




コントローラーのドリフト現象を診断できるウェブアプリ「ControllerTest.io」

PlayStationやNintendo Switchなどのゲーム機のコントローラーを長期間使い続けると、アナログスティックに触れていないのに勝手に動いたと判定される「ドリフト現象」が発生することがあります。そんなドリフト現象が発生しているか否かを可視化できるウェブアプリが「ControllerTest.io」で、PCにコントローラーを接続して自分のアナログスティックの状態を診断することができます。
ゲームパッドテスター - コントローラーテスト & ドリフト診断オンライン
https://controllertest.io/ja/
上記のリンクをクリックしてControllerTest.ioにアクセス。
コントローラーをPCにUSB接続します。今回はPlayStation 5の純正コントローラーであるDualSenseを接続しました。

続いて、何でもいいのでボタンを1個押します。

すると、コントローラーが接続されて画面内にコントローラー名が表示されました。イラスト部分は変化していないですが、ドリフト診断には影響ないのでOKです。
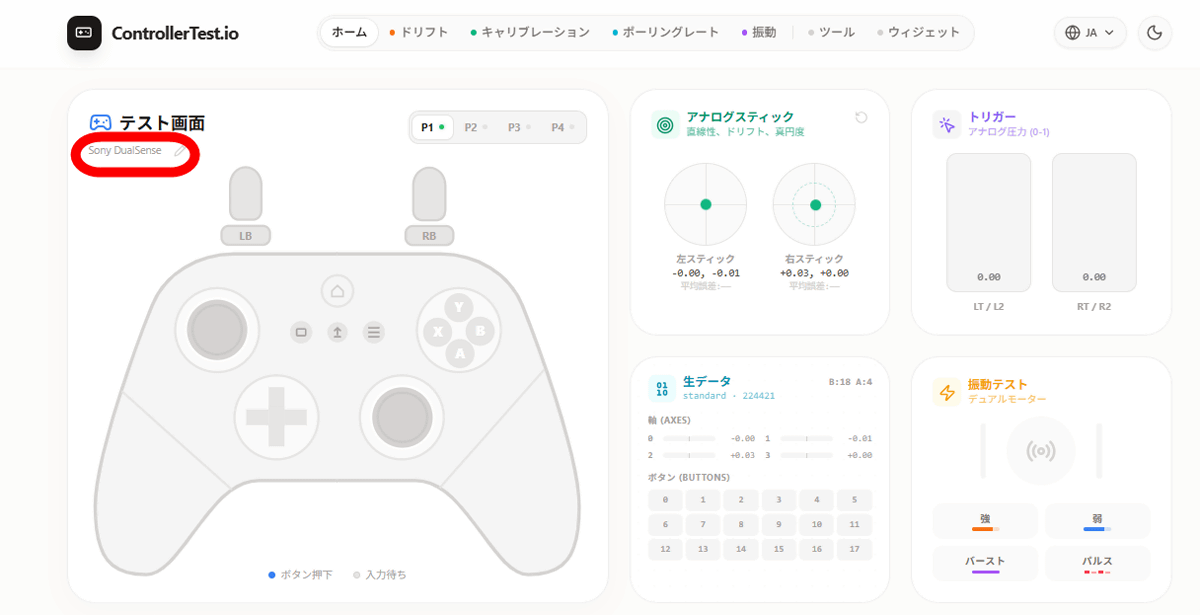
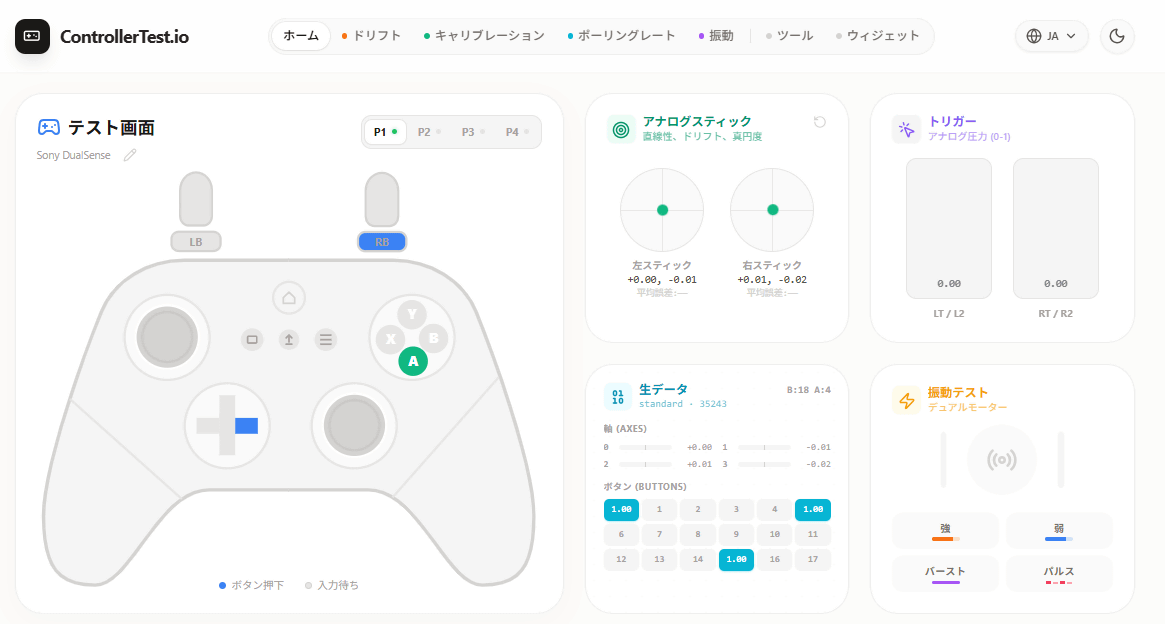
コントローラーの各ボタンを押すと、対応する部分に色がつきます。
ドリフト診断をするには、画面上部の「ドリフト」をクリックしてから右下の「静的検出を開始」をクリック。
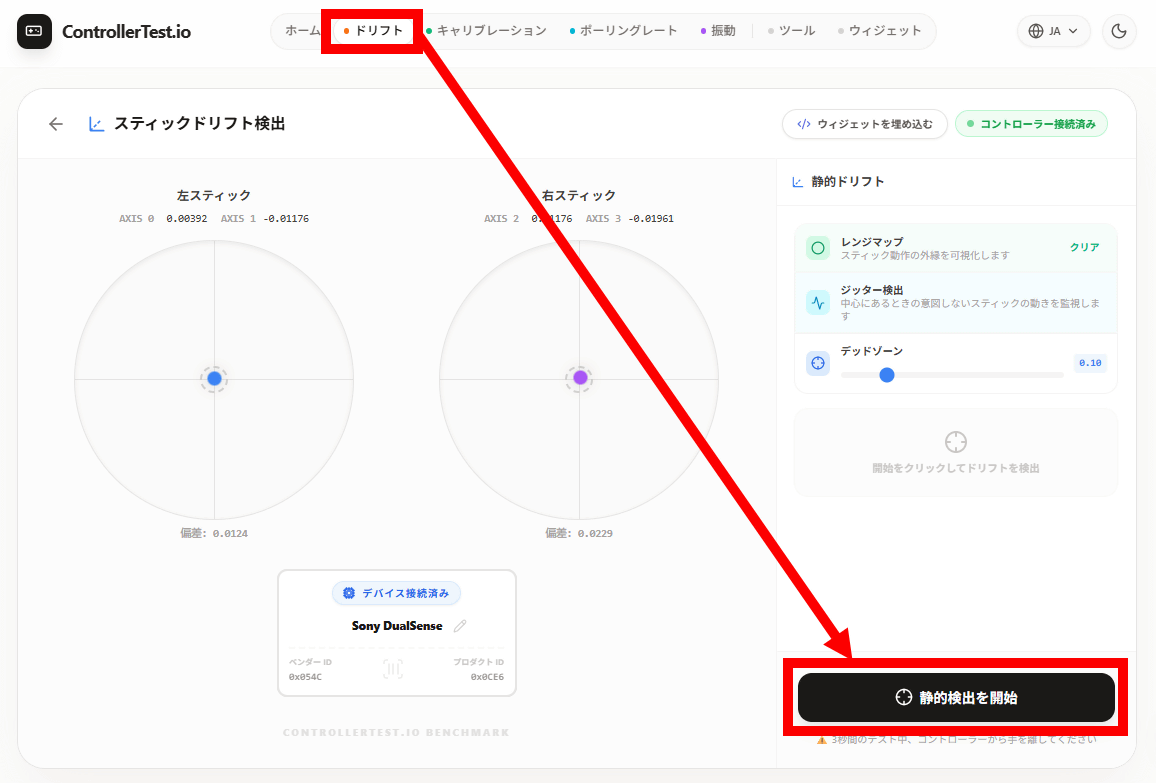
コントローラーに触らずに3秒待つと診断結果が表示されます。今回は「正常」でした。こんな感じに、自分のコントローラーが正常なのか否かをすぐに確認できます。
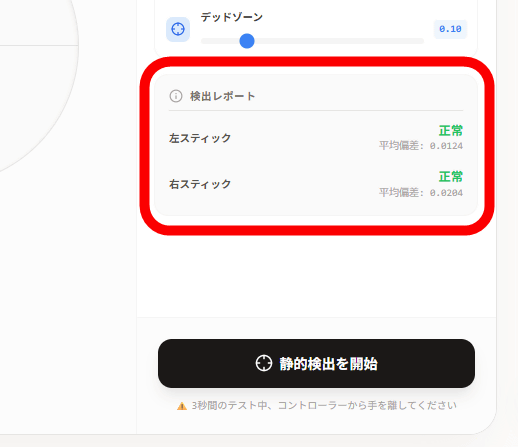
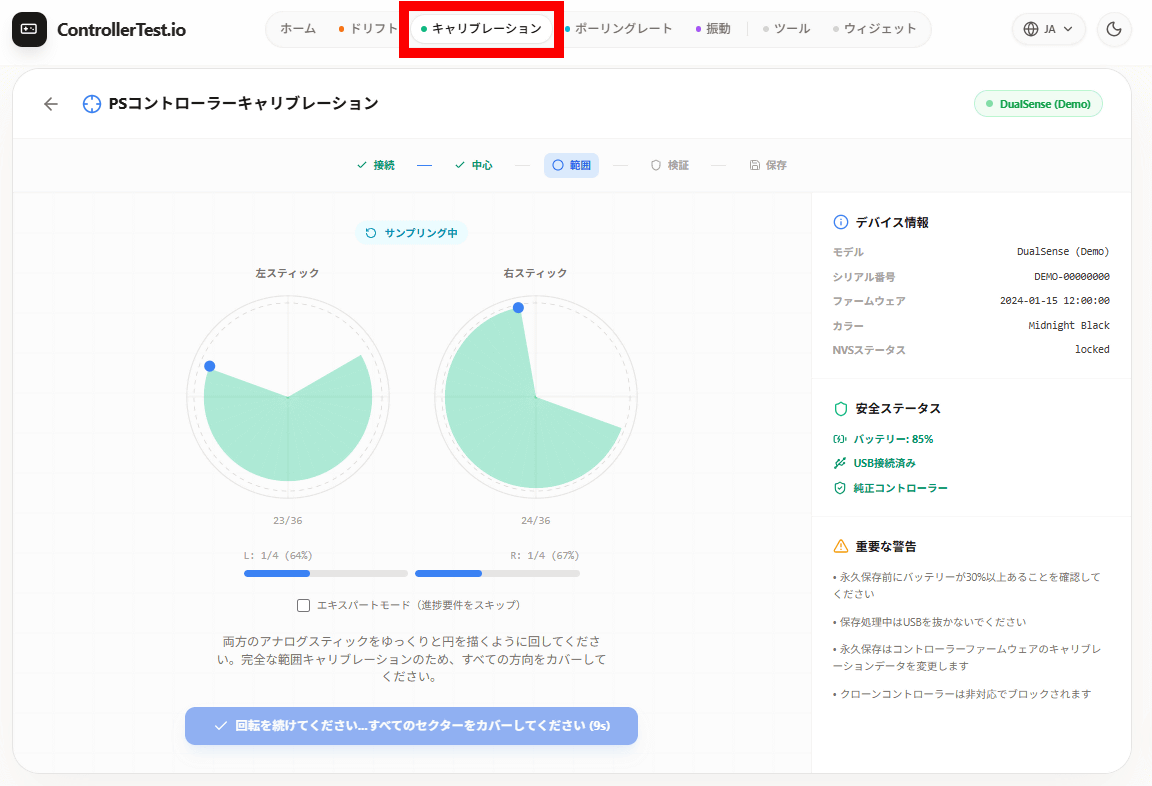
ControllerTest.ioにはキャリブレーション機能も搭載されています。ただし、ControllerTest.ioはSIEや任天堂とは無関係のサイトなので、実行する際は注意してください。
・関連記事
Nintendo Switch 2「マリオカートワールド」でお役立ちな「Joy-Con 2 ハンドル」や背面ボタンが追加された「Nintendo Switch 2 Proコントローラー」などNintendo Switch 2のコントローラーを触ってみた - GIGAZINE
Steam製ゲームコントローラー「Steam Controller」が登場、磁気スティック&トラックパッド搭載だがSteam以外のゲームで難ありとの声も - GIGAZINE
PS4やPS5の純正コントローラーのドリフト現象を改善できるウェブアプリ「Dualshock Calibration GUI」 - GIGAZINE
スマホや低スペックPCでも重量級PCゲームをリモートプレイできる「Steam Link」レビュー - GIGAZINE
・関連コンテンツ





in ハードウェア, レビュー, ゲーム, ウェブアプリ, Posted by log1o_hf
You can read the machine translated English article ControllerTest.io is a web application t….