




OpenAIはAIの進化の頭打ちで戦略の転換を余儀なくされている、高品質なデータ枯渇の問題が急激に顕在化

2022年にリリースされて以来、日進月歩の進化でAIユーザーを驚かせてきたOpenAIのChatGPTですが、モデルのトレーニングに必要な高品質なデータの不足をはじめとするスケーリングの問題より、進歩が鈍化しつつあることが報じられました。
OpenAI Shifts Strategy as Rate of ‘GPT’ AI Improvements Slows — The Information
https://www.theinformation.com/articles/openai-shifts-strategy-as-rate-of-gpt-ai-improvements-slows
What if AI doesn’t just keep getting better forever? - Ars Technica
https://arstechnica.com/ai/2024/11/what-if-ai-doesnt-just-keep-getting-better-forever/
AIは高品質なデータでトレーニングすることで精度を向上させることができますが、トレーニングには大量のデータが必要になるため、特に高品質なデータは2026年にも枯渇すると予想されています。また、ウェブサイトがAI企業によるクローリングを禁止する動きを加速させたことにより、たった1年で高品質データの4分の1が使えなくなるなど、データ不足の問題は深刻化の一途をたどっています。
AIを開発するために必要なデータが急速に枯渇、たった1年で高品質データの4分の1が使用不可に - GIGAZINE

テクノロジー業界誌・The Informationに情報を提供したOpenAIの内部研究者によると、OpenAIの次期モデル、コードネーム「Orion」にはGPT-3からGPT-4にバージョンアップした際に見られたような大幅な性能の向上は見込めないとのこと。
そのため、Orionは「特定のタスクで確実に前モデルより優れているわけではありません」と、匿名の内部研究者は話しました。
この見方は以前からOpenAIの上層部の間に浸透していた可能性があります。2024年初頭にOpenAIを去った同社の共同設立者のイルヤ・サツキヴァー氏は、大量のデータを用いた基礎的トレーニングの手法「事前学習」のスケールアップによる成果が頭打ちになっていると、インタビューで述べています。
サツキヴァー氏はロイターの取材に「2010年代はスケーリングの時代でした。今、私たちは再び驚きと発見の時代に戻っており、誰もが次のものを求めているので、正しいものをスケーリングすることがこれまで以上に重要になっています」と話しました。

