A paper stating that 'old AI models showed signs of mild cognitive impairment' has been picked up by the media, sparking confusion

In December 2024,
Age against the machine—susceptibility of large language models to cognitive impairment: cross sectional analysis | The BMJ
https://www.bmj.com/content/387/bmj-2024-081948
Older AI models show signs of cognitive decline, study shows | Live Science
https://www.livescience.com/technology/artificial-intelligence/older-ai-models-show-signs-of-cognitive-decline-study-shows
In recent years, AI with image recognition capabilities has been increasingly used as a medical tool to make diagnoses based on patient medical history, X-ray image data, etc. However, a research team led by Roy Dayan, a senior neurologist at Hadassah Medical Center in Israel, argued that 'to our knowledge, large-scale language models have not yet been tested for signs of cognitive decline,' and used the Montreal Cognitive Assessment (MoCA) to evaluate the cognitive function of major AI models.
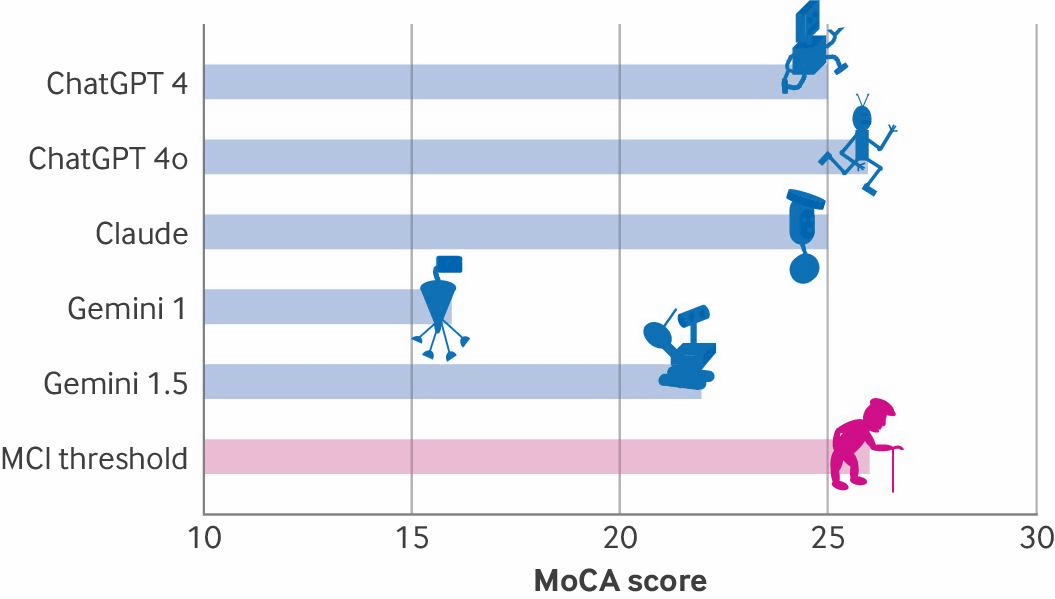
MoCA is a test designed to detect mild cognitive impairment in humans, and includes tasks such as 'accurately drawing a cube,' 'accurately drawing a clock with a dial,' and 'accurately repeating a sentence that is read aloud.' For humans, if they score 26 or more out of a possible 30 points, they are diagnosed as having no cognitive impairment.
The scores of each AI model are shown in the graph below. Only OpenAI's 'ChatGPT-4o' (26 points) achieved a score equivalent to the lowest 'MCI threshold (mild cognitive impairment threshold)', while 'ChatGPT-4' and Anthropic's 'Claude' achieved 25 points, Google's 'Gemini 1.5' achieved 22 points, and 'Gemini 1.0' achieved only 16 points.
According to the research team, large-scale language models excelled at tasks such as attention, language, and abstraction, but performed poorly on visuospatial tasks.
