




NVIDIAがAIおよびHPC向けGPU「H200」を発表、H100と比べて推論速度が2倍でHPC性能はx86 CPUの110倍

NVIDIAがAIおよびハイパフォーマンス・コンピューティング(HPC)向けのGPU「H200」を2023年11月13日(月)に発表しました。H200は前世代モデル「H100」と比べて推論速度が2倍、x86 CPUと比べてHPC性能が110倍になっていることがアピールされています。
H200 Tensor Core GPU | NVIDIA
https://www.nvidia.com/en-us/data-center/h200/
NVIDIA Supercharges Hopper, the World’s Leading AI Computing Platform | NVIDIA Newsroom
https://nvidianews.nvidia.com/news/nvidia-supercharges-hopper-the-worlds-leading-ai-computing-platform
H200はGPUアーキテクチャ「Hopper」を採用したGPUで、AI処理やHPC向けに最適化されています。同じくHopperを採用した前世代モデルのH100はAIの開発に必要な推論および学習において非常に高い性能を発揮し、需要過多によって製品不足に陥るほどの人気を集めました。
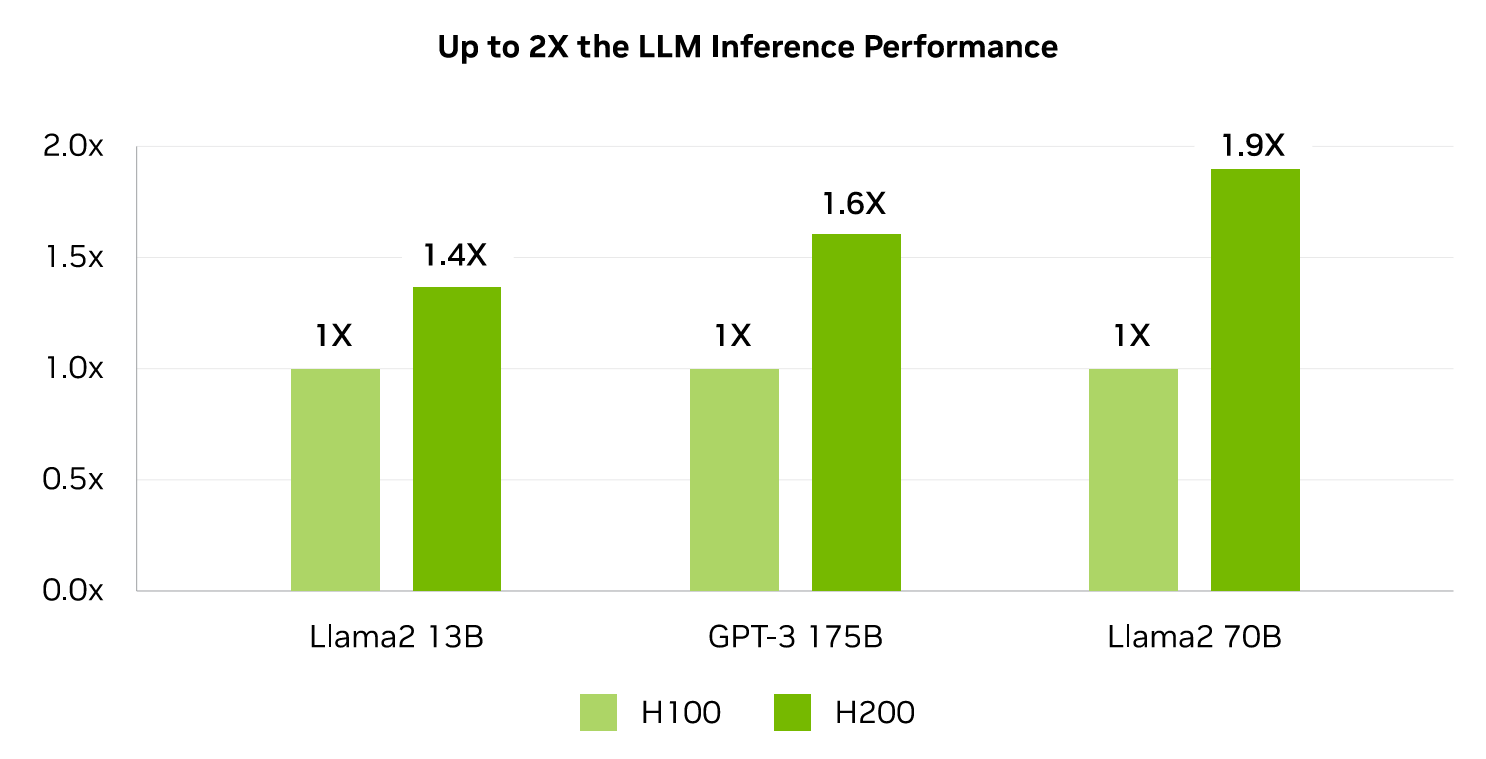
