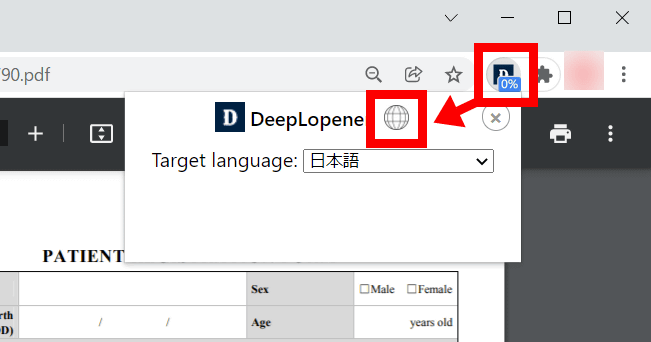
続いてツールバー上に表示されているDeepL Openerのアイコンをクリックして、表示されたポップアップから以下の赤枠部分をクリック。
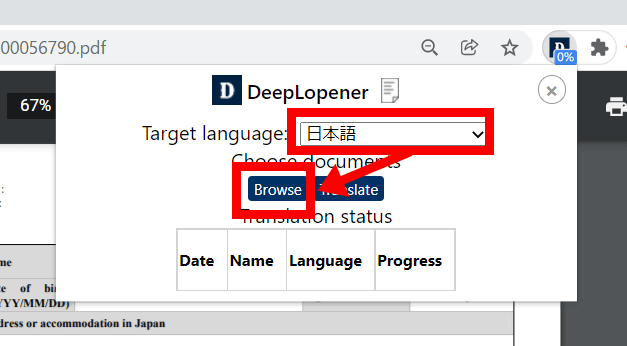
するとドキュメント翻訳モードに移行するので、「Target Language(翻訳後の言語)」を「日本語」に設定し、「Browse」をクリックします。
「開く」というポップアップが出てくるので、翻訳したいPDFファイルを選択して「開く」をクリック。
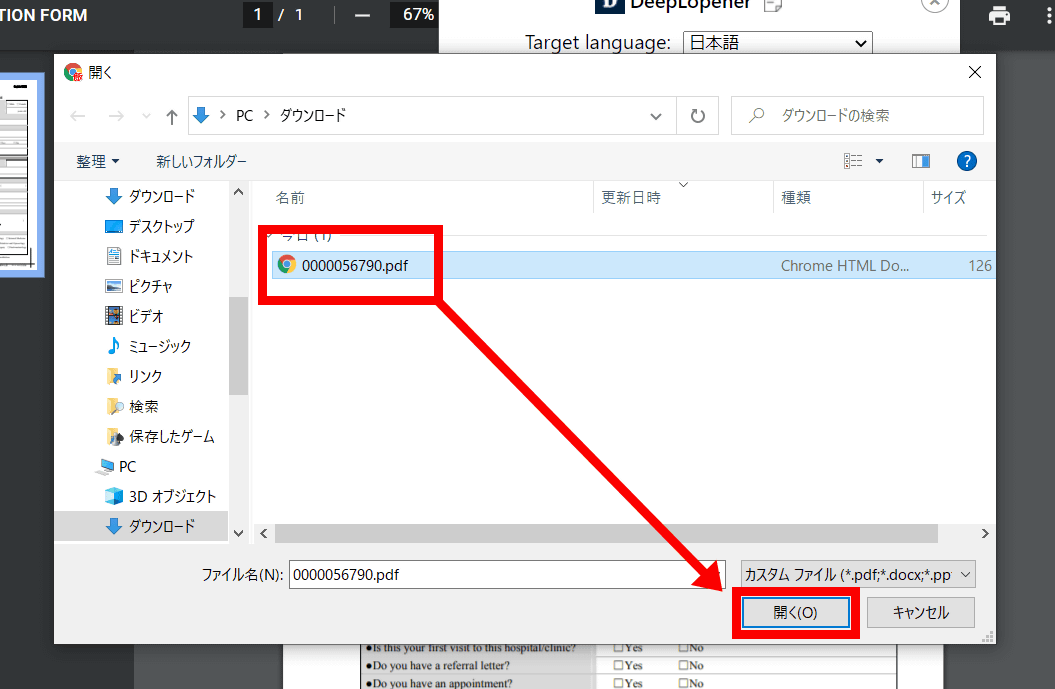
「Translate」をクリックすると……
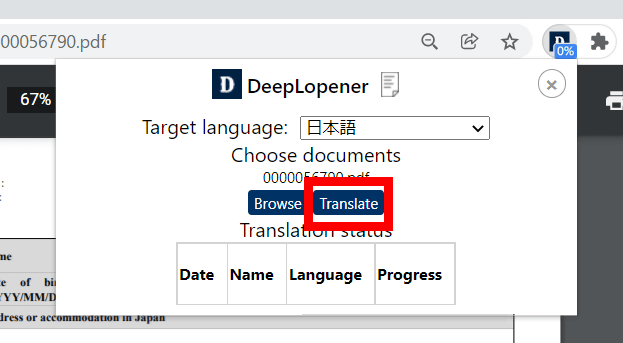
以下のようにAdobeへファイル送信して、自動で翻訳を行ってくれます。
