




テスラが最大362TFLOPSのASIC「D1」を搭載するAIトレーニング用スパコン「Dojo」を発表

電気自動車による自動運転システムを開発するテスラが、AIについての発表イベント「AI Day」で、AI学習用のカスタムASIC(特定用途向け集積回路)である「D1」を発表しました。このASICはテスラが開発中のスーパーコンピューターである「Dojo」に組み込まれ、2022年に稼働を開始する予定です。
Tesla AI Day presentation streaming live from https://t.co/shRnZSwgd4 at 5pm Pacific today
— Tesla (@Tesla) August 19, 2021
Tesla unveils Dojo D1 chip at AI Day
https://www.cnbc.com/2021/08/19/tesla-unveils-dojo-d1-chip-at-ai-day.html
Tesla Packs 50 Billion Transistors Onto D1 Dojo Chip Designed to Conquer Artificial Intelligence Training | Tom's Hardware
https://www.tomshardware.com/news/tesla-d1-ai-chip
テスラは100万台以上の車両から大量の映像データを取得しており、この映像データから自動運転AIのトレーニングを行っています。テスラのイーロン・マスクCEOは以前から「レーダーやセンサーよりも映像認識の方が自動運転に適している」と主張しており、自動運転AIの映像認識トレーニングに最適化したスーパーコンピューターを自社で開発する予定だと述べていました。
Sensors are a bitstream and cameras have several orders of magnitude more bits/sec than radar (or lidar).
— Elon Musk (@elonmusk) April 10, 2021
Radar must meaningfully increase signal/noise of bitstream to be worth complexity of integrating it.
As vision processing gets better, it just leaves radar far behind.
これまでテスラ開発のスーパーコンピューターについては具体的な情報は公開されていませんでしたが、テスラはAI Dayで初めてスーパーコンピューター「Dojo」について明らかにしました。Dojoは大規模なコンピュートプレーンを持ち、低遅延かつ超高帯域幅を備えた分散型コンピューターアーキテクチャです。
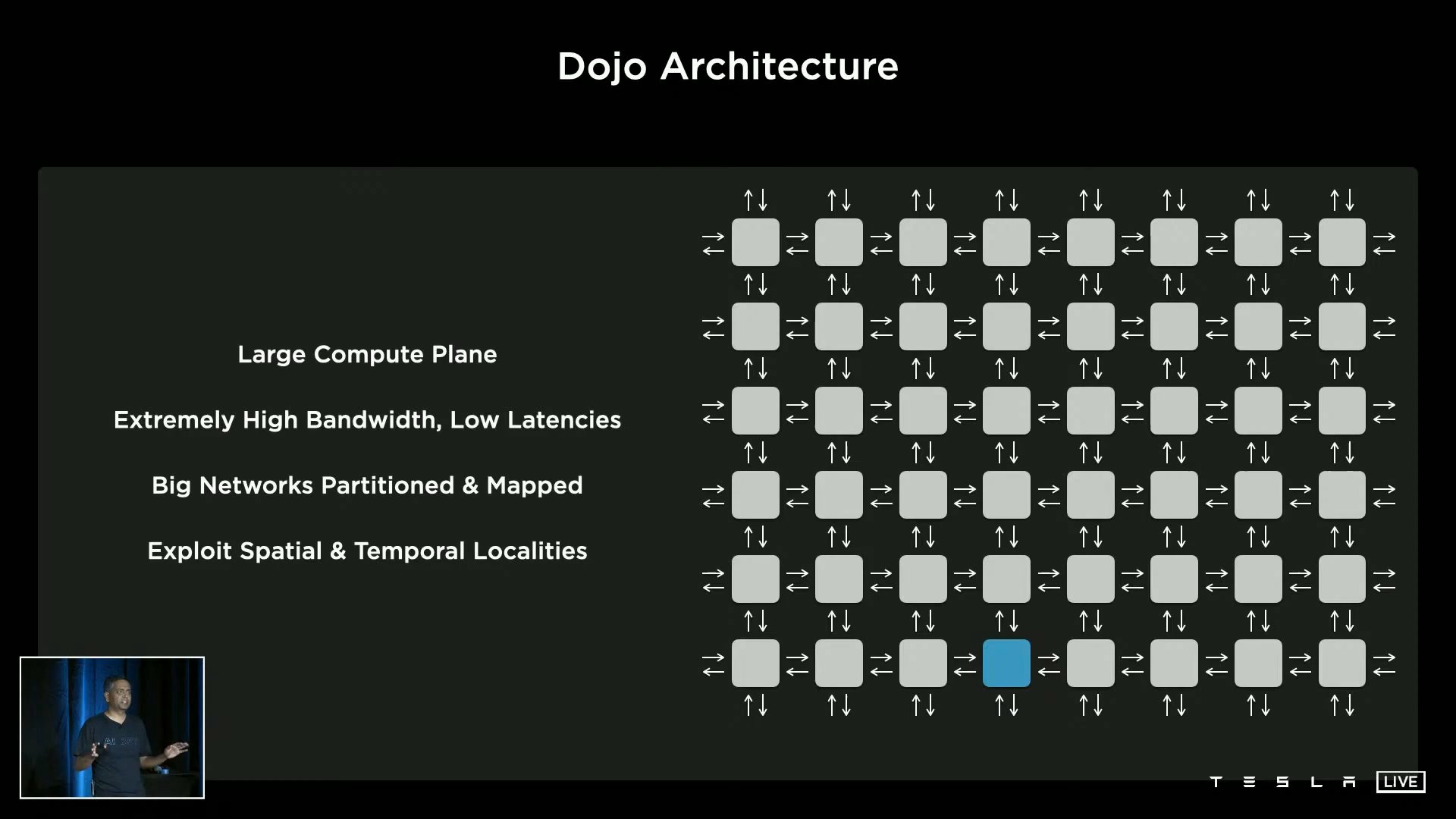
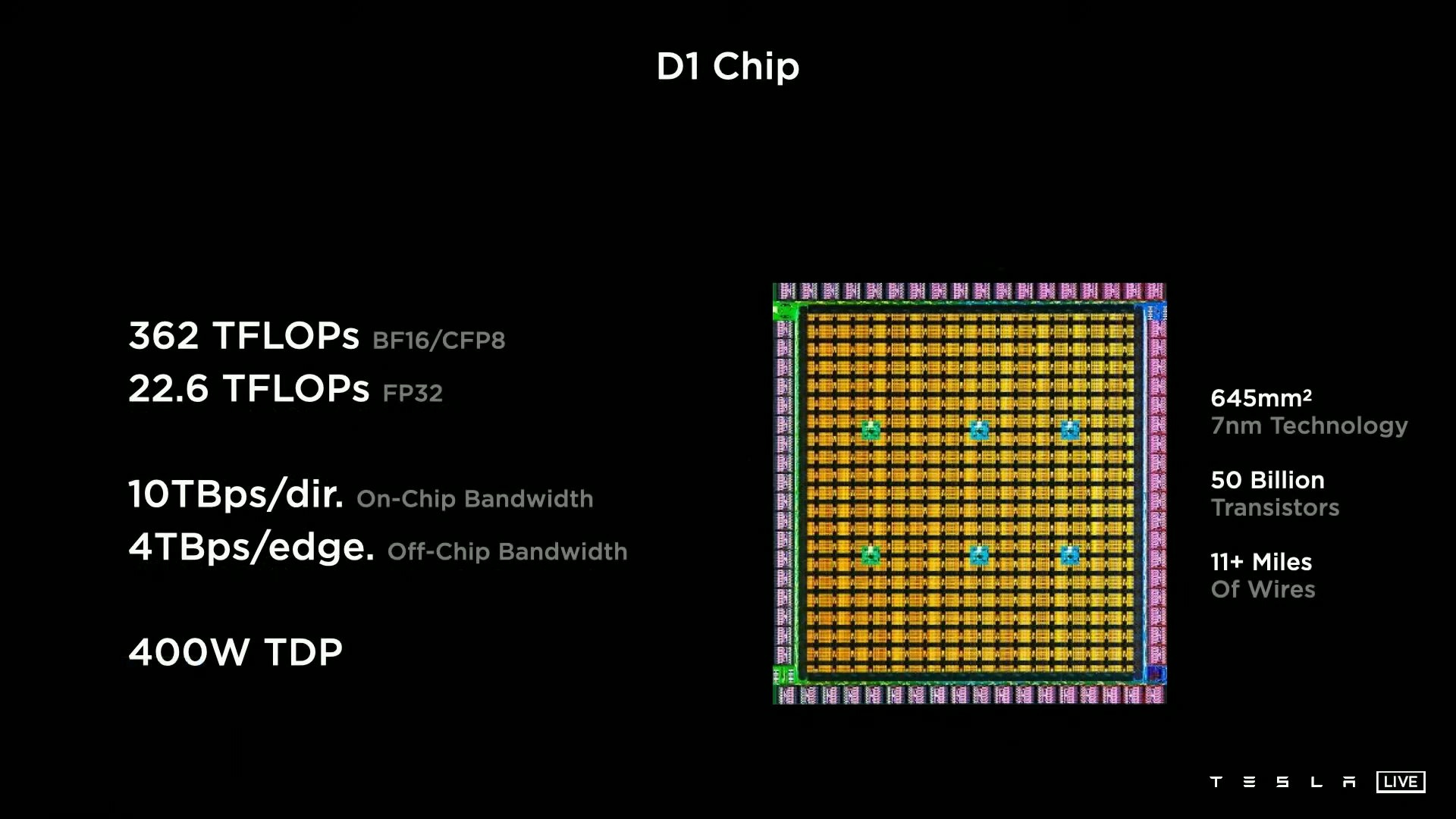
さらにテスラは、このDojoを構成するASIC「D1」の詳細を明らかにしました。

