




NVIDIAが処理能力1エクサFLOPS・メモリ144TBの生成AI向け大規模スパコン「DGX GH200」を発表

NVIDIAのジェンスン・フアンCEOが、2023年5月30日(火)から台湾の台北市で開催されているCOMPUTEX TAIPEI 2023で、生成AIのトレーニングや大規模言語モデルのワークロードなど、大規模なAIワークロードのためのスーパーコンピューター「DGX GH200」を発表しました。DGX GH200の処理性能は1エクサFLOPS(1000ペタFLOPS)に及び、GoogleやMicrosoftなどのクラウドコンピューティングで試験的に運用される予定となっています
DGX GH200 for Large Memory AI Supercomputer | NVIDIA
https://www.nvidia.com/en-us/data-center/dgx-gh200/
Announcing NVIDIA DGX GH200: The First 100 Terabyte GPU Memory System | NVIDIA Technical Blog
https://developer.nvidia.com/blog/announcing-nvidia-dgx-gh200-first-100-terabyte-gpu-memory-system/
Nvidia Unveils DGX GH200 Supercomputer, Grace Hopper Superchips in Production | Tom's Hardware
https://www.tomshardware.com/news/nvidia-unveils-dgx-gh200-supercomputer-and-mgx-systems-grace-hopper-superchips-in-production
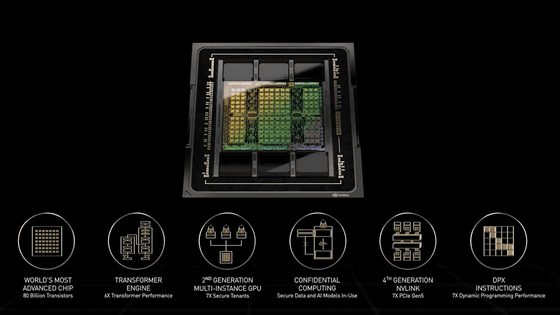
まず、フアンCEOはNVIDIA独自のArm CPU「Grace」とAI向けのGPU「Hopper」を組み合わせたAIおよびハイパフォーマンスコンピューティング(HPC)アプリ向けのチップセット「NVIDIA GH200 Grace Hopper Superchip」が生産体制に入ったことを発表しました。

このNVIDIA GH200 Grace Hopper Superchipは、GraceとHopperがNVIDIA NVLink-C2Cという技術で接続されており、PCI Express 5.0接続の約7倍に当たる900GB/sという帯域幅が実現されています。演算性能は4ペタFLOPSで、メモリとして96GBのHBM3と512GBのLPDDR5Xを搭載しています。

このNVIDIA GH200 Grace Hopper SuperchipとマルチGPU通信用のNVLink/NVSwitchを組み合わせ、最大256基のHopper GPUを統合して単一のGPUとして実行できるようにするプラットフォームが「DGX GH200」です。256基のNVIDIA GH200 Grace Hopper Superchipを統合することで、前世代のDGX A100の約500倍となる合計144TBの共有メモリをGPUメモリとして利用可能となり、さらに演算能力は1エクサFLOPSに及ぶとのこと。

NVIDIAのハイパースケール・HPC担当ヴァイスプレジデントであるイアン・バック氏は「ジェネレーティブAIや大規模言語モデルのような巨大モデルを使って演算処理を行う場合、すでにメモリ容量が限界に到達している状況です。AI研究者はテラバイトサイズ以上の巨大なメモリ容量を必要としており、DGX GH200は最大256基のHopper GPUを統合して単一のGPUとして実行できるようにすることで、そういったニーズに応えることが可能になります」と述べ、DGX GH200がジェネレーティブAIや大規模言語モデルのボトルネックを解消する大きな存在になるとアピールしました。
すでにGoogle Cloud、Meta、MicrosoftがジェレネーティブAIワークロードでの機能を把握するため、DGX GH200に早期アクセスできるようになるとのこと。

Google Cloudのコンピューティング担当ヴァイスプレジデントであるマーク・ローメヤー氏は「高度な生成モデルを構築するには、AIインフラストラクチャへの革新的なアプローチが必要です。NVLinkで統合されたNVIDIA GH200 Grace Hopper Superchipと大容量の共有メモリは、大規模なAIワークロードで起こり得る主要なボトルネックを解消するものであり、Google Cloudがその機能を調査できることを楽しみにしています」とコメントしています。
また、Metaのインフラストラクチャ、AIシステムおよびアクセラレーテッドプラットフォーム担当ヴァイスプレジデントであるアレクシス・ビョルリン氏は「NVIDIAのGrace Hopperの設計は、研究者が抱える最大の課題を解決するための新しいアプローチを探究できるようにすることを目的としています」述べたほか、MicrosoftのAzureインフラストラクチャ担当コーポレートヴァイスプレジデントであるギリッシュ・バブラニ氏は「DGX GH200がテラバイトサイズのデータセットを処理できるようになることで、開発者はより大規模で高速かつ高度な研究を行うことができます」とコメントしました。
さらにNVIDIAは、DGX GH200を4基組み合わせたスーパーコンピューター「NVIDIA Helios」を提案しています。NVIDIA Heliosでは、DGX GH200がそれぞれNVIDIA Quantum-2 InfiniBand プラットフォームで相互接続されています。つまり、合計で1024基のNVIDIA GH200 Grace Hopper Superchipを1つのユニットとして使えるようになることになります。このNVIDIA Heliosは2023年末までにオンラインになる予定だとのこと。
なお、フアンCEOがCOMPUTEX TAIPEI 2023で行った基調講演については、以下から全編を見ることができます。
NVIDIA Keynote at COMPUTEX 2023 - YouTube

・関連記事
NVIDIAが生成AIでゲームのNPCと会話できる「NVIDIA Avatar Cloud Engine(ACE)」のデモムービーを公開 - GIGAZINE
世界最速のスパコントップ500でAMDが大躍進中、1位はフロンティアが守り富岳は2位 - GIGAZINE
GoogleがNVIDIA H100 GPU搭載のAI特化型スパコン「A3」を発表 - GIGAZINE
GoogleのAI用プロセッサ「TPU v4」はNVIDIAの「A100」より高速で効率的だとGoogleの研究者が主張 - GIGAZINE
NVIDIAがブラウザからAIスーパーコンピューターにアクセスできる「DGX Cloud」を発表 - GIGAZINE
・関連コンテンツ







in ハードウェア, Posted by log1i_yk
You can read the machine translated English article NVIDIA announces large-scale supercomput….