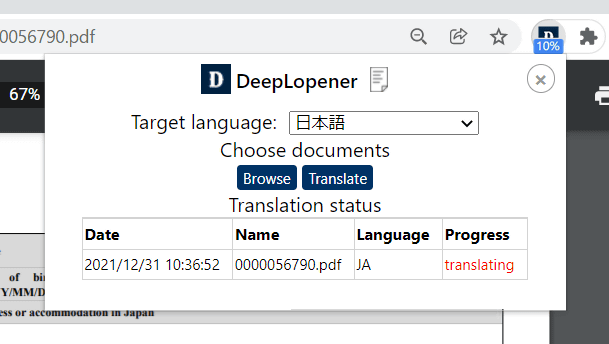
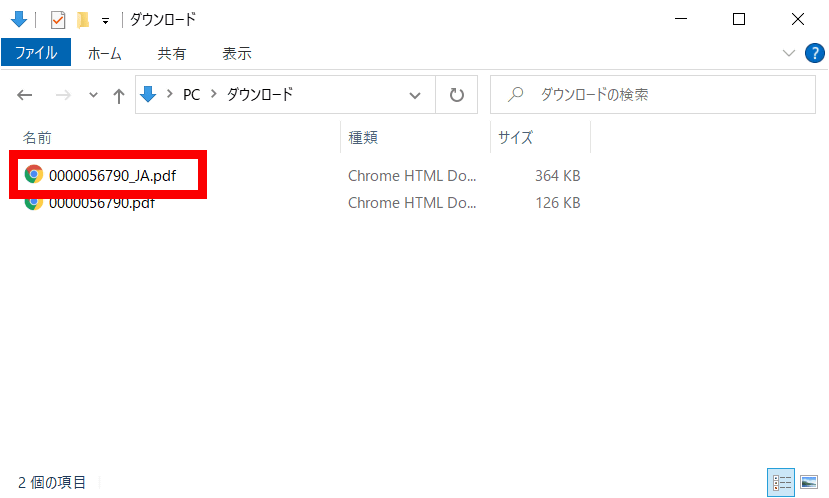
しばらく待つと「done」と表示されるので、この「done」をクリック。

すると、「(元のファイル名)_JA」というPDFファイルがダウンロードされます。このファイルを開くと……
以下のように翻訳されていました。枠やレイアウトなどは崩れていないものの、文章量の関係で2ページに分割されてしまった様子。

翻訳前(左)と翻訳後(右)を並べてみるとこんな感じ。
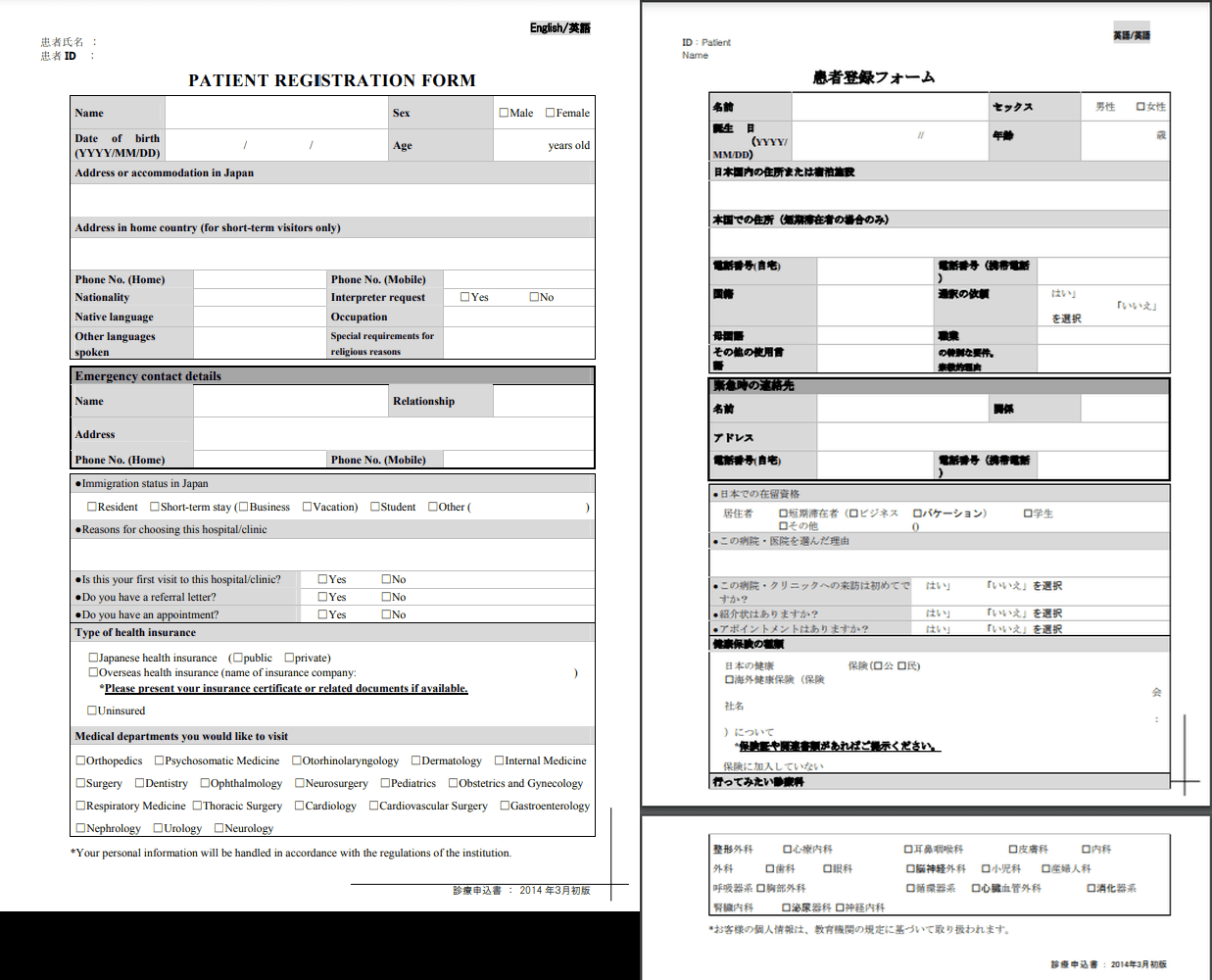
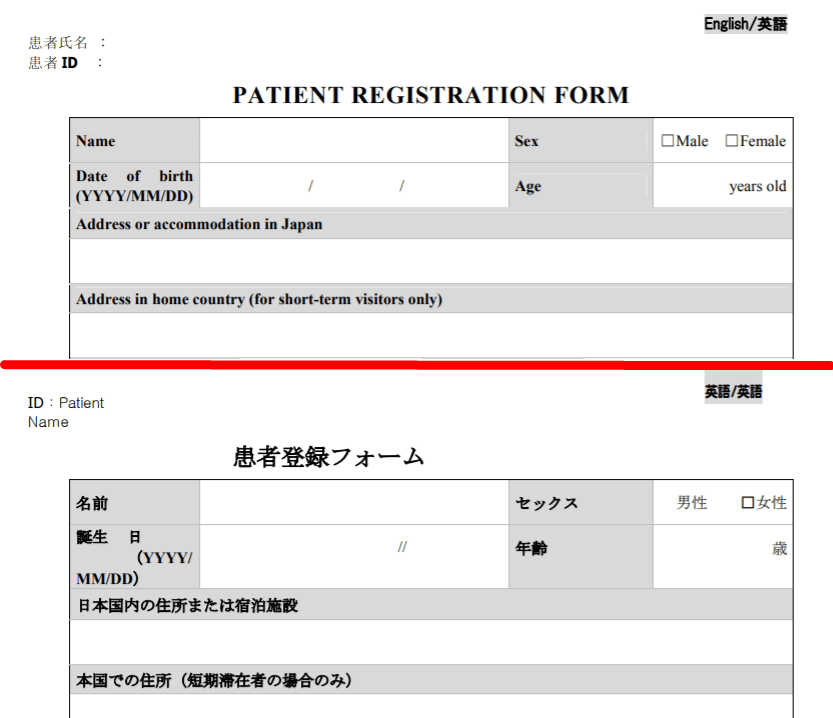
細かく見ると、英語から日本語に翻訳しているにもかかわらず、「患者氏名」「患者ID」は日本語から英語に翻訳されている様子。Sex(性別)をセックスに訳していたり、「誕生 日」のようにレイアウトが一部崩れていたりしているところもありますが、十分実用的と言えるレベル。