新たに発表されたH200には高速かつ大容量なメモリ技術「HBM3e」が採用されており、メモリ容量は141GB、メモリ帯域幅は4.8TB毎秒に達しています。H200は高性能なメモリを採用することでH100と比べて2倍の推論速度を実現しているとのこと。NVIDIAが示したH100(薄緑)とH200(緑)の推論速度比較グラフを確認すると、H200はH100と比較してLlama2 13Bで1.4倍、GPT-3 175Bで1.6倍、Llama2 70Bで1.9倍の推論速度を達成していることが分かります。
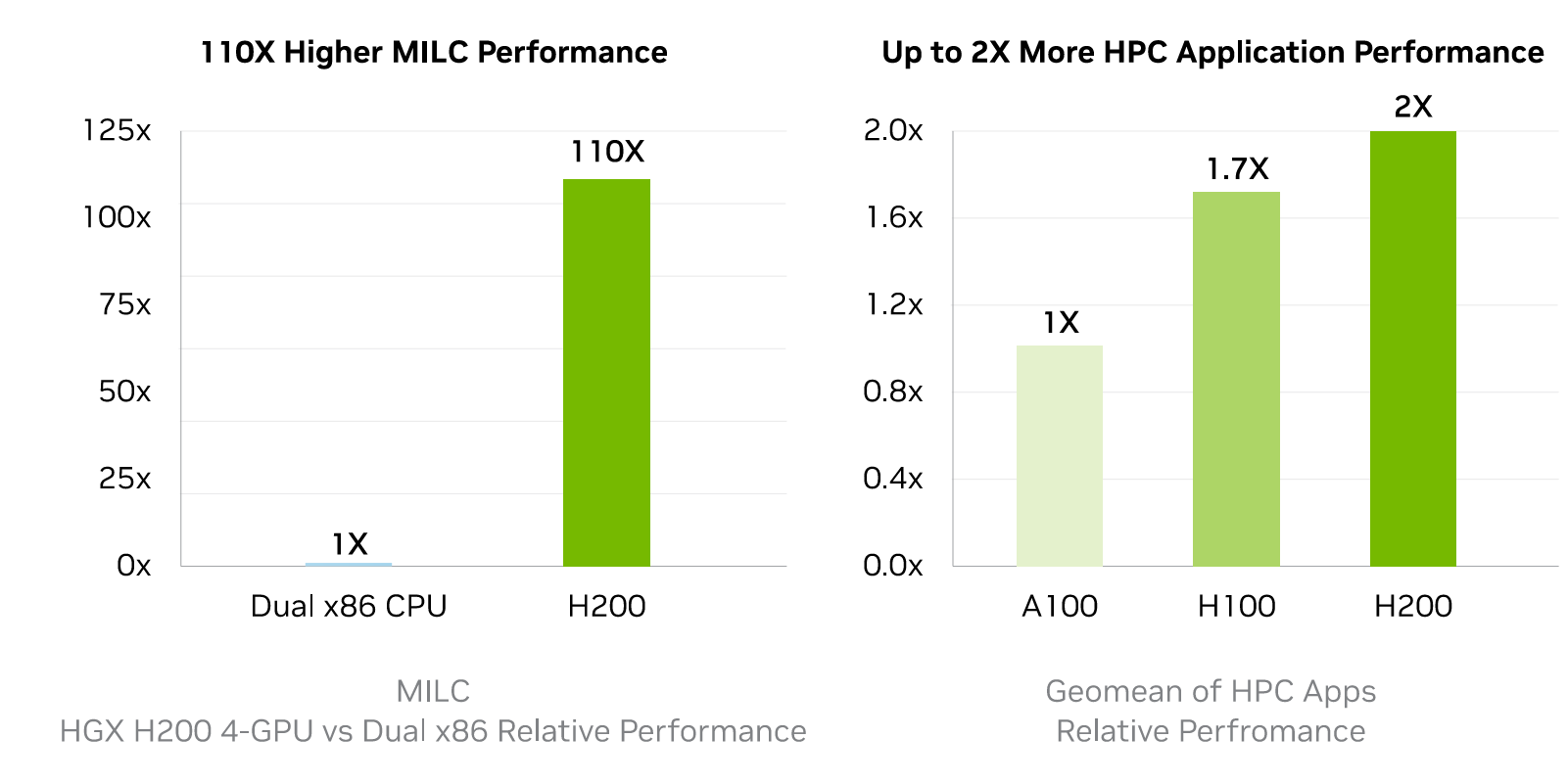
また、HPC性能はX86 CPUの110倍で、NVIDIA製GPU「A100」と比べても2倍高性能であることが示されています。
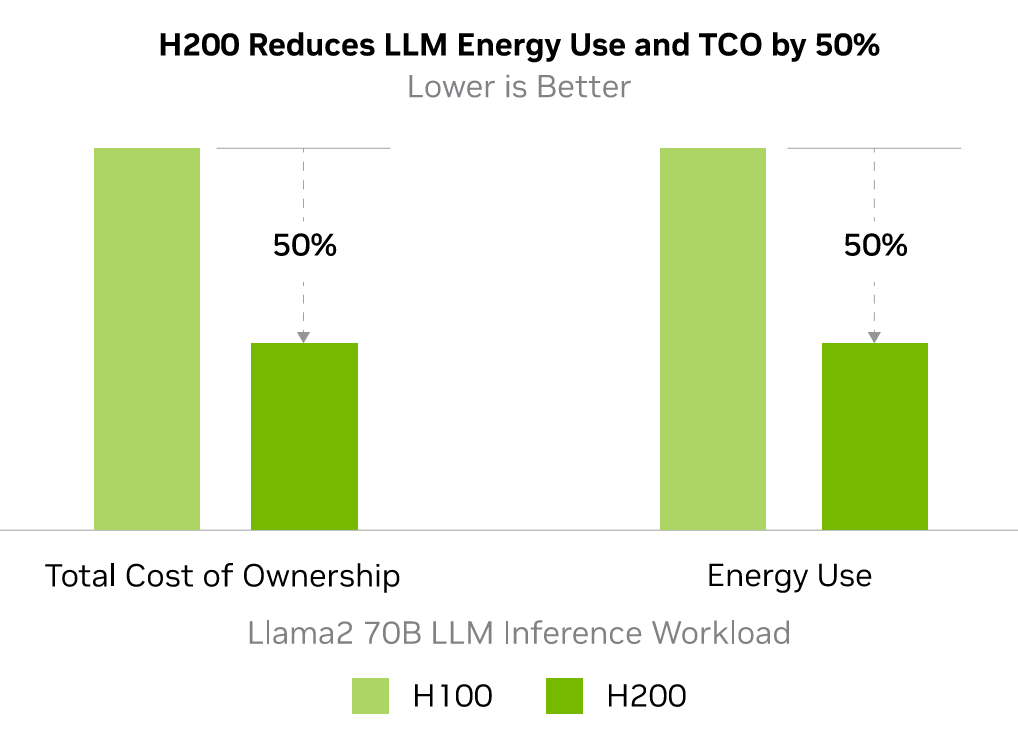
さらに、H200の運用費用や消費エネルギーはH100と比べて半減していることもアピールされています。
H200の詳細な仕様は以下の通り。
| フォームファクタ | H200 SXM |
|---|---|
| FP64 | 34 TFLOPS |
| FP64 Tensor Core | 67 TFLOPS |
| FP32 | 67 TFLOPS |
| TF32 Tensor Core | 989 TFLOPS |
| BFLOAT16 Tensor Core | 1979 TFLOPS |
| FP16 Tensor Core | 1979 TFLOPS |
| FP8 Tensor Core | 3958 TFLOPS |
| INT8 Tensor Core | 3958 TFLOPS |
| メモリ容量 | 141GB |
| メモリ帯域幅 | 4.8TB/s |
| デコーダー | 7 NVDEC 7 JPEG |
| 消費電力 | 最大700W |