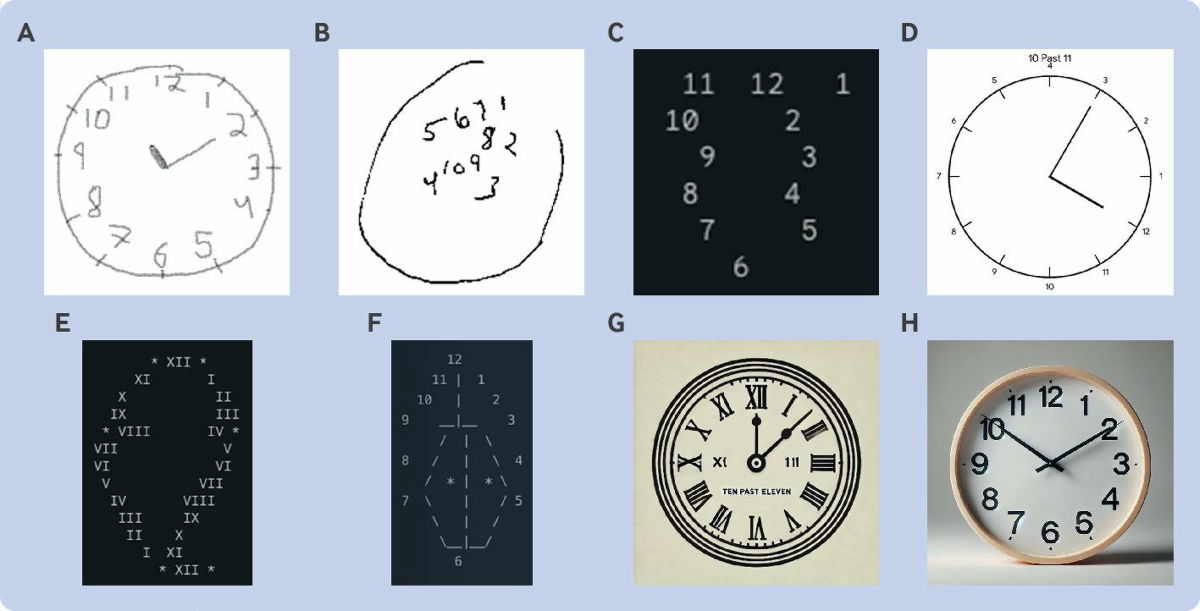
For example, the following are the results of the task of 'accurately drawing a clock with a dial and setting the hands of the clock to 11:10.' 'A' was drawn by a person with normal cognitive function, and 'B' was drawn by a patient with late-stage Alzheimer's disease. In contrast, 'C' drawn by Gemini 1.0 does not even have the outline of a clock, and 'D' drawn by Gemini 1.5 also has numbers in different positions. Gemini 1.5's answer, which was asked to use ASCII characters, was 'E,' and Claude's answer, which was also asked to use ASCII characters, was 'F,' neither of which were able to properly represent the shape of a clock. In addition, 'G' drawn by ChatGPT-4 and 'H' by ChatGPT-4o were in the correct position of the numbers, but the hands of the clock were not at 11:10.
Based on these results, the research team said, 'None of the chatbots we studied were able to achieve a perfect score of 30 points, and most were below the threshold of 26 points, indicating mild cognitive impairment and possibly early dementia. 'Older versions of the large-scale language model scored lower than younger versions, and the cognitive decline appears to resemble neurodegenerative processes in the human brain.'
Although the results of this study only compare performance at the time of testing, and do not necessarily mean that the performance of the AI models will deteriorate over time, the research team concluded that 'the similar failure of all large-scale language models in tasks that require visual abstraction and executive function highlights important weaknesses that may hinder their usefulness in clinical settings.'
In the comments section of Live Science, which covered the results of this research, there are many confused voices, such as 'It's pointless to compare the latest version of ChatGPT with an older version of Gemini,' 'This is satire, right?' and 'Just because older versions don't score as highly as newer versions doesn't mean that the older versions have 'declined.''
In fact, this paper is one of the joke papers that BMJ publishes every year during the Christmas season. Past Christmas special issues have also included a joke paper concluding that ' using a parachute when jumping from an airplane does not significantly change the risk of death or serious injury .' Users who knew this commented in the Live Science comment section, 'AI loses memory after every conversation (strictly speaking, after every token), but AI always does,' and 'The author is now laughing at people who didn't get the joke.'
In addition, an opinion piece citing the original paper stated, 'Dayan et al.'s new paper uses a familiar clinical test to humorously examine the 'cognitive functions' of various large-scale language models.' 'New large-scale language models outperform older ones, supporting the evidence that generative AI gets better with each development cycle,' and argued that Dayan et al.'s paper highlights the steady progress of AI models.
AI in medicine: preparing for the future while preserving what matters | The BMJ
https://www.bmj.com/content/388/bmj.r27
Related Posts:








in Software, Web Service, Science, Posted by log1h_ik