Study finds GPT-4 scores comparable to human specialists in eye exam

AI
Large language models approach expert-level clinical knowledge and reasoning in ophthalmology: A head-to-head cross-sectional study | PLOS Digital Health
https://journals.plos.org/digitalhealth/article?id=10.1371/journal.pdig.0000341
OpenAI's model all but matches doctors in assessing eye problems
https://www.ft.com/content/5b7a76be-467c-4074-8fd0-3e297bcd91d7
GPT-4 performed close to the level of expert doctors in eye assessments
https://www.engadget.com/gpt-4-performed-close-to-the-level-of-expert-doctors-in-eye-assessments-131517436.html?guccounter=1
In the study, published April 17, 2024 in the journal PLOS Digital Health, the researchers tested OpenAI's GPT-4 and GPT-3.5, Google's PaLM 2, and Meta's LLaMA on 87 multiple-choice questions.
The questions were taken from the study materials for the FRCOphth Part 2 exam, which is taken by ophthalmologists in private practice and trainees in ophthalmology specialist training programs, but since the study materials are not publicly available on the Internet, it is unlikely that the AI has studied them in advance. In addition, questions that include elements other than text, such as images, were excluded.
We then administered the same tests to five ophthalmologists, three ophthalmology trainees, and two junior doctors outside of ophthalmology, and compared the performance of the large-scale language model with the test results of the human doctors.
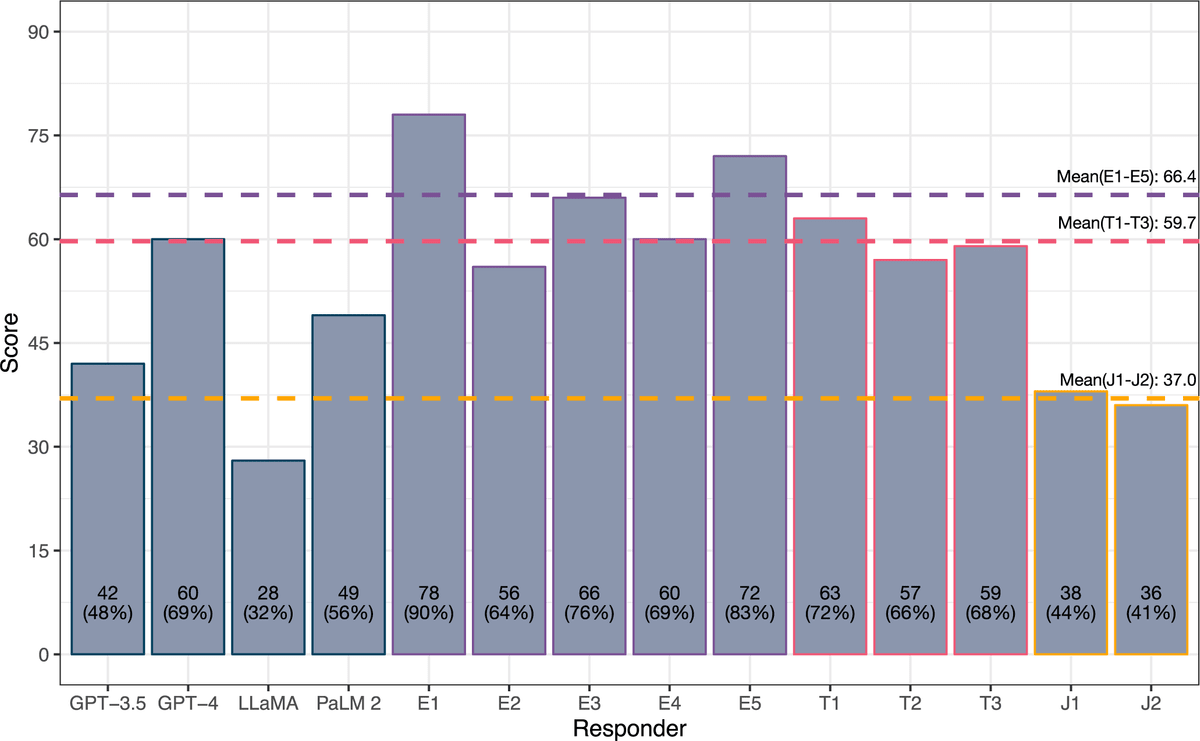
As a result, GPT-4 answered 60 out of 87 questions correctly, slightly higher than the average score of 59.7 points for trainees. It also did not reach the average score of 66.4 points for specialists, but it did beat the lowest score of 56 points among specialists. Other AIs also performed well, with PaLM 2 scoring 49 points and GPT-3.5 scoring 42 points, both of which were significantly higher than the average score of 37 points for junior doctors. The lowest score for AI was 28 points for LLaMa.
GPT-4 performed equally well on problems requiring first-order recall, i.e., tests of pure knowledge, as on problems requiring higher-order reasoning, such as interpolating, interpreting, and processing information.
The research team says it is notable that, unlike previous AI medical studies that test limited capabilities such as analyzing eye scans, this study directly compares the AI with the capabilities of practicing physicians.
'This study shows that the knowledge and reasoning ability of large-scale language models about eye health is now nearly indistinguishable from that of experts,' said lead author Arun James Thirunavukarasu from the University of Cambridge.

AI has been proven to be useful in diagnosis, such as flagging early-stage breast cancer that even veteran doctors may miss, and this has led to increased momentum in adopting AI in clinical practice. However, AI has a problem with hallucinations , which means it outputs false information, and researchers have cited the impact of misdiagnosis on patients and the risk of it being a challenge to determine.
Piers Keane, a medical artificial intelligence specialist at University College London and an ophthalmologist at a London hospital who was not involved in the research, told media: 'These latest findings are exciting and very intriguing.'
Keane, who is exploring the possibilities of medical AI, said that in his research published in 2023, when he asked a large-scale language model about macular degeneration , he was presented with fabricated references.
With these points in mind, Keene said, 'Further research will be needed before AI techniques can be implemented in clinical practice. We need to balance excitement about the potential benefits of this technology with caution and skepticism.'
Related Posts: