




1億7000万円ものコストダウンを機械学習で達成したDropbox、一体どんな方法を取ったのか?

Dropboxが自社サービス上の「ファイルプレビュー機能」を機械学習で効率化することで、170万ドル(約1億7000万円)の費用削減を達成しました。具体的なシステムの内容について、機械学習エンジニアのWin Suen氏が説明しています。
Cannes: How ML saves us $1.7M a year on document previews - Dropbox
https://dropbox.tech/machine-learning/cannes--how-ml-saves-us--1-7m-a-year-on-document-previews
Dropboxはアップロードされたファイルを素早くプレビューするため、「Riviera」という内部システムを利用して事前にファイルのプレビューデータを生成しているとSuen氏は説明。しかし、事前に生成したデータが利用されず無駄になるケースもあったため、機械学習で事前生成すべきデータを予測し、データ生成時のマシンリソースを節約するプロジェクト「Cannes」が発足することになりました。
Cannesの開発にあたり、チームが重要視したのは「予測が外れた場合のパフォーマンス低下の許容範囲」と「機械学習モデルのシンプルさ」だったとSuen氏。前者はプレビュー表示チームと協力することで許容範囲を線引きし、その線引きを機械学習の精度目標にしたそうです。また、後者についてはなるべく機械学習モデルをシンプルにすることで、「なぜその予測結果が生まれたか」を明確にし、導入初期におけるデバッグを容易にする狙いがあったとSuen氏は語っています。
機械学習モデルの構築には、「ファイルの拡張子」や「保存しているファイルの種類に基づくアカウントの区分」、そして「直近30日間におけるアカウント利用状況」を入力データとした勾配ブースティングが採用されました。この手法によって構築した「Cannes v1」は精度目標を達成し、約1億7000万円の費用削減効果が試算されたとのこと。本番環境のトラフィックを利用したA/Bテストなどを経て、プレビュー応答速度の悪化が許容範囲内であることを実際に確認した開発チームは、Cannesをシステムに導入することにしました。
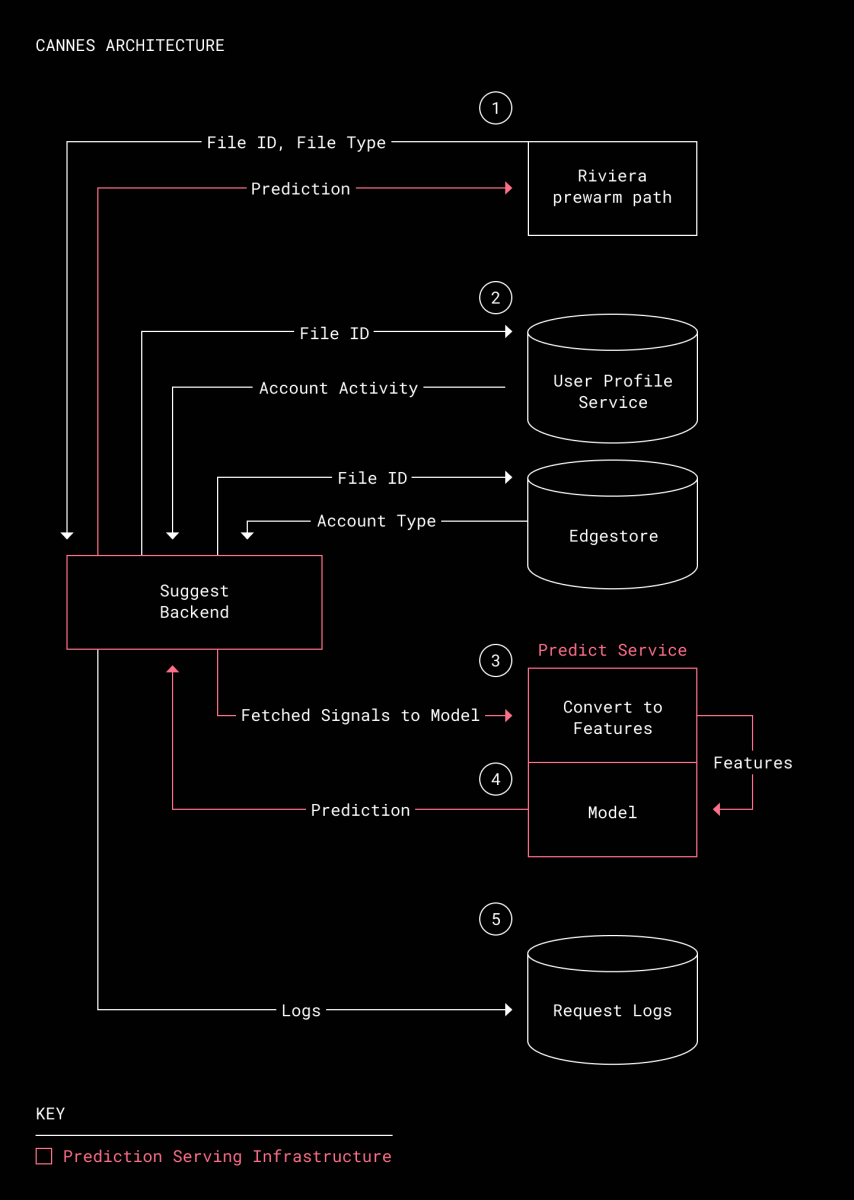
以下の画像はプレビューシステムの全体像を表したもので、ピンク色でハイライトされている部分がCannesにあたります。プレビューデータ生成を担うRivieraは、まずプレビューデータを事前生成する対象のファイルIDやタイプをCannesに送信。CannesはファイルIDをもとに、外部のデータベースからアカウントのタイプや利用状況を収集します。収集したデータは特徴量を表すベクトルに変換された後、機械学習モデルに投入され、モデルは特徴量から「向こう60日間でファイルのプレビューが行われるか」を予測。予測結果はRivieraに送信されるとともに、デバッグ用に特徴量とあわせてログとしても保存される仕組みとなっています。
記事作成時点では、CannesはDropbox上のほぼすべてのトラフィックに適用されており、開発チームはプレビューデータの事前生成にかかる年間コストを試算通り、約1億7000万円も削減。Cannesの運用にかかる費用は年間9000ドル(約90万円)であるため、非常に大きなコストカットを達成できていることがわかります。開発チームは今後、より複雑なモデルを実験して予測精度の向上を目指すほか、特徴量に対する重みを再学習させ、モデルを微調整する「ファインチューニング」を行う予定だそうです。
・関連記事
Dropboxが同期エンジンを全面的に改良、新エンジンはどこが改善されているのか? - GIGAZINE
Dropboxが新開発した「非同期処理フレームワーク」はどのように構築されているのか? - GIGAZINE
ディープラーニングの手法「CNN」の画像識別処理がアニメーションで理解できる「CNN Explainer」 - GIGAZINE
機械学習の「Q学習」にベイズ推定を取り入れると一体何が起こるのか? - GIGAZINE
機械学習のアルゴリズムはドーパミン神経によって脳にも実装されていることが判明 - GIGAZINE
・関連コンテンツ






in ソフトウェア, ネットサービス, Posted by darkhorse_log
You can read the machine translated English article What kind of method did Dropbox take, wh….