




画像生成AI「Stable Diffusion」に「悪い例を集めたLoRA」を組み合わせて高品質な画像を生成する手法が登場、簡単に試せるデモも公開されたので試してみた
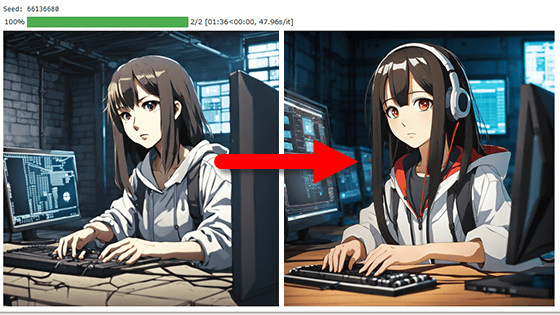
2023年7月に公開された「Stable Diffusion XL 1.0(SDXL 1.0)」は既存のStability AI製モデルと比べて高品質な画像を生成できるだけでなく、LoRAによる生成画像の調整にも対応しています。データサイエンティストのマックス・ウルフ氏は「悪い例」を集めて作成したLoRAを用いてSDXL 1.0による生成画像の品質をさらに向上させる手法を考案し、LoRAファイルおよび誰でも試せるデモを公開しています。
I Made Stable Diffusion XL Smarter by Finetuning it on Bad AI-Generated Images | Max Woolf's Blog
https://minimaxir.com/2023/08/stable-diffusion-xl-wrong/
LoRAは参考となる画像を集めて絵柄や服装などを追加学習することで、好みの絵柄や服装を含む画像を生成しやすくする仕組みです。例えば、「歯が生えた実写版ソニック」の画像で学習したLoRAファイルをSDXL 1.0に適用することで以下のように「歯が生えた実写版ソニック」の画像を大量生成できます。

Stable Diffusionにはプロンプトに「トリガーワード」を含ませることでLoRAの絵柄を呼び出せる仕組みが備わっています。ウルフ氏はAIによる画像生成で頻発する「人体が破綻する」「謎の透かしが入る」「おかしな位置で切り抜かれる」といった問題を解決する方法として、「画像生成AIでありがちなミスを学習したLoRAを作成し、作成したLoRAのトリガーワードをネガティブプロンプトに指定して画像を生成する」という手法を編み出しました。
ウルフ氏はまず、SDXL 1.0を用いて「low quality(低品質)」「error(エラー)」「missing or extra fingers(誤った、もしくは多すぎる指)」「cropped(切り抜かれた)」「watermark(透かし)」「ugly(醜い)」といったワードを含むプロンプトを用いて、以下のような破綻した画像を大量に生成。さらに、生成した画像を学習データに指定し、トリガーワードを「wrong」に設定したLoRAファイル「sdxl-wrong-lora」を作成しました。

以下の3枚の画像はすべて同じプロンプト「A wolf in Yosemite National Park, chilly nature documentary film photography」を入力しつつ、左側は「sdxl-wrong-loraを使わず、ネガティブプロンプトも指定しない」、中央は「sdxl-wrong-loraを使わず、ネガティブプロンプトに『wrong』と入力」、右側は「sdxl-wrong-loraを使い、ネガティブプロンプトに『wrong』と入力」という条件で生成された画像です。sdxl-wrong-loraを使わずにネガティブプロンプトに「wrong」と入力しただけでも背景の描き込みが細かくなっていますが、sdxl-wrong-loraを使うと背景の描き込みがさらに細かくなり、中央に描かれたオオカミの毛並みもモフモフ度が増しています。

