




UUIDなのにデータベースのプライマリキーに設定してもパフォーマンスの問題を起こさない「UUIDv7」の標準化作業が進行中
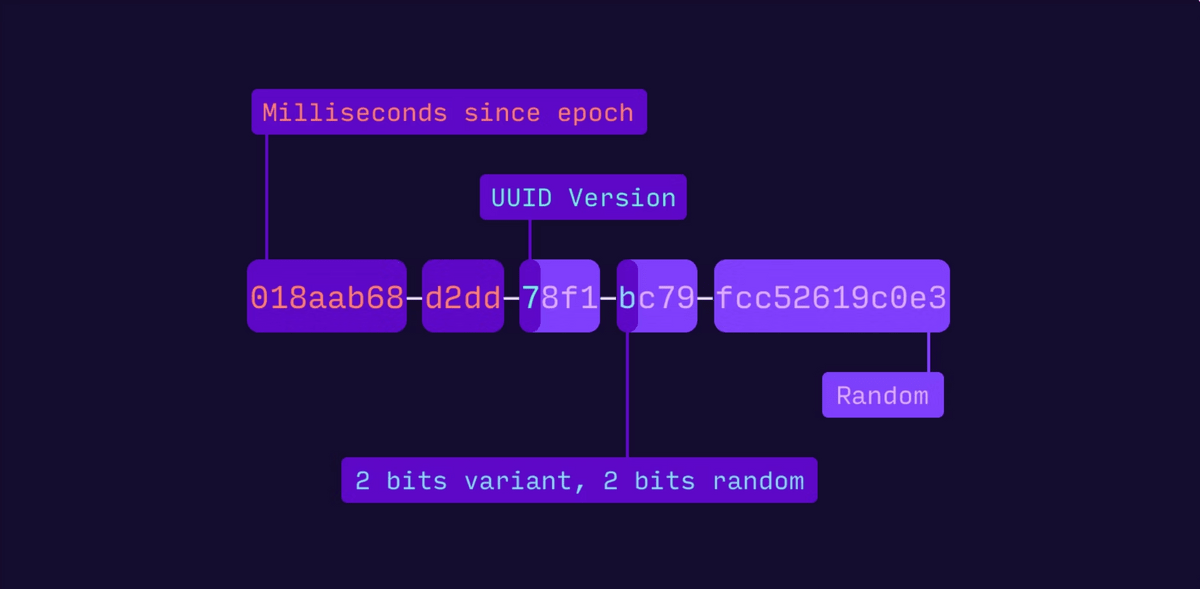
UUIDは「Universally Unique Identifier」の略称で、世界中のどこにも重複が存在しない唯一のIDという特徴があります。UUIDには歴史的な経緯によっていくつかのバージョンが存在していますが、2023年10月時点で標準化の作業が進行中のv7についてCI/CDサービスを提供する企業のBuildkiteが解説しています。
Goodbye to sequential integers, hello UUIDv7!
https://buildkite.com/blog/goodbye-integers-hello-uuids
UUIDは128ビットの数字で、大部分をランダムに作成することで重複する確率を限りなくゼロに近づけており、実質的に世界中のどこにも存在しない唯一のIDとみなせるようになっています。しかし、完全に数値がランダムのためプライマリキーとして使用するとデータベースでパフォーマンスの問題が発生してしまい、UUIDとは別にデータベース用の連番キーを持つなどの工夫が必要となっていました。
例えばBuildkite製品の場合、古いデータよりも最近のデータの方がより頻繁にアクセスされるという性質があります。プライマリキーをUUIDにすると新しいデータがインデックス内にランダムに分散されるため、大規模なデータセットから最新のデータを取得したい場合に多数のデータベースインデックスページを走査しなくてはならず、キャッシュヒット率が低下してしまいます。一方で、プライマリキーを連番で作成すると単純に最新のデータがインデックスの右端に配置され、キャッシュしやすい構造になるというメリットがあります。
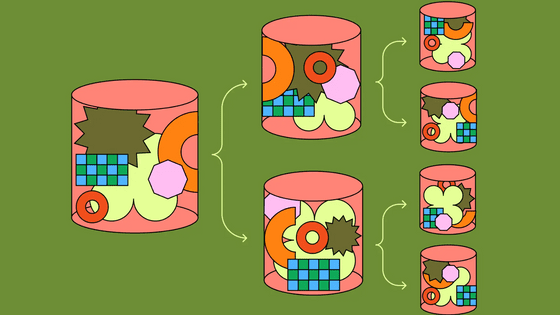
こうしたデメリットを軽減するための方法は10年以上にわたって模索されており、代表的な解決策としてはX(旧Twitter)のSnowflake IDやInstagramのShardingIDなど、乱数列の前にタイムスタンプを付けるという方法が挙げられます。

