




Stability AIが高性能画像生成モデル「SDXL 1.0」をリリース&すぐに使えるウェブアプリも公開されたので使ってみた

画像生成AI「Stable Diffusion」の開発元であるStability AIが画像生成モデル「Stable Diffusion XL 1.0(SDXL 1.0)」を公開しました。SDXL 1.0は2023年6月に研究目的で公開された「SDXL 0.9」をさらに強化したもので、すでにモデルデータが公開されている他、SDXL 1.0をサクッと使えるウェブアプリも用意されています。加えて、AmazonのAIサービス「Amazon Bedrock」でSDXL 1.0のAPIが利用可能になることも発表されています。
ANNOUNCING SDXL 1.0 — Stability AI
https://stability.ai/blog/stable-diffusion-sdxl-1-announcement
Stability AI Announces Stable Diffusion XL 1.0, Featured on Amazon Bedrock — Stability AI
https://stability.ai/press-articles/stable-diffusion-xl-1-featured-amazon-aws-bedrock
AWS-Expands-Amazon-Bedrock-With-Additional-Foundation-Models-New-Model-Provider-and-Advanced-Capability-to-Help-Customers-Build-Generative-AI-Applications
https://press.aboutamazon.com/2023/7/aws-expands-amazon-bedrock-with-additional-foundation-models-new-model-provider-and-advanced-capability-to-help-customers-build-generative-ai-applications
SDXL 1.0は1024×1024ピクセルの画像を生成可能で、既存のモデルと比べて「光源と影の処理」などが改善している他、「手」や「3次元的な構図」といった画像生成AIが苦手とする画像も生成できるとのこと。

これまでの画像生成モデルでは生成画像の品質を高めるためにプロンプトに「masterpiece」といった単語を挿入するテクニックが用いられてきましたが、SDXL 1.0では「masterpiece」などの単語を含まずとも高品質な画像を生成できるとのこと。また、「The Red Square(赤の広場)」と「red square(赤い四角)」を区別するなど、プロンプトの理解力も向上しています。

SDXL 1.0のモデルデータはすでに公開されている他、AmazonのAIサービス「Amazon Bedrock」でSDXL 1.0のAPIが利用可能になることも発表されています。さらに、以下のリンク先ではSDXL 1.0を用いた画像生成を無料で実行可能とのことなので、実際に画像を生成してみました。
Clipdrop - Stable Diffusion
https://clipdrop.co/stable-diffusion
リンク先にアクセスすると以下の画面が表示されるので、入力欄にプロンプトを入力して「Generate」をクリック。今回は「A girl hacking in a cyberpunk city.(サイバーパンクな街並みでハッキングする女の子)」と入力しました。
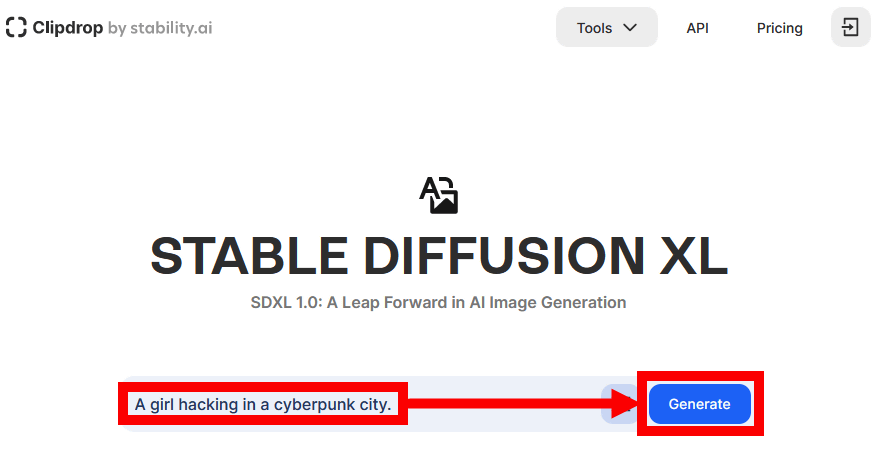
「有料プランに加入すると待ち時間を短縮できる」という通知が表示されますが、無料で使いたいので「Skip」をクリックしました。

しばらく待つと、プロンプトに応じた画像が4枚生成されます。画像をダウンロードするには、画面下部のサムネイルから好みの画像を選択して「Download」をクリックすればOK。
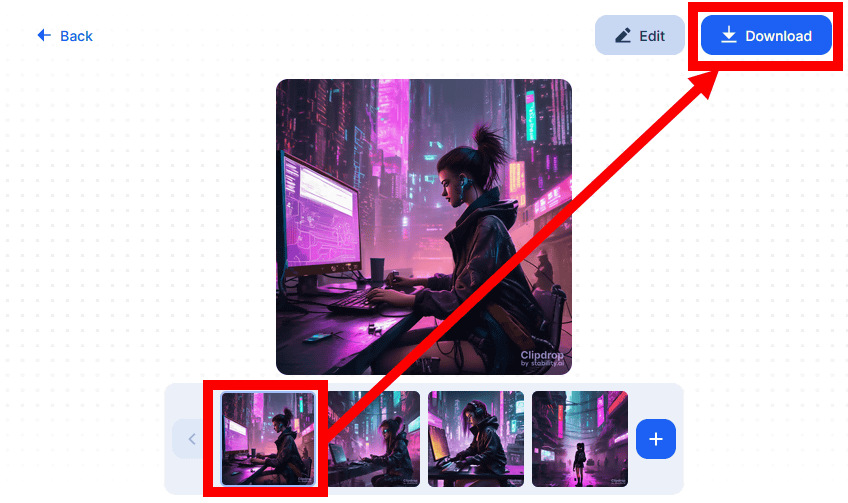
「A girl hacking in a cyberpunk city.」で生成された画像4枚はこんな感じ。短いプロンプトでも高品質な画像を生成できました。




続いて「Eating sushi with bare hands. Close-up of the face.(素手で寿司を食べる。顔をアップで)」というプロンプトで画像を4枚生成してみました。Stability AIは「手」の描写が向上したとアピールしていますが、まだ手を自然に描くのは難しいようです。




最後に「Suited panda dances in front of Mt Fuji.(スーツを着たパンダが富士山の前で踊っている)」というプロンプトで生成した画像が以下。全裸パンダが1枚生成されましたが、「パンダが富士山の前で踊る」という要素はどの画像でも正確に表現されています。




なお、SDXL 1.0のモデルデータの配布場所は以下のGitHubリポジトリにまとめられています。
GitHub - Stability-AI/generative-models: Generative Models by Stability AI
https://github.com/Stability-AI/generative-models
・関連記事
画像生成AI「Stable Diffusion」の高性能モデル「SDXL 0.9」をStability AIが発表、画像と構図のディテールが大幅に改善 - GIGAZINE
従来のStable Diffusionより大幅に強化された画像生成AI「Stable Diffusion XL」のベータ版がテスト公開されたので使ってみた - GIGAZINE
画像生成AIのStable Diffusionをインストール不要でブラウザから動作可能な「Web Stable Difusion」が登場 - GIGAZINE
画像生成AI「Stable Diffusion」でスマホでもわずか1枚2秒という爆速で画像生成ができる「SnapFusion」 - GIGAZINE
Stable Diffusionの改良版「Stable Diffusion XL(SDXL)」の技術レポートが公開 - GIGAZINE
・関連コンテンツ




in ソフトウェア, レビュー, ウェブアプリ, Posted by log1o_hf
You can read the machine translated English article Stability AI released a high-performance….