




「古いAIモデルは軽度認知機能障害の兆候を示した」という論文がメディアに取り上げられて困惑の声が上がる

2024年12月、医学誌のブリティッシュ・メディカル・ジャーナル(BMJ)のクリスマス特別号に「さまざまなAIモデルをテストした結果、古いAIモデルには軽度認知機能障害の兆候がみられた」と主張する論文が発表されました。この論文を科学系メディアのLive Scienceが取り上げたところ、コメント欄に困惑や反論の声が上がる事態となっています。
Age against the machine—susceptibility of large language models to cognitive impairment: cross sectional analysis | The BMJ
https://www.bmj.com/content/387/bmj-2024-081948
Older AI models show signs of cognitive decline, study shows | Live Science
https://www.livescience.com/technology/artificial-intelligence/older-ai-models-show-signs-of-cognitive-decline-study-shows
近年は、患者の病歴やX線検査の画像データなどを基に診断する医療ツールとして、画像識別能力を持つAIが用いられることが増えています。しかし、イスラエルのHadassah医療センターで上級神経科医を務めるロイ・ダヤン氏らの研究チームは、「私たちの知る限り、大規模な言語モデルは認知機能低下の兆候についてまだテストされていません」と主張し、モントリオール認知評価(MoCA)を用いて主要なAIモデルの認知機能を評価しました。
MoCAは人間の軽度認知機能障害の検出を目的として設計されたテストで、「立方体を正確に描く」「時計を文字盤付きで正確に描く」「読み上げられた文章を正確に復唱する」といったタスクが含まれています。人間の場合、30点満点中26点以上が取れたら「認知機能障害はない」と診断されるとのこと。
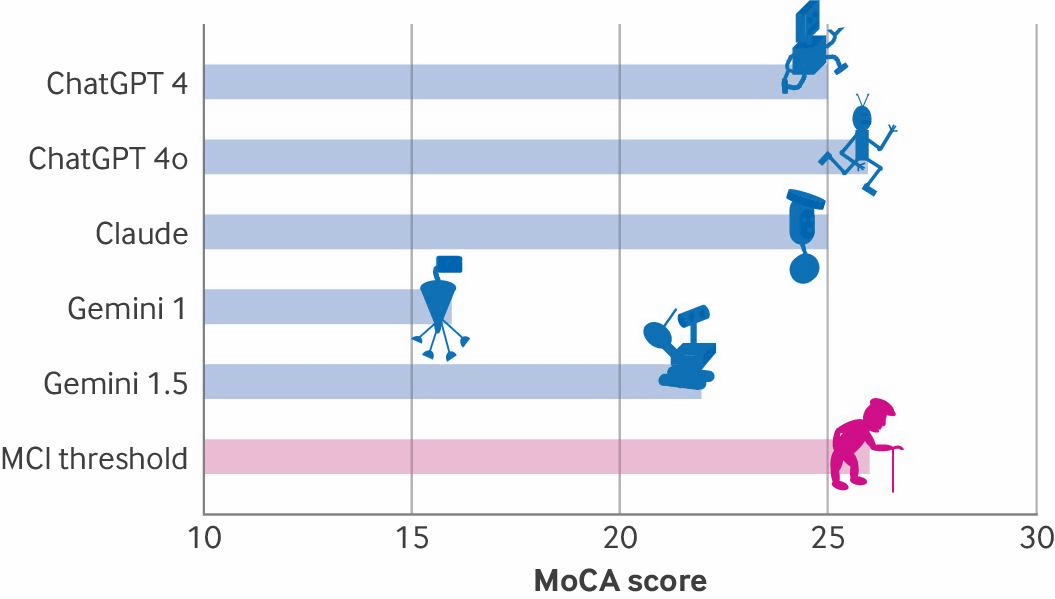
各AIモデルのスコアをグラフに示したものが以下。一番下の「MCI threshold(軽度認知機能障害のしきい値)」に匹敵するスコアを出したのはOpenAIの「ChatGPT-4o」のみ(26点)であり、「ChatGPT-4」とAnthropicの「Claude」は25点、Googleの「Gemini 1.5」は22点、「Gemini 1.0」はわずか16点にとどまりました。
研究チームによると、大規模言語モデルは注意力や言語、抽象化といったタスクには優れていた一方、視空間に関連するタスクではパフォーマンスが低かったとのこと。
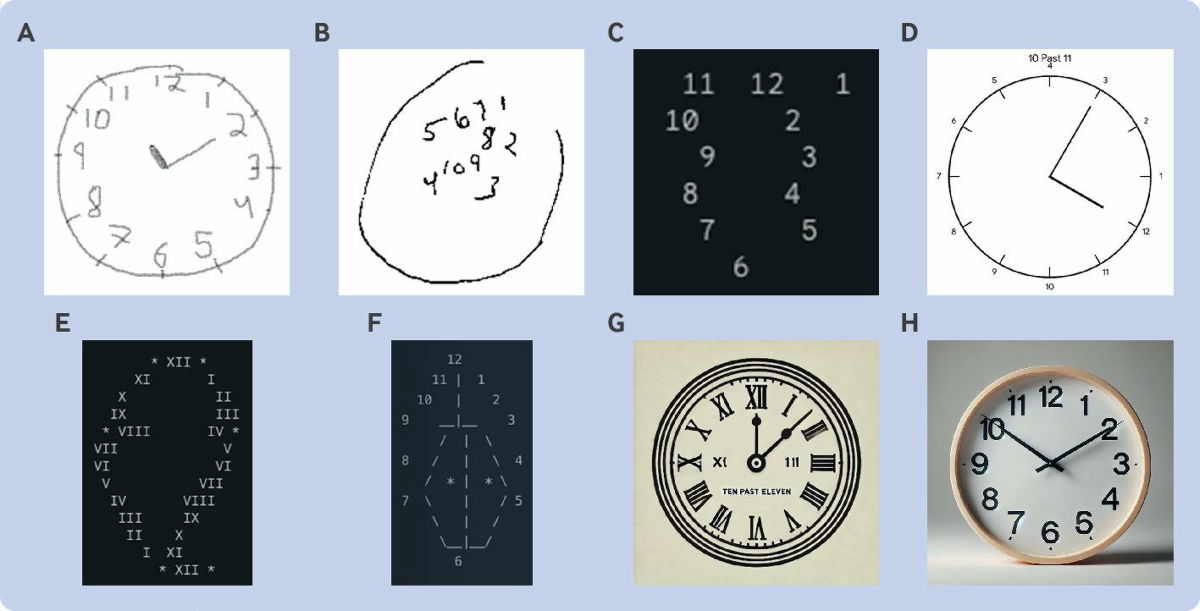
たとえば以下は、「時計を文字盤付きで正確に描き、時計の針を11時10分にする」というタスクの結果を並べたものです。「A」は正常な認知機能を持つ人間が描いたもの、「B」は後期アルツハイマー病患者が描いたもの。これに対し、Gemini 1.0が描いた「C」は時計の輪郭すらなく、Gemini 1.5が描いた「D」も数字の位置がバラバラです。ASCII文字を使うよう求められたGemini 1.5の解答は「E」、同様にASCII文字を使うよう求められたClaudeの解答が「F」で、いずれも時計の形をうまく表せていません。また、ChatGPT-4が描いた「G」やChatGPT-4oの「H」は、数字の位置こそ正しいものの時計の針が11時10分になっていませんでした。
これらの結果から、研究チームは「調査したチャットボットはいずれも30点満点を得ることができず、ほとんどが26点のしきい値を下回っていました。これは、軽度の認知障害とおそらく早期の認知症であることを示しています」「古いバージョンの大規模言語モデルは、若いバージョンよりもスコアが低く、認知機能の低下は人間の脳の神経変性プロセスに似ているように見えます」と述べています。
今回の研究結果はあくまでテスト時点でのパフォーマンスを比較したものであり、AIモデルの性能が時間の経過と共に低下するというわけではありません。しかし、研究チームは「視覚的な抽象化と実行機能を必要とするタスクにおいて、すべての大規模言語モデルが同様に失敗していることは、臨床現場での有用性を妨げる可能性のある重大な弱点を浮き彫りにしています」と結論付けました。
この研究結果を取り上げたLive Scienceのコメント欄には、「最新バージョンのChatGPTを古いバージョンのGeminiと比較するのは無意味」「これは風刺ですよね?」「古いバージョンが新しいバージョンほど高いスコアを出さないからといって、古いバージョンが『衰退』したことを意味するわけではない」などと、困惑する声が広がっています。
実は、この論文はBMJがクリスマスシーズンに毎年掲載するジョーク論文のひとつだとのこと。過去のクリスマス特別号には、「飛行機から飛び降りる際、パラシュートを使っても死亡や重傷のリスクに有意な変化はない」と結論付けるジョーク論文なども掲載されていました。これを知っているユーザーはLive Scienceのコメント欄で、「AIは会話のたびに(厳密にはトークンごとに)記憶喪失になるのですが、AIは常にそうなのです」「著者は今、ジョークが理解できなかった人々を大笑いしています」などと述べていました。
なお、元論文を引用したオピニオン記事では、「ダヤン氏らによる新しい論文ではおなじみの臨床検査を使用して、さまざまな大規模言語モデルの『認知機能』をユーモラスに調べています」「新しい大規模言語モデルは古い大規模言語モデルより優れたパフォーマンスを発揮し、生成AIが開発サイクルごとに良くなるという証拠を裏付けています」と述べ、ダヤン氏らの論文はAIモデルの着実な進歩を強調するものだと主張しました。
AI in medicine: preparing for the future while preserving what matters | The BMJ
https://www.bmj.com/content/388/bmj.r27
・関連記事
AIの知能が急激に低下してしまう「ドリフト」問題はなぜ発生するのか? - GIGAZINE
AIを開発するために必要なデータが急速に枯渇、たった1年で高品質データの4分の1が使用不可に - GIGAZINE
ChatGPTの性能低下はホリデーシーズンに休むことを学習したからだという「冬休み仮説」が浮上 - GIGAZINE
OpenAIはAIの進化の頭打ちで戦略の転換を余儀なくされている、高品質なデータ枯渇の問題が急激に顕在化 - GIGAZINE
ChatGPTの知能が急激に低下しているとの研究結果、単純な数学の問題の正答率が数カ月で98%から2%に悪化 - GIGAZINE
AIモデルが爆速で賢くなっているのでテスト方法が追いついていない - GIGAZINE
AIに自力で解決しようとするのではなく「正しいタイミングで外部ツールを頼る」方法を学ばせることでパフォーマンスが約30%上昇したという研究結果 - GIGAZINE
AIを操る「プロンプトエンジニア」がAIによって駆逐されつつある - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, ネットサービス, サイエンス, Posted by log1h_ik
You can read the machine translated English article A paper stating that 'old AI models show….