D1は、機械学習における帯域幅のボトルネックを取り除くために自社設計されており、プロセスノードはTSMCの7nmが採用されているとのこと。D1のダイ面積は645mm2で、トランジスタ数は500億以上。TDP(熱設計電力)400Wで単精度(FP32)での浮動小数点数性能は22.6TFLOPS、bfloat16(BF16)形式やCFP8形式だと最大362TFLOPSになるとテスラは述べています。
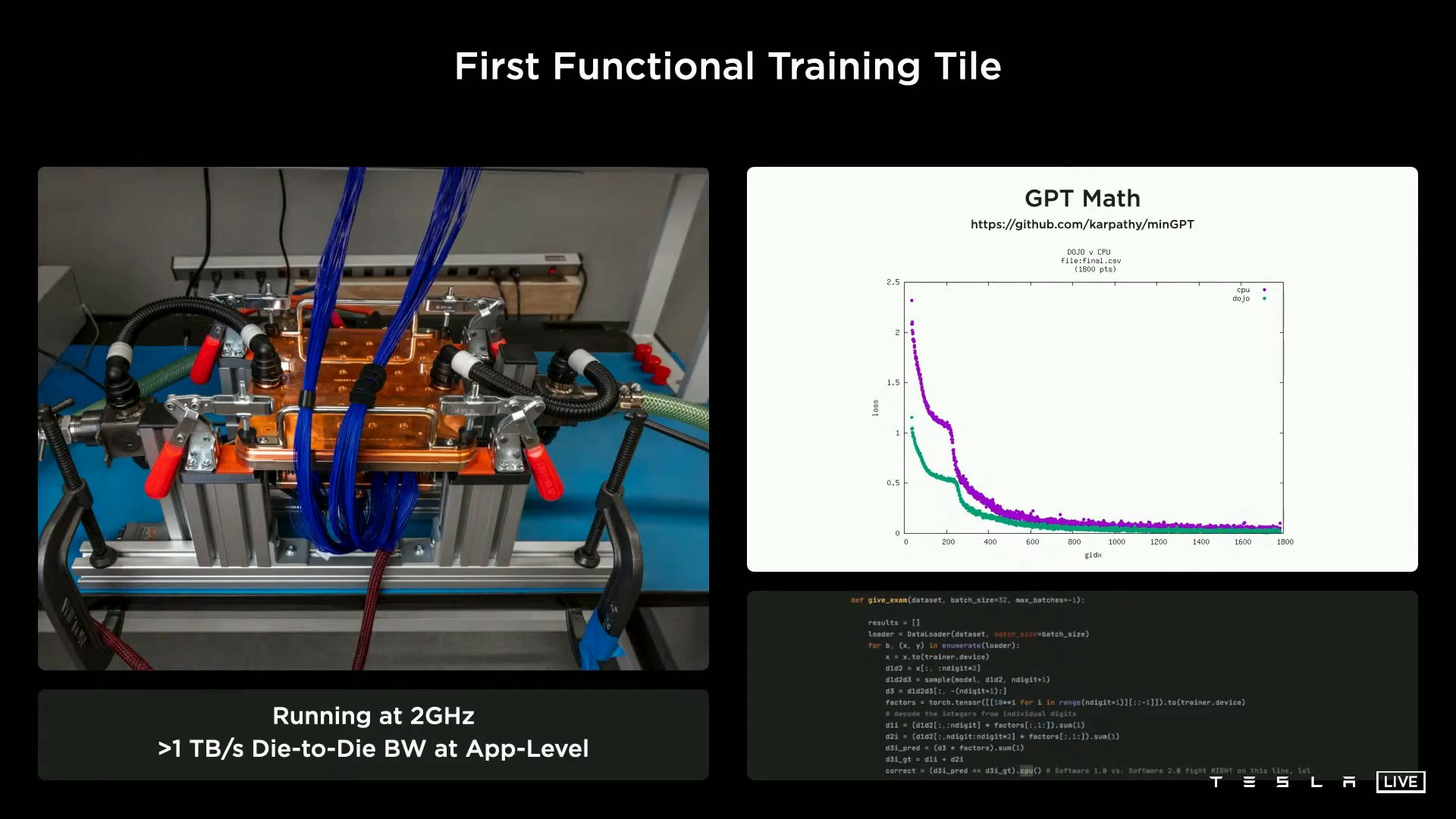
このD1を25基集積したマルチチップモジュール「トレーニングタイル」は、BF16・CFP8で9P(ペタ)FLOPS、オフタイル帯域幅が最大36TBpsになるそうです。