| マルチインスタンス GPU(MIG) | Up to 7 MIGs @16.5GB each |
| フォームファクタ | SXM |
| 接続性 | NVIDIA NVLink: 900GB/s PCIe Gen5: 128GB/s |
なお、H200は4ウェイもしくは8ウェイ構成のNVIDIA HGX H200サーバーボードとして提供される予定で、AIおよびHPC特化型チップシステム「NVIDIA GH200 Grace Hopper Superchip」に組み込むことも可能とされています。
・関連記事
NVIDIAが次世代GPUアーキテクチャ「Hopper」を発表、AI処理速度がAmpereの6倍など各種性能が飛躍的に向上 - GIGAZINE
生成AIや大規模言語モデルの開発で渇望されるハイエンドGPU「NVIDIA H100」が不足する理由とは? - GIGAZINE
NVIDIAが処理能力1エクサFLOPS・メモリ144TBの生成AI向け大規模スパコン「DGX GH200」を発表 - GIGAZINE
「NVIDIA H100」を1000個以上積んだ高性能医学研究用コンピューティング・システムの構築をマーク・ザッカーバーグ夫妻が発表 - GIGAZINE
NVIDIAが次世代「Ampere」アーキテクチャのデータセンター向けGPU「NVIDIA A100」を発表 - GIGAZINE
・関連コンテンツ








in ハードウェア, Posted by log1o_hf
You can read the machine translated English article NVIDIA announces GPU 'H200' for AI and H….