ウルフ氏は、sdxl-wrong-loraによる生成画像の品質向上効果を検証できるデモも用意しています。デモを試すには、Googleアカウントにログインした状態で以下のリンク先にアクセスします。
sdxl_wrong_comparison.ipynb - Colaboratory
https://colab.research.google.com/github/minimaxir/sdxl-experiments/blob/main/sdxl_wrong_comparison.ipynb
デモの実行方法は簡単で、スクリプトの左側に表示されている再生ボタンを左上から順にクリックするだけです。
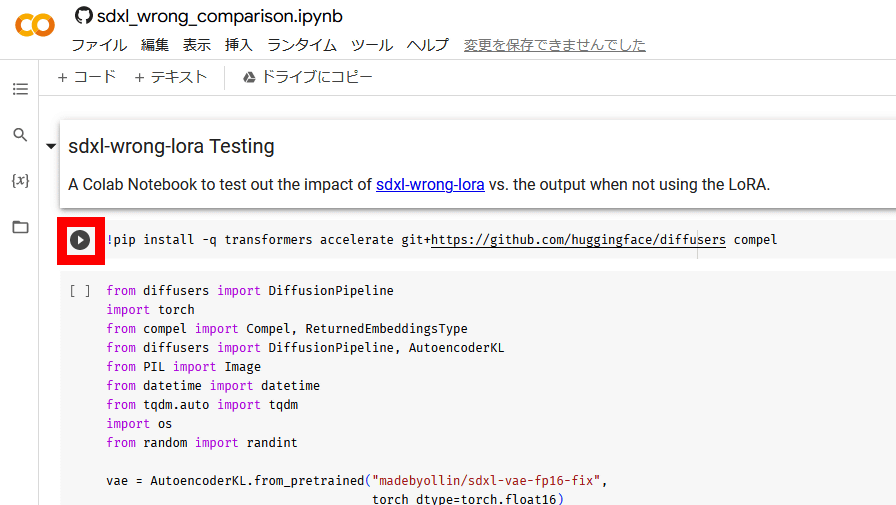
最後まで処理に成功すると、以下のようにマリオの画像が2枚生成されます。左側の画像は「sdxl-wrong-loraを使わず、ネガティブプロンプトも指定しない」、右側の画像は「sdxl-wrong-loraを使い、ネガティブプロンプトに『wrong』と入力」という条件で生成されており、他の条件は同一です。