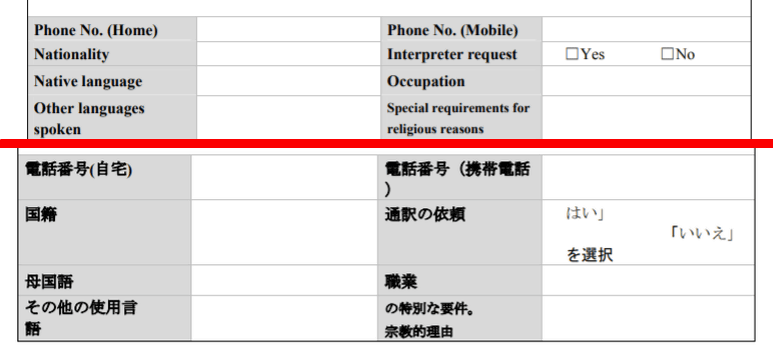
電話番号や職業などは「の特別な要件。宗教的な理由」と文章が前後逆になっている以外は問題ナシ。
在留資格や紹介状の有無などに関する質問はかなり上手に翻訳できています。
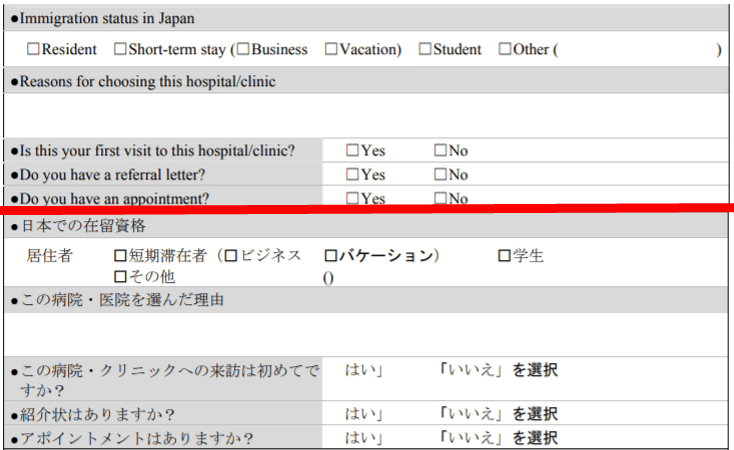
希望する診療科の選択肢に関してもちゃんと訳せています。ただし、末尾の注意書きである「*お客様の個人情報は、教育機関の規定に基づいて取り扱われます」というのは、「教育機関(the institution)」が「院内」の誤訳。

以上のように、DeepL openerはPDFファイルをレイアウトなど崩さずに丸ごと訳すときに便利な拡張機能。ただしクレジットカード情報を入力する必要があったり無料版APIでは1カ月あたり50万文字までという制限があったりといったハードルが存在するので、単に中身を日本語で読みたいだけならDeepLのソフトウェア版や公式Chrome拡張機能版で文章だけを翻訳したほうが良さそうです。
・関連記事
めちゃくちゃ精度が高いと話題の機械翻訳「DeepL翻訳」に日本語の翻訳機能が登場したので実際に使ってみた - GIGAZINE
画面上の文字列をOCRで読み取り翻訳できる翻訳支援ツール「PCOT」 - GIGAZINE
無料でウェブページの文章を翻訳してくれる&発音も教えてくれるアドオン「Mate Translate」を使ってみた - GIGAZINE
・関連コンテンツ

in ソフトウェア, レビュー, Posted by darkhorse_log
You can read the machine translated English article I tried using the third-party Chrome ext….