ただし、Dojoはまだ未完成で完全実用化の段階に至っていないそうで、テスラの自動運転ハードウェア担当上級ディレクター兼プロジェクトDojoのリーダーであるGanesh Venkataramanan氏によれば、2021年8月に最初のトレーニングタイルが納入され、テストが行われたばかりだとのこと。
テスラは、6つのトレーニングタイルをつなげたラックを2段載せることで1つのキャビネットに100PFLOPSの計算能力を持たせ、そのキャビネットを10台接続することで1.1E(エクサ)FLOPSの演算が可能なスーパーコンピューターを構築することが可能だと主張。イーロン・マスクCEOは、Dojoは2022年には稼働するだろうと述べています。

なお、テスラのAI Dayは以下のムービーで視聴可能。Dojoについての発表は1時間45分40秒あたりから始まります。
Tesla AI Day - YouTube

・関連記事
NVIDIAの低消費電力&超高性能なスーパーコンピューター「Cambridge-1」が正式稼働 - GIGAZINE
データセンター向けGPU「NVIDIA A100」を6159基搭載したスパコン「Perlmutter」が稼働、宇宙の謎「ダークエネルギー」解析などが任務 - GIGAZINE
機械学習に特化した第4世代プロセッサ「TPU v4」をGoogleが発表、前世代の2倍以上のパフォーマンスに - GIGAZINE
NVIDIAが初のデータセンター向けCPU「Grace」を発表、Armベースで従来のシステムより10倍高速 - GIGAZINE
日本のスパコン「富岳」が4つの世界ランキングで2期連続1位に輝く - GIGAZINE
700ペタFLOPSのAIスーパーコンピュータをNVIDIAとフロリダ大学が共同開発すると発表 - GIGAZINE
・関連コンテンツ








in 動画, ハードウェア, Posted by log1i_yk
You can read the machine translated English article Tesla announces AI training supercompute….