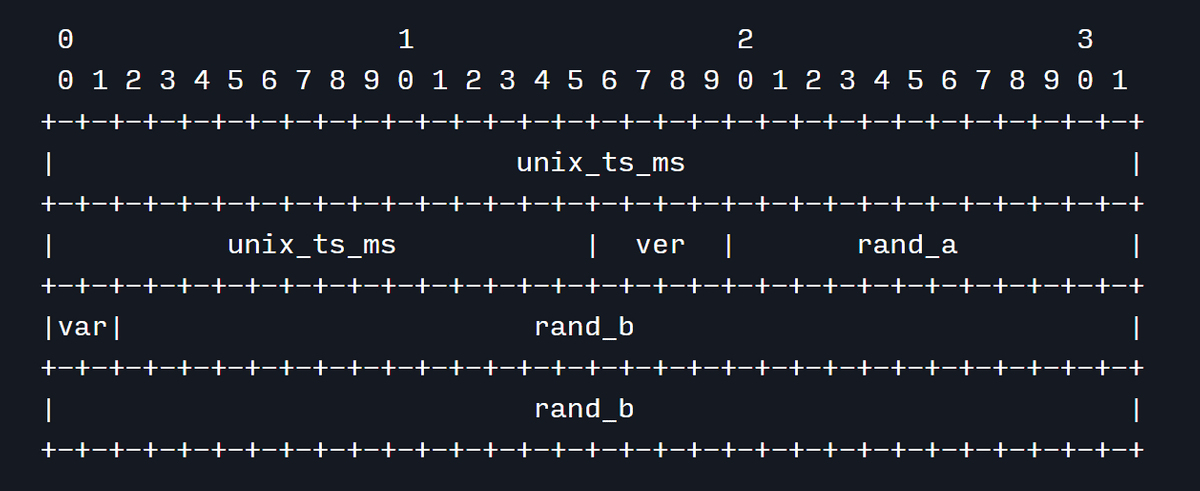
2022年になってこうしたタイムスタンプを活用するUUIDの新しい標準案が注目を集め始め、UUIDv7として標準化の作業が進行し始めました。UUIDv7の構造は下図の通りで、最初の48ビットがミリ秒単位のUnixタイムスタンプとなっており、その後UUIDのバージョンとバリアントを示すために6ビットが使用され、それ以外の74ビットが乱数となっています。
UUIDv7をプライマリキーとして使用することで、データベース用の連番キーの生成や管理が不要になり、アプリケーションのロジックを簡素化することが可能です。さらに、UUIDv7は標準UUIDの形式に準拠しているため、従来のUUID向けのコードやライブラリをそのまま活用でき、簡単にバージョンを移行できるとのこと。
Snowflakeなどの代替案の多くは64ビットのため、128ビットのUUIDを使用することでストレージの容量を多く使用することになるものの、データベースの1行あたりのストレージ使用量から考えると無視できるレベルの問題です。こうしたメリットを考えて、BuildkiteではUUIDv7の採用を決めたと述べられていました。
・関連記事
世界でたったひとつの識別子として活用される「UUID」はどのように生成されているのか - GIGAZINE
コンピューターはどうやって乱数を生み出しているのか? - GIGAZINE
データベース用語の「シャーディング」はMMORPGの「ウルティマオンライン」が由来かもしれない - GIGAZINE
オープンソースのリレーショナルデータベース「PostgreSQL」が信頼を獲得して広く利用されるようになるまでの歴史をエキスパートエンジニアが解説 - GIGAZINE
データベースの文字数制限が191文字になっている理由とは? - GIGAZINE
・関連コンテンツ




in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article Work is underway to standardize ``UUIDv7….