画像を見比べると、sdxl-wrong-loraを使った右側の画像ではマリオの眉毛や手袋が左側の画像と比べて正確に描写されています。
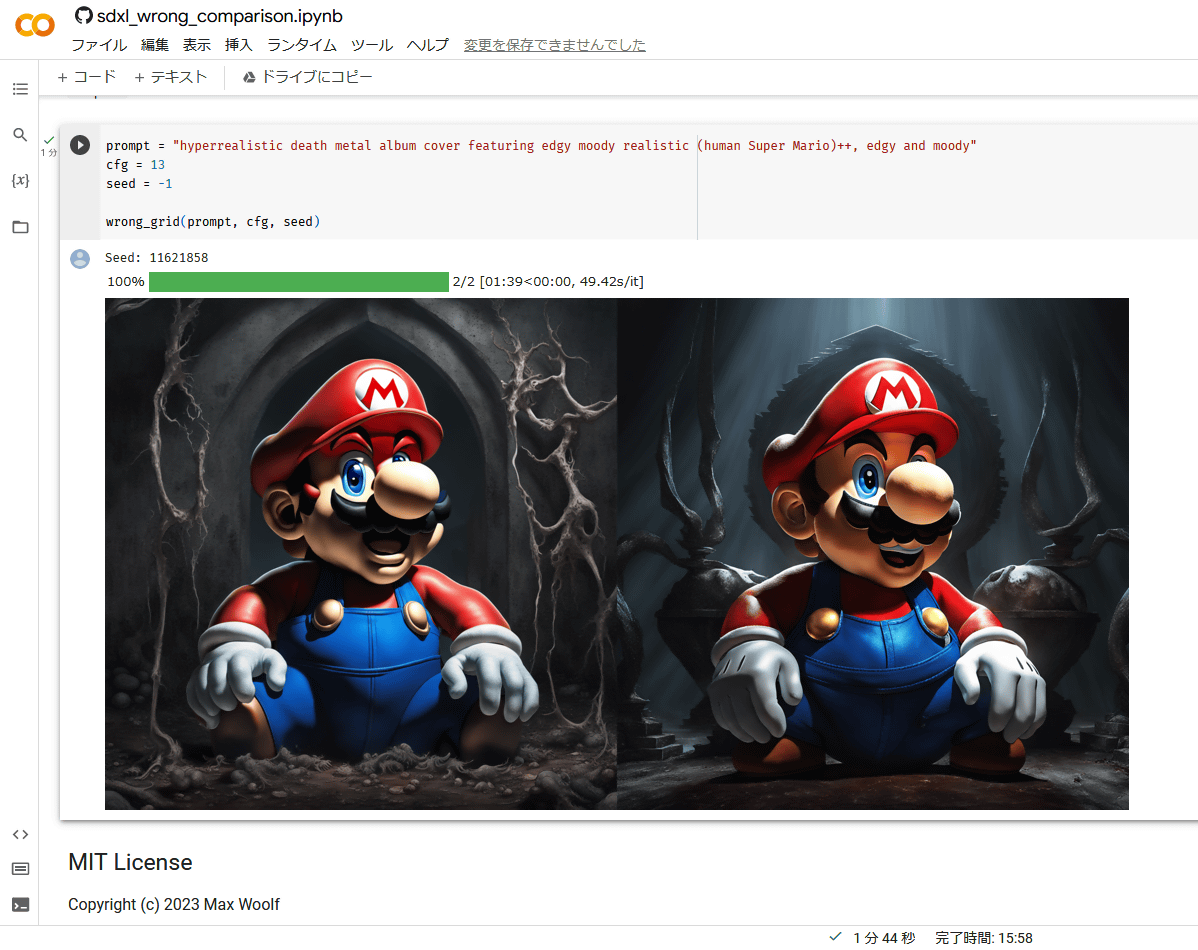
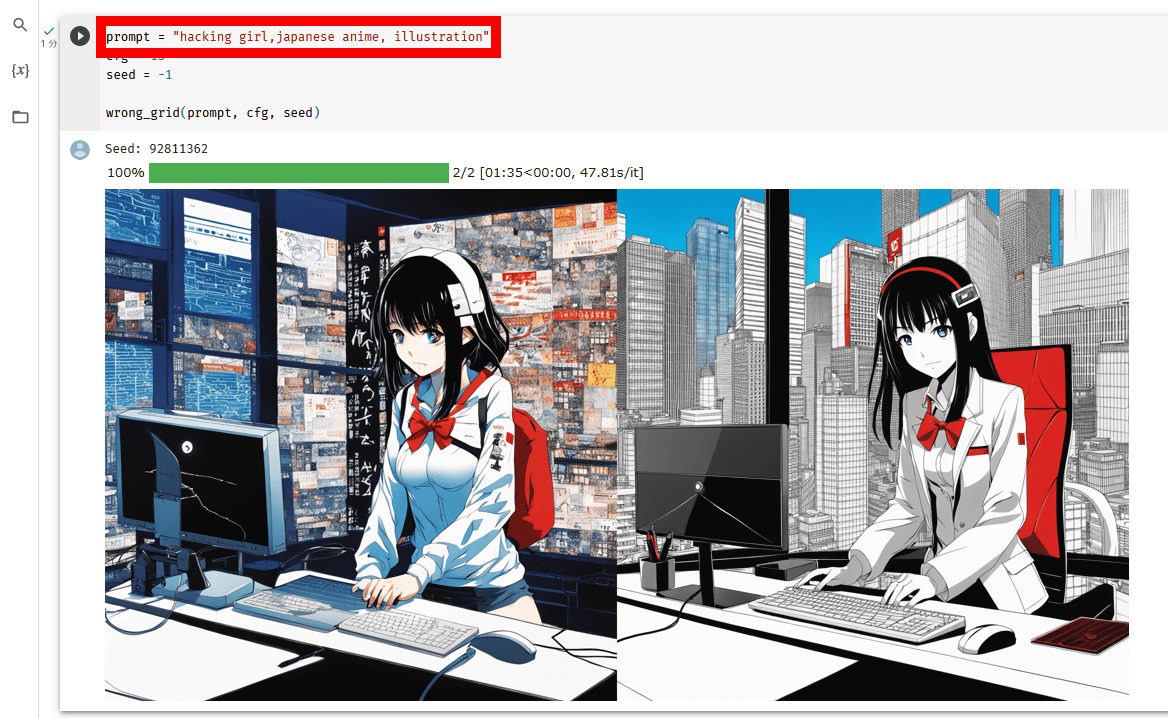
「prompt」と記された部分の中身を書き換えると、自分の好みのプロンプトで画像を生成できます。試しに「hacking girl, japanese anime, illustration」というプロンプトで生成した画像が以下。左側の画像では「背景がゴチャゴチャしていて何が描かれているのか分からない」「ディスプレイの形状が破綻している」といった問題が発生していますが、sdxl-wrong-loraを使った右側の画像では背景にスッキリした都会のビル群が描かれている他、ディスプレイの破綻も解消されています。
他にも画像を生成してみた結果、sdxl-wrong-loraを使った画像の方がおおむね高品質な画像が生成されました。

