




NVIDIAが数兆パラメータ規模のAIモデルを実現するGPUアーキテクチャ「Blackwell」と新GPU「B200」を発表

NVIDIAが技術カンファレンス「GTC 2024」の中で、2年ぶりの新たなGPUアーキテクチャ「Blackwell」と、BlackwellアーキテクチャベースのGPU「B200」を発表しました。Blackwellにより、あらゆる組織がコストとエネルギー消費を25分の1に抑え、数兆パラメータの大規模言語モデル(LLM)によるリアルタイム生成AIを構築・実行可能になるとNVIDIAは述べています。
生成 AI のための Blackwell アーキテクチャ | NVIDIA
https://www.nvidia.com/ja-jp/data-center/technologies/blackwell-architecture/
Blackwellアーキテクチャは、2022年に発表されたHopperアーキテクチャの後継です。名前は、アメリカ科学アカデミーにアフリカ系アメリカ人として初めて殿堂入りした数学者・統計学者のデビッド・ハロルド・ブラックウェルから採られました。
NVIDIAが次世代GPUアーキテクチャ「Hopper」を発表、AI処理速度がAmpereの6倍など各種性能が飛躍的に向上 - GIGAZINE
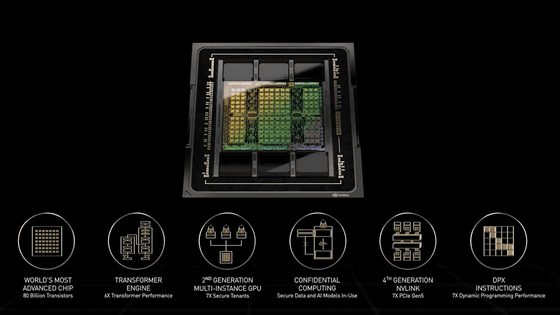
NVIDIAによれば、Blackwellには6つの革新的テクノロジーが搭載されているとのこと。
◆1:世界で最も強力なチップ
HopperアーキテクチャのGPU・H100はTSMCの4nmプロセスで製造されたトランジスタを800億個搭載していますが、Blackwell GPUは4nmプロセスの改良版で製造されたトランジスタを2080億個搭載。限界サイズのGPUダイ2つを毎秒10TBの高速インターフェース「NV-HBI」で接続することで、1つのGPUとして扱います。
◆2:第2世代Transformer Engine
LLM最適化のためのライブラリ「NVIDIA TensorRT-LLM」と「NeMo」フレームワークを組み合わせたダイナミックレンジ管理アルゴリズムと、新しいマイクロテンソルスケーリングのサポートにより、新たな4ビット浮動小数点AI推論機能でコンピューティングとモデルのサイズが2倍になります。
◆3:第5世代NVLink
高速GPUインターコネクト「NVLink」の最新バージョンにより、GPUあたり毎秒1.8TBの双方向スループットを実現し、巨大LLM向けに最大576基のGPU間でのシームレスな高速通信を保証しています。
◆4:RASエンジン
専用のRAS(信頼性・可用性・保守性)エンジンを備えるほか、チップレベルでAIベースの予防保守機能が追加することで回復力を高め、システムの稼働時間を最大化し、運用コストを削減します。
◆5:安全なAI
高度な「コンフィデンシャルコンピューティング」機能が、新たなネイティブインターフェイス暗号化プロトコルをサポートし、ハードウェアベースの強力なセキュリティにより、機密データやAIモデルを不正アクセスから保護します。コンフィデンシャルコンピューティングは、暗号化なしモードとほぼ同等のスループットパフォーマンスを発揮します。
◆6:解凍エンジン
専用の解凍エンジンがLZ4、Snappy、Deflateなど最新の圧縮形式をサポート。また、Grace CPUの大容量メモリに毎秒900GBの双方向帯域幅で高速アクセスできる機能により、データベースクエリ全体を高速化し、データ分析やデータサイエンスで最高のパフォーマンスを実現します。
このBlackwellアーキテクチャベースのGPUが「B200」です。
なお、この名前は正式発表以前の2024年2月、Dellのジェフ・クラーク副会長が「消費電力1000WのGPUをNVIDIAが開発中である」という文脈の中で出したことがあります。
NVIDIAが「消費電力1000Wの爆熱GPU」を開発中か - GIGAZINE

B200を用いたプラットフォームとしては、2基のB200と1基のGrace CPUを接続したスーパーチップ「GB200」、72基のB200と36基のGraceを組み合わせた接続した「GB200 NVL72」、B200を8基を接続した統合AIプラットフォーム「DGX B200」とサーバーボード「HGX B200」などの製品が示されています。また、GB200を36基組み合わせた「DGX GB200」システム、DGX GB200で構築された次世代AIスーパーコンピューター「DGX SuperPOD」なども発表されています。
NVIDIA GB200 NVL72 Delivers Trillion-Parameter LLM Training and Real-Time Inference | NVIDIA Technical Blog
https://developer.nvidia.com/blog/nvidia-gb200-nvl72-delivers-trillion-parameter-llm-training-and-real-time-inference/
NVIDIA Launches Blackwell-Powered DGX SuperPOD for Generative AI Supercomputing at Trillion-Parameter Scale | NVIDIA Newsroom
https://nvidianews.nvidia.com/news/nvidia-blackwell-dgx-generative-ai-supercomputing
統合AIプラットフォーム「DGX B200」は、空冷式ラックマウント型DGXプラットフォームの第6世代にあたります。8基のB200と2基のIntel Xeonプロセッサを搭載し、最大で144PFLOPSのAIパフォーマンスと1.4TBの大容量GPUメモリ、毎秒64TBのメモリ帯域幅により、1兆パラメータモデルのリアルタイム推論で、Hopperアーキテクチャと比べて15倍の高速化を実現しています。

「DGX SuperPOD」は、ジェンスン・フアンCEOが「AI産業革命の工場」と表現するスパコンで、「NVIDIAアクセラレーテッドコンピューティング、ネットワーキング、ソフトウェアの最新の進歩を組み合わせて、あらゆる企業、業界、国が独自のAIを改良し、生成できるようにします」とのこと。NVIDIA Quantum-2 InfiniBand アーキテクチャにより、GB200チップを数万個搭載することができます。

また、別途発表された「Quantum-X800 InfiniBand ネットワーキング」をサポートすることで、プラットフォーム内の各GPUに最大で毎秒1800GBの帯域幅を提供します。
さらに、第4世代のSHARP(Scalable Hierarchical Aggregation and Reduction Protocol)テクノロジーにより、前世代比で4倍となる14.4TFLOPSの性能を実現しているとのことです。
・関連記事
NVIDIAのAI特化GPUは一体どんなものなのか?ゲーム用GPUとは別物なのか? - GIGAZINE
ついにNVIDIAのグラボ「GeForce GTX」シリーズが終了へ - GIGAZINE
NVIDIAがCUDAを他のハードウェア上で実行することを禁止 - GIGAZINE
「NVIDIA H100 GPU」を2万4576基搭載して「Llama 3」などのトレーニングに活用されているGPUクラスターの情報をMetaが公開 - GIGAZINE
・関連コンテンツ







in AI, ハードウェア, Posted by logc_nt
You can read the machine translated English article NVIDIA announces Blackwell GPU architect….