AIの進歩のボトルネックとしては、モデルを動作させるハードウェアや電力の制約などさまざまな要素がありますが、特に問題視されているのが新しくて品質の高いテキストデータの不足です。
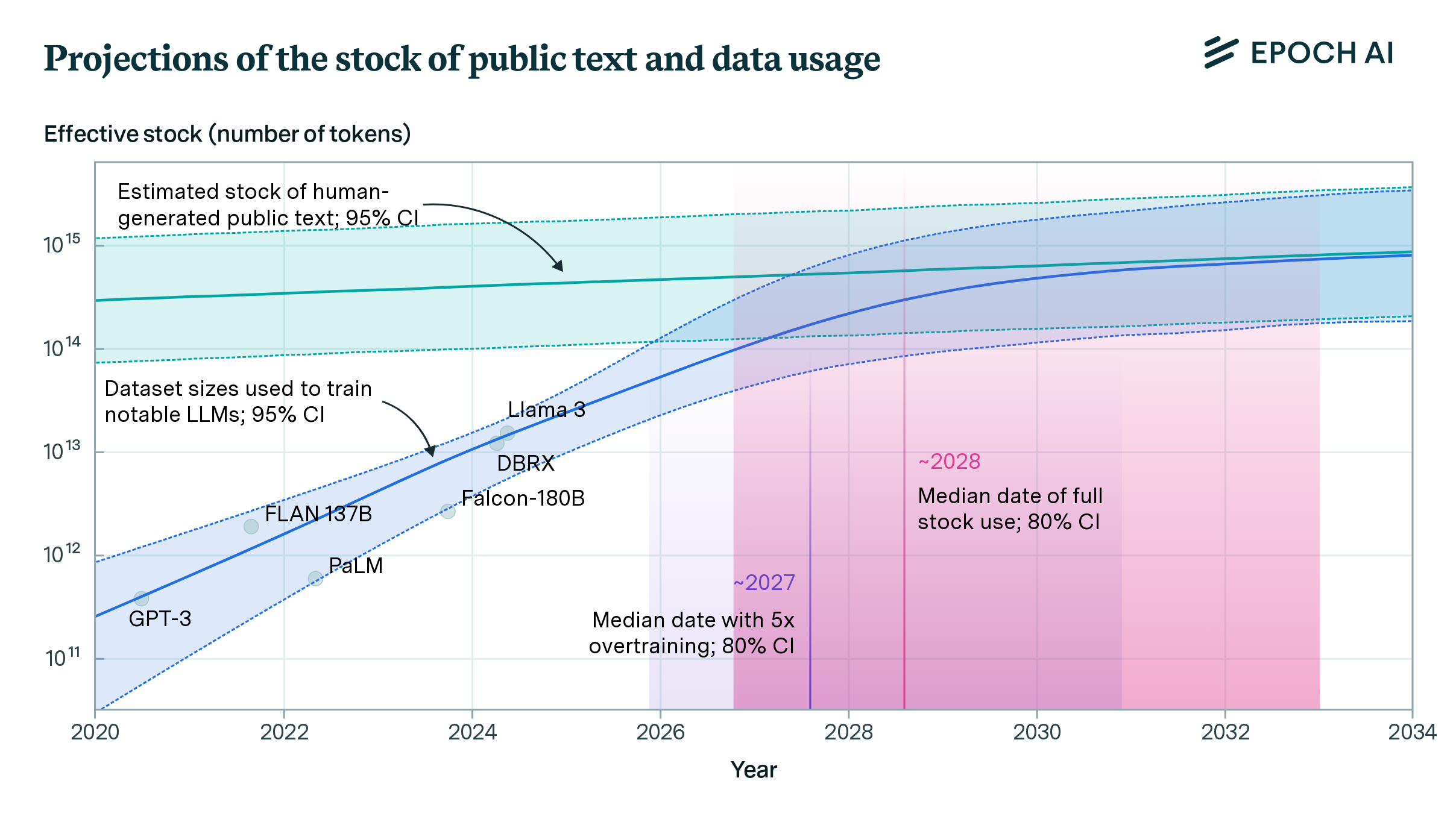
AI企業・Epoch AIの研究部門が発表した論文では、大規模言語モデル(LLM)のトレーニングデータセットの増加率を、人間が作成して公開したテキストの残量の推定量と比較して、この問題を定量化しました。
その結果から、研究者らは「言語モデルは2026年から2032年の間に人間が作成した公開テキストのストックのほとんどを使い果たす」と結論しました。
OpenAIをはじめとするAI企業は、目前に迫りつつあるデータ枯渇問題に対処すべく、他のモデルによって作成された「合成データ」をトレーニングに使用する手法に軸足を移し始めています。
しかし、この種のデータによる再帰的な学習を何サイクルも繰り返した結果、LLMが文脈を理解する能力が失われる「モデル崩壊」が起きかねないとの議論もあります。
また、新しいデータを使ったトレーニングではなく、推論能力の向上によるAIモデルの改善に望みを託している人もいますが、最新鋭の推論モデルでさえ意図的にミスリードを招くような設問があるとあっさりとだまされてしまうことが、研究で判明しています。
The Informationのレポートを取り上げたIT系ニュースサイトのArs Technicaは、「現行のLLMのトレーニング手法が袋小路に入った場合、次のブレークスルーは専門化によってもたらされるかもしれません。Microsoftは既に、特定のタスクや問題に特化したモデル、いわゆる小規模言語モデル(SLM)で一定の成果を収めています。つまり、これまでのジェネラリスト的なLLMとは異なり、近い将来のAIはより専門的で、より的を絞った分野に焦点を当てるようになるかもしれないということです」とコメントしました。
・関連記事
2026年までにAIのトレーニングに使うデータが枯渇する「データ不足問題」とは? - GIGAZINE
AIを開発するために必要なデータが急速に枯渇、たった1年で高品質データの4分の1が使用不可に - GIGAZINE
AIの需要増加によりデータセンターの消費電力が爆増してAI開発のボトルネックになっている - GIGAZINE
AIデータセンターのブームが電力需要に拍車をかける、電力網拡張のために値上げを検討する電力会社も - GIGAZINE
AIモデルのトレーニングで使えるアニメーション特化のデータセット「Sakuga-42M」が登場 - GIGAZINE
Slackがユーザーの明示的な許可なくメッセージなどをAIトレーニングに利用していることが判明 - GIGAZINE
MetaがAI強化のため「訴えられてもいいから著作権で保護された作品をかき集めよう」と議論していたとの報道 - GIGAZINE
・関連コンテンツ








in AI, サイエンス, Posted by darkhorse_log
You can read the machine translated English article OpenAI is forced to change its strategy ….