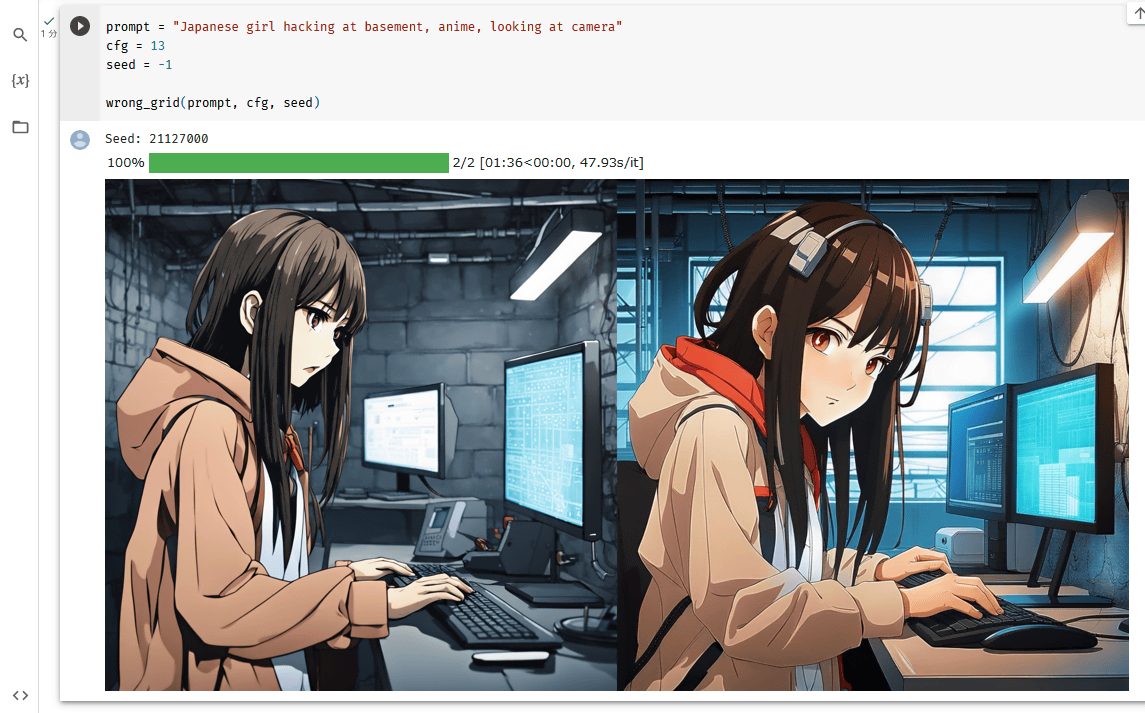
以下の画像のように構図が大きく変化する場合もありました。

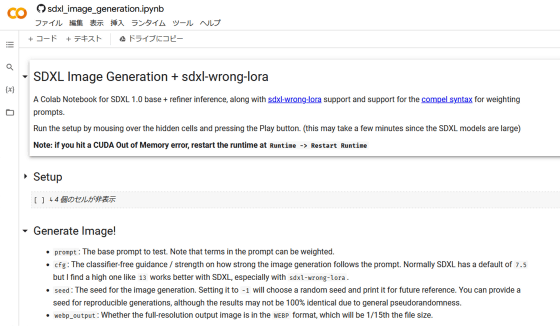
なお、以下のデモでは比較画像ではなくsdxl-wrong-loraを使った高品質な画像をのみを生成できます。
sdxl_image_generation.ipynb - Colaboratory
https://colab.research.google.com/github/minimaxir/sdxl-experiments/blob/main/sdxl_image_generation.ipynb
また、sdxl-wrong-loraは以下のリンク先で公開されています。
minimaxir/sdxl-wrong-lora · Hugging Face
https://huggingface.co/minimaxir/sdxl-wrong-lora
・関連記事
Stability AIが高性能画像生成モデル「SDXL 1.0」をリリース&すぐに使えるウェブアプリも公開されたので使ってみた - GIGAZINE
「描いたイラストをリアルタイムでAIに手直ししてもらえる環境」を「Stable Diffusion」と「Redream」の組み合わせで実現する方法まとめ、ControlNetも使って高品質な画像を生成可能 - GIGAZINE
画像生成AIによるイラスト学習をカラフルなウォーターマークで簡単に妨害できる「RGBWatermark」を使ってみた - GIGAZINE
ポーズや構図を指定してサクッと好みのイラスト画像を生成しまくれる「ControlNet」&「Stable Diffusion」の合わせ技を試してみたよレビュー - GIGAZINE
画像生成AIを始めたいけどグラボが高価で諦めている人に朗報、安価なAPUでも大容量なVRAMを割り当てて画像生成可能 - GIGAZINE
・関連コンテンツ



in ソフトウェア, レビュー, Posted by log1o_hf
You can read the machine translated English article A method of